Spring Cloud Zuul 概览
什么是API网关
网关这个词其实是一个硬件概念。因为按照定义,网络网关出现在网络的边缘,所以防火墙和代理服务器等相关功能 往往与之集成在一起。在家庭网络 和小型企业中,宽带路由器通常充当网络网关。它将你家中或企业的设备与 Internet 连接。网关是路由器的最重要功能,路由器是最常见的网关类型。
今天我们要讲的网关并非是路由器(开个玩笑),既然做应用开发自然讨论的是调用各个服务的入口-API,所有服务的入口,简称API网关。
在大多数微服务实现中,内部微服务端点不会暴露在外部。它们被保留为私人服务。一组公共服务将使用API网关向客户端公开。这样做有很多原因:
- 客户端仅需要一组选定的微服务;
- 很难在服务端点上实现特定于客户端的转换;
- 如果需要数据聚合,尤其是为了避免在带宽受限的环境中进行多个客户端调用,则中间需要网关;
- 服务实例数量及其位置(主机+端口)动态变化;
- 如果要应用特定于客户的策略,则很容易将它们应用于单个位置,而不是多个位置。这种情况的一个示例是跨域访问策略。
使用网关的好处:
- 客户端与网关后面的微服务架构分区是隔离的;
- 客户不必担心特定服务的位置;
- 如果要应用特定于客户的策略,则很容易将它们应用于单个位置,而不是多个位置。这种情况的一个示例是跨域访问策略;
- 为每个客户端提供最佳的API;
- 减少请求/往返次数;
- 通过将聚合逻辑移至API网关来简化客户端。
缺点:
- 复杂性增加 API 网关是微服务体系结构中要管理的又一动态部分;
- 与通过直接调用相比,响应时间增加了,因为通过API网关进行了额外的网络跳跃;
- 在聚合层中实施过多逻辑的危险。
另外,在微服务体系下,被拆分的各个子服务对外是单一功能的服务,是整体构架布局下的单一功能,那么对外提供的各个接口提供的地址必须是相同的,比如一个用户中心的服务,所有的接口都应该在api.userCenter.com下面:
https://api.userCenter.com/user/getUser
https://api.userCenter.com/dept/get
而不能一会在api.userCenter.com,一会又跑到别的地址下面,如果地址不一样,那就应该是两个服务,而不是一个。
所以网关的核心作用是:统一接口路由。
网关存在的意义是为了提供服务,那么身为一个网关,它所应该具有的能力有哪些呢?
1.接收请求:网关最终的能力就是接收请求,然后将请求转发出去;那么首先它就要有MVC的能力,则它需要实现servlet;
2.发出请求:网关需要将请求转发到其他服务,那么它就要有发送请求的能力,则它需要实现Http相关方法;
3.过滤请求:网关提供对请求的权限、日志等操作,那么他就要有过滤请求的能力,则它需要实现filter;
4.获取服务列表:网关提供路由功能,那么它就需要获取到路由地址,从微服务的架构设置来看,即它需要从注册中心拿到服务列表;
5.路由配置:网关实现路由操作,那么就需要设置请求路径与服务的对应关系;
Zuul
Spring Cloud Zuul 主要的功能是提供负载均衡、反向代理、权限认证、动态路由、监控、弹性、安全等的边缘服务。其主要作用是为微服务架构提供了前门保护的作用,同时将权限控制这些较重的非业务逻辑内容迁移到服务路由层面,使得服务集群主体能够具备更高的可复用性和可测试性。
没有Netflix Zuul的微服务呼叫:

与Netflix Zuul进行微服务通话:
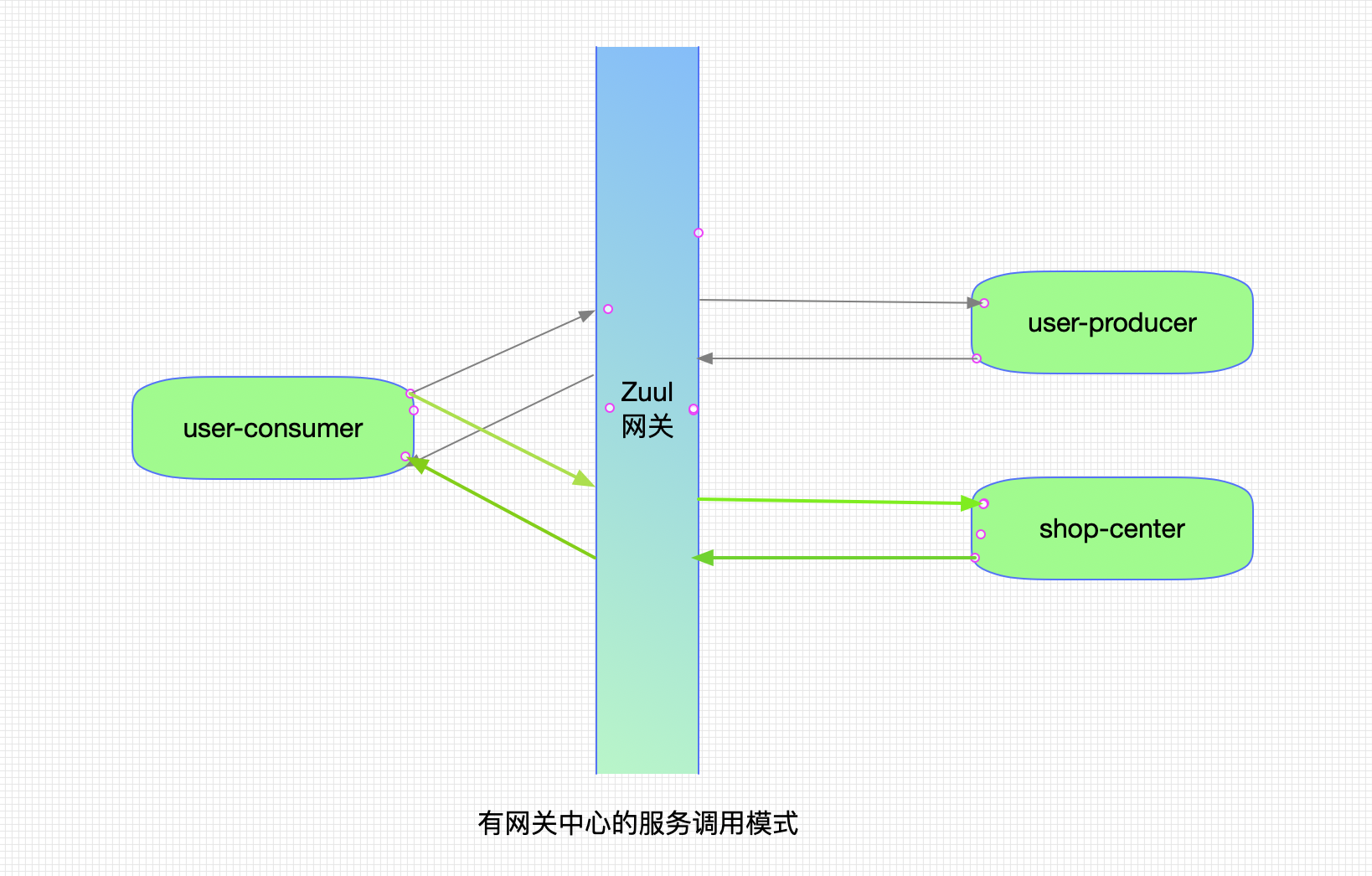
使用Netflix Zuul + Netflix Eureka进行微服务呼叫:

搭建Zuul网关示例
基于前面我们已经搭建的 Eureka 和 Feign调用工程示例:https://github.com/rickiyang/SpringCloud-learn,我们继续搭建 Zuul 网关中心。
在pom文件中新增 Zuul 配置:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-zuul</artifactId>
</dependency>
整体配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.rickiyang.learn</groupId>
<artifactId>springcloud-learn</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<groupId>com.rickiyang.learn</groupId>
<artifactId>zuul-server</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>zuul-server</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-cloud.version>Greenwich.RELEASE</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-zuul</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
启动类加上开启 Zuul 的注解:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.netflix.zuul.EnableZuulProxy;
@EnableDiscoveryClient
@EnableZuulProxy
@SpringBootApplication
public class ZuulServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZuulServerApplication.class, args);
}
}
配置文件添加Eureka的配置属性:
server:
port: 8767
spring:
application:
name: zuul-server
main:
allow-bean-definition-overriding: true
eureka:
client:
service-url:
defaultZone : http://localhost:8761/eureka/,http://localhost:8762/eureka/,http://localhost:8763/eureka/
instance:
lease-renewal-interval-in-seconds: 2 # 设置心跳的时间间隔(默认是30秒)
lease-expiration-duration-in-seconds: 5 # 如果现在超过了5秒的间隔(默认是90秒)
prefer-ip-address: true # 访问的路径变为IP地址
这样一个api网关就简单的搭建好了。食用方式:先启动Eureka-server,接着启动Eureka-client,最后启动zuul-server。
首先验证一下 Eureka-client 接口是否可用:
http://localhost:8766/hello/xiaoming
可用的情况下再来使用Zuul调用,网关 zuul 默认转发地址是:
http://网关IP:网关端口/被转发的服务application.name/要访问的接口,
本示例中就是:
http://localhost:8767/eureka-client/hello/xiaoming
如果我们觉得服务名:eureka-client 太长了,或者是不想暴露服务名,想用简洁的字段来替代,可以用如下配置:
zuul:
routes:
eureka-client:
path: /client1/**
serviceId: eureka-client
那么访问服务的url就变为:
http://localhost:8767/client1/hello/xiaoming
这样替换之后,如果该路径中有一些url已经被业务方调用,无法替换,那么需要把这些url排除:
zuul:
#所有服务路径前统一加上前缀
prefix: /api
# 排除某些路由, 支持正则表达式
ignored-patterns:
- /**/modify/pwd
# 排除服务
ignored-services: user-center
routes:
eureka-client:
path: /client1/**
serviceId: eureka-client
Zuul默认使用 Apache 的 HttpClient 作为HTTP客户端发送请求,超时参数和连接池参数配置如下:
zuul:
host:
maxTotalConnections: 200 #连接池最大连接数,仅用于Apache的HttpClient,对于okhttp和restclient无效
maxPerRouteConnections: 20 #每个路由最大连接数,仅用于Apache的HttpClient,对于okhttp和restclient无效
Zuul完全没有开启重试,如果需要开启重试,添加配置:zuul.retryable=true,并且pom.xml添加如下依赖:
<dependency>
<groupId>org.springframework.retry</groupId>
<artifactId>spring-retry</artifactId>
</dependency>
PS:如果配置了zuul.retryable = true,但没有添加spring-retry到项目中,重试不会开启,反之亦然,必须要两个条件都满足才会开启重试。
PS:重试操作需要服务提供者保证幂等性,相同操作的多次请求需保证结果一致。
Zuul在开启了重试的情况下,重试参数配置如下(替换值):
ribbon:
MaxAutoRetries: 0 #当前服务器最大重试次数,不包含第1次请求
MaxAutoRetriesNextServer: 1 #切换服务器最大次数,不包含第1台服务器
OkToRetryOnAllOperations: false #是否所有操作都要重试,false:只有GET请求才会重试,true:GET、POST、PUT等所有请求都会重试
自定义 Filter
网关最核心的功能当然是集中式路由转发,那么在转发过程中对请求做一些鉴别和限制就是网关提供的高级功能也是必要的功能。
我们假设有这样一个场景,因为服务网关应对的是外部的所有请求,为了避免产生安全隐患,我们需要对请求做一定的限制,比如请求中含有 token 便让请求继续往下走,如果请求不带 token 就直接返回并给出提示。
首先自定义一个 Filter,继承 ZuulFilter 抽象类,在 run () 方法中验证参数是否含有 token ,具体如下:
package com.rickiyang.learn.filter;
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
import javax.servlet.http.HttpServletRequest;
/**
* @author rickiyang
* @date 2019-12-13
* @Desc TODO
*/
public class TokenFilter extends ZuulFilter {
/**
* 过滤器的类型,它决定过滤器在请求的哪个生命周期中执行。
* 这里定义为pre,代表会在请求被路由之前执行。
*
* @return
*/
@Override
public String filterType() {
return "pre";
}
/**
* filter执行顺序,通过数字指定。
* 数字越大,优先级越低。
*
* @return
*/
@Override
public int filterOrder() {
return 0;
}
/**
* 判断该过滤器是否需要被执行。这里我们直接返回了true,因此该过滤器对所有请求都会生效。
* 实际运用中我们可以利用该函数来指定过滤器的有效范围。
*
* @return
*/
@Override
public boolean shouldFilter() {
return true;
}
/**
* 过滤器的具体逻辑
*
* @return
*/
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
String token = request.getParameter("token");
if (token == null || token.isEmpty()) {
ctx.setSendZuulResponse(false);
ctx.setResponseStatusCode(401);
ctx.setResponseBody("token is empty");
}
return null;
}
}
在上面实现的过滤器代码中,我们通过继承 ZuulFilter 抽象类并重写了下面的四个方法来实现自定义的过滤器。这四个方法分别定义了:
filterType():过滤器的类型,它决定过滤器在请求的哪个生命周期中执行。这里定义为pre,代表会在请求被路由之前执行。filterOrder():过滤器的执行顺序。当请求在一个阶段中存在多个过滤器时,需要根据该方法返回的值来依次执行。通过数字指定,数字越大,优先级越低。shouldFilter():判断该过滤器是否需要被执行。这里我们直接返回了true,因此该过滤器对所有请求都会生效。实际运用中我们可以利用该函数来指定过滤器的有效范围。run():过滤器的具体逻辑。这里我们通过ctx.setSendZuulResponse(false)来让 Zuul 过滤该请求,不对其进行路由,然后通过ctx.setResponseStatusCode(401)设置了其返回的错误码,当然我们也可以进一步优化我们的返回,比如,通过ctx.setResponseBody(body)对返回 body 内容进行编辑等。
在实现了自定义过滤器之后,它并不会直接生效,我们还需要为其创建具体的 Bean 才能启动该过滤器,比如,在应用主类中增加如下内容:
import com.rickiyang.learn.filter.TokenFilter;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.netflix.zuul.EnableZuulProxy;
import org.springframework.context.annotation.Bean;
@EnableDiscoveryClient
@EnableZuulProxy
@SpringBootApplication
public class ZuulServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZuulServerApplication.class, args);
}
@Bean
public TokenFilter tokenFilter() {
return new TokenFilter();
}
}
Filter是Zuul的核心,用来实现对外服务的控制。Filter的生命周期有4个,分别是:
pre:在请求被路由之前调用。
routing:将请求路由到微服务。这种过滤器用于构建发送给微服务的请求,并使用Apache HttpClient或Netfilx Ribbon请求微服务。
post:在路由到微服务以后执行。这种过滤器可用来为响应添加标准的HTTP Header、收集统计信息和指标、将响应从微服务发送给客户端等。
error:其他阶段发生错误时执行该过滤器。
整个生命周期可以用下图来表示:

在 Zuul 中提供了一些默认的 Filter:
| 类型 | 顺序 | 过滤器 | 功能 |
|---|---|---|---|
| pre | -3 | ServletDetectionFilter | 标记处理Servlet的类型 |
| pre | -2 | Servlet30WrapperFilter | 包装HttpServletRequest请求 |
| pre | -1 | FormBodyWrapperFilter | 包装请求体 |
| route | 1 | DebugFilter | 标记调试标志 |
| route | 5 | PreDecorationFilter | 处理请求上下文供后续使用 |
| route | 10 | RibbonRoutingFilter | serviceId请求转发 |
| route | 100 | SimpleHostRoutingFilter | url请求转发 |
| route | 500 | SendForwardFilter | forward请求转发 |
| post | 0 | SendErrorFilter | 处理有错误的请求响应 |
| post | 1000 | SendResponseFilter | 处理正常的请求响应 |
使用 Zuul 进行限流
添加依赖:
<dependency>
<groupId>com.marcosbarbero.cloud</groupId>
<artifactId>spring-cloud-zuul-ratelimit</artifactId>
<version>1.3.2.RELEASE</version>
</dependency>
spring-cloud-zuul-ratelimit是和zuul整合提供分布式限流策略的扩展,只需在yaml中配置几行配置,就可使应用支持限流:
ratelimit:
enabled: true
repository: REDIS #使用redis存储,一定要大写!
policies:
eureka-client: #针对上面那个服务的限流
limit: 100 #每秒多少个请求
quota: 20 #quota 单位时间内允许访问的总时间(统计每次请求的时间综合)
refreshInterval: 60 #刷新时间窗口的时间,默认值 (秒)
type:
- ORIGIN #这里一定要大写,类型说明:URL通过请求路径区分,ORIGIN通过客户端IP地址区分,USER是通过登录用户名进行区分,也包括匿名用户
ratelimit 支持的限流粒度:
- 服务粒度 (默认配置,当前服务模块的限流控制)
- 用户粒度 (详细说明,见文末总结)
- ORIGIN粒度 (用户请求的origin作为粒度控制)
- 接口粒度 (请求接口的地址作为粒度控制)
- 以上粒度自由组合,又可以支持多种情况
- 如果还不够,自定义RateLimitKeyGenerator实现。
支持的存储方式:
- InMemoryRateLimiter - 使用 ConcurrentHashMap作为数据存储
- ConsulRateLimiter - 使用 Consul 作为数据存储
- RedisRateLimiter - 使用 Redis 作为数据存储
- SpringDataRateLimiter - 使用 数据库 作为数据存储
关于Zuul网关的基本使用本节先讲到这里,下一节继续讲 Zuul 的高阶使用。
Spring Cloud Zuul 概览的更多相关文章
- Spring Cloud 微服务二:API网关spring cloud zuul
前言:本章将继续上一章Spring Cloud微服务,本章主要内容是API 网关,相关代码将延续上一章,如需了解请参考:Spring Cloud 微服务一:Consul注册中心 Spring clou ...
- Spring Cloud Netflix概览和架构设计
Spring Cloud简介 Spring Cloud是基于Spring Boot的一整套实现微服务的框架.他提供了微服务开发所需的配置管理.服务发现.断路器.智能路由.微代理.控制总线.全局锁.决策 ...
- Spring Cloud Zuul 添加 ZuulFilter
紧接着上篇随笔Spring Cloud Zuul写,添加过滤器,进行权限验证 1.添加过滤器 package com.dzpykj.filter; import java.io.IOException ...
- Spring Cloud Zuul网关 Filter、熔断、重试、高可用的使用方式。
时间过的很快,写springcloud(十):服务网关zuul初级篇还在半年前,现在已经是2018年了,我们继续探讨Zuul更高级的使用方式. 上篇文章主要介绍了Zuul网关使用模式,以及自动转发机制 ...
- 笔记:Spring Cloud Zuul 快速入门
Spring Cloud Zuul 实现了路由规则与实例的维护问题,通过 Spring Cloud Eureka 进行整合,将自身注册为 Eureka 服务治理下的应用,同时从 Eureka 中获取了 ...
- Spring Cloud Zuul 限流详解(附源码)(转)
在高并发的应用中,限流往往是一个绕不开的话题.本文详细探讨在Spring Cloud中如何实现限流. 在 Zuul 上实现限流是个不错的选择,只需要编写一个过滤器就可以了,关键在于如何实现限流的算法. ...
- Spring Cloud Zuul 中文文件上传乱码
原文地址:https://segmentfault.com/a/1190000011650034 1 描述 使用Spring Cloud Zuul进行路由转发时候吗,文件上传会造成中文乱码“?”.1. ...
- spring cloud zuul参数调优
zuul 内置参数 zuul.host.maxTotalConnections 适用于ApacheHttpClient,如果是okhttp无效.每个服务的http客户端连接池最大连接,默认是200. ...
- Spring Cloud Zuul 网关使用与 OAuth2.0 认证授权服务
API 网关的出现的原因是微服务架构的出现,不同的微服务一般会有不同的服务地址,而外部客户端可能需要调用多个服务的接口才能完成一个业务需求,如果让客户端直接与各个微服务通信,会有以下的问题: 客户端会 ...
随机推荐
- element-ui Upload 上传获取当前选择的视频时长
<el-upload class="upload-demo" ref="vidos" :action="URL+'/api/post/file' ...
- 数据结构与算法—Trie树
Trie,又经常叫前缀树,字典树等等.它有很多变种,如后缀树,Radix Tree/Trie,PATRICIA tree,以及bitwise版本的crit-bit tree.当然很多名字的意义其实有交 ...
- spring boot如何处理异步请求异常
springboot自定义错误页面 原创 2017年05月19日 13:26:46 标签: spring-boot 方法一:Spring Boot 将所有的错误默认映射到/error, 实现Err ...
- /bin/false 和 /usr/sbin/nologin
比较常用的用法: #添加一个不能登录的用户 useradd -d /usr/local/apache -g apache -s /bin/false apache 要拒绝系统用户登录,可以将其shel ...
- Nginx 反向代理与负载均衡的配置
已经很久没有写博了,因为最近学车加上各种问题一直没时间, 今天刚好想起有好多的东西还没来得及记录.回到正题: Nginx是一个非常强大的web轻量级服务器,许多大厂也用Nginx进行负载均衡和反向代理 ...
- Zebra-打印特殊字符
Zebra在打印一些特殊的字符时,会出异常. 在要打印的字符串前加 ^FH 然后将字符换成 ASCii编码或utf-8编码的16进制,在前面加_,如D094写成_DO_94 查看字符的编码 htt ...
- 使用Kubeadm安装Kubernetes【单Master节点】
参考:Kubernetes官方文档 Kubernetes安装方案选择 Centos 7 配置科学上网 安装Calico网络插件 kubernetes-dashboard部署 Kubernetes ...
- zabbix--4.0源码安装
Zabbix4.0 源码编译安装 ps:其实相对 zabbix 来说,直接按照官网 yum 安装还是要方便点,我这里已经有 lnmp 的环境了,就想自己编译安装试下. 官网yum安装中文文档:http ...
- admin端的专业管理模块功能测试
1.概述 1.1 测试范围 本次所测试的内容是admin端的专业管理模块. 1.2 测试方法 本次测试采用黑盒子方法进行集成测试. 1.3 测试环境 操作系统:Windows 2012 Server ...
- DFS 算法模板
dfs算法模板: 1.下一层是多节点的dfs遍历 def dfs(array or root, cur_layer, path, result): if cur_layer == len(array) ...