浅谈HDFS(三)之DataNote
DataNode工作机制
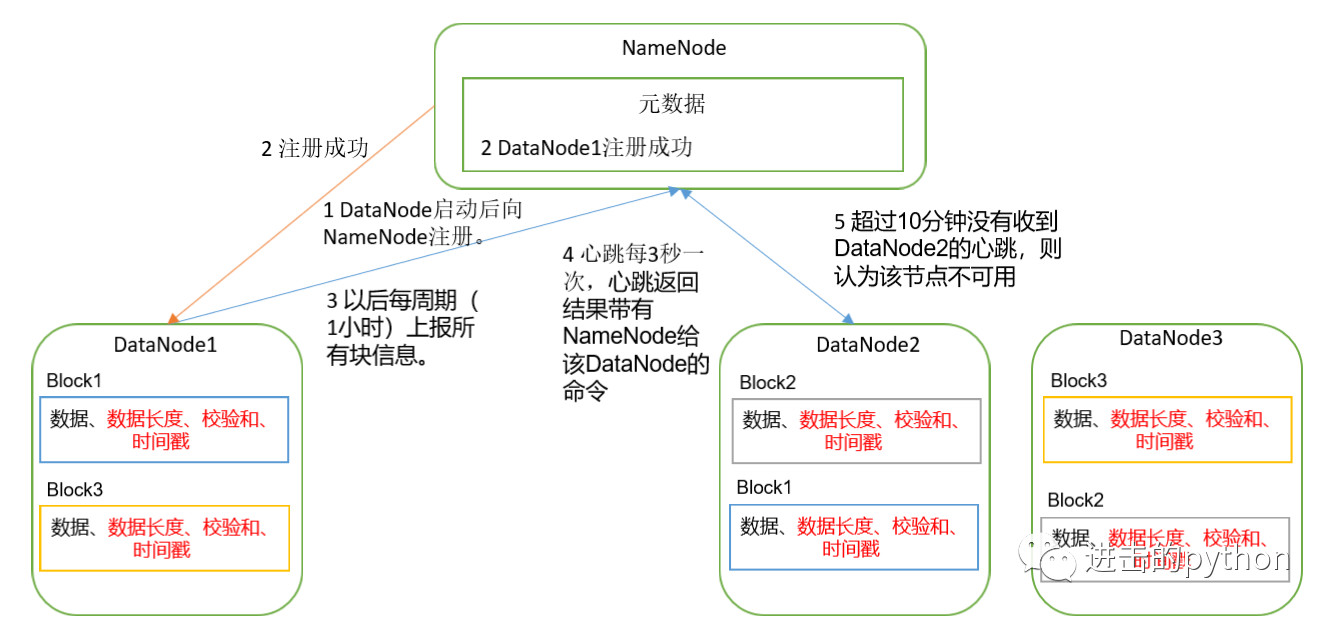
- 一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
- DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
- DataNode与NameNode之间有一个心跳事件,心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令,如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
- 集群运行中可以安全加入和退出一些机器
数据完整性
思考:如果电脑磁盘里面存储的数据是控制高铁信号灯的红灯信号(1)和绿灯信号(0),但是存储该数据的磁盘坏了,一直显示是绿灯,是否很危险?
同理,DataNode节点上的数据损坏了,却没有发现,是否也很危险,那么如何解决呢?
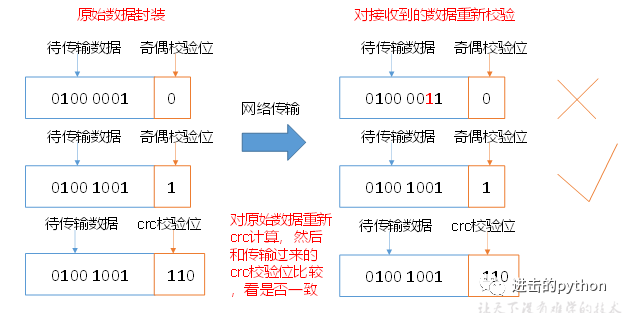
- 保证数据完整性的方法
- 当DataNode读取Block的时候,它会计算CheckSum(校验和)
- 如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏
- Client读取其他DataNode上的Block
- DataNode在其文件创建后周期验证CheckSum,如下图:
掉线时参数设置
DataNode进程死亡或者网络故障造成DataNode无法与NameNode通信时的TimeOut参数设置
- NameNode不会立即把该节点判断为死亡,要经过一段时间,这段时间称作超时时长
- HDFS默认的超时时长为10分钟+30秒
- 超时时长的计算公式为:
# dfs.namenode.heartbeat.recheck-interval默认为300000ms,dfs.heartbeat.interval默认为5s
TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
- 实际开发的时候,可以根据自己服务器的情况进行调整,比如服务器性能比较低,那么可以适当的把时间调长;如果服务器性能很好,那么可以适当缩短。
服役新数据节点
需求:随着公司业务的增长或者重大活动(例如双11),数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。
- 步骤:
- 克隆一台虚拟机
- 修改IP地址和主机名称
- 删除原来HDFS文件系统中留存的data和logs文件
- 直接单点启动节点即可
退役旧数据节点
退役旧数据节点有两种方式:添加白名单和黑名单退役
添加白名单
- 步骤:
- 在NameNode的
hadoop安装目录/etc/hadoop目录下创建dfs.hosts文件 - 添加白名单主机名称
- 在NameNode的hdfs-site.xml配置文件中增加dfs.hosts属性
<property>
<name>dfs.hosts</name>
# dfs.hosts文件所在路径
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value>
</property>
- 配置文件同步到集群其它节点
- 刷新NameNode
[kocdaniel@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
- 更新ResourceManager节点
[kocdaniel@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
- 如果数据不均衡,可以用命令实现集群的再平衡
[kocdaniel@hadoop102 sbin]$ ./start-balancer.sh
黑名单退役
- 步骤:
- 在NameNode的
hadoop安装目录/etc/hadoop目录下创建dfs.hosts.exclude文件 - 添加要退役的主机名称
- 在NameNode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value>
</property>
- 配置文件同步到集群其它节点
- 刷新NameNode、刷新ResourceManager
[kocdaniel@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[kocdaniel@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
- 检查Web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其他节点
- 等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。
- 注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役
- 注意:不允许白名单和黑名单中同时出现同一个主机名称。
两者的不同
- 添加白名单比较暴躁,会直接把要退役的节点服务关掉,不复制数据
- 黑名单退役,会将要退役的节点服务器的数据复制到其它节点上,不会直接关闭节点服务,比较慢
DataNode多目录配置
- DataNode也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本,与NameNode多目录不同
- 作用:保证所有磁盘都被利用均衡,类似于windows中的磁盘分区
欢迎关注下方公众号,获取更多文章信息

浅谈HDFS(三)之DataNote的更多相关文章
- 浅谈C++三种传参方式
浅谈C++三种传参方式 C++给函数传参中,主要有三种方式:分别是值传递.指针传递和引用传递. 下面通过讲解和实例来说明三种方式的区别. 值传递 我们都知道,在函数定义括号中的参数是形参,是给函数内专 ...
- 浅谈HDFS(一)
产生背景及定义 HDFS:分布式文件系统,用于存储文件,主要特点在于其分布式,即有很多服务器联合起来实现其功能,集群中的服务器各有各的角色 随着数据量越来越大,一个操作系统存不下所有的数据,那么就分配 ...
- 浅谈HDFS(二)之NameNode与SecondaryNameNode
NN与2NN工作机制 思考:NameNode中的元数据是存储在哪里的? 假设存储在NameNode节点的硬盘中,因为经常需要随机访问和响应客户请求,必然效率太低,所以是存储在内存中的 但是,如果存储在 ...
- 浅谈Servlet(三)
一.三种作用域 作用域:web开发中用于存储和获得数据. 1.request 一次请求有效,在forward跳转时可用request作用域传递数据. 2.session client不变,sessio ...
- 浅谈TCP三次握手和四次挥手
学习三次握手和四次挥手前,先了解下几个基础的概念. Seq:数据段序号,我们都知道TCP是提供有序传输的,有序传输的基础就是数据段序号,接收方在收到发送方乱序包的情况下可以根据Seq进行重新排序,确保 ...
- Linux网络编程——浅谈 TCP 三次握手和四次挥手
一.tcp协议格式 二.三次握手 在 TCP/IP 协议中.TCP 协议提供可靠的连接服务,採用三次握手建立一个连接. 第一次握手:建立连接时,client发送 syn 包(tcp协议中syn位置1. ...
- Salesforce Consumer Goods Cloud 浅谈篇三之 行动计划(Action Plan)相关配置
本篇参考: https://v.qq.com/x/page/f0772toebhd.html https://v.qq.com/x/page/e0772tsmtek.html https://v.qq ...
- Android事件分发机制浅谈(三)--源码分析(View篇)
写事件分发源码分析的时候很纠结,网上的许多博文都是先分析的View,后分析ViewGroup.因为我一开始理解的时候是按我的流程图往下走的,感觉方向很对,单是具体分析的时候总是磕磕绊绊的,老要跳到Vi ...
- 浅谈Spring(三)
一.基础Spring的标准测试 1.导入spring与junit继承的jar 2.引入注解 @RunWith(SpringJUnit4ClassRunner.class) @ContextConfig ...
随机推荐
- 【转载】 GPU状态监测 nvidia-smi 命令详解
原文地址: https://blog.csdn.net/huangfei711/article/details/79230446 ----------------------------------- ...
- Delphi根据不同分隔符获取字符串内容
function GetFieldValue(separator:Char;strLine: string; nNum: Integer): string; var Strs :TStrings; R ...
- 【数据集】WiderFace-A Face Detection Benchmark
前言 参考 1.WiderFace; 完
- C# .net 提升 asp.net mvc, asp.net core mvc 并发量
1.提升System.Net.ServicePointManager.DefaultConnectionLimit 2.提升最小工作线程数 ------ DefaultConnectionLimit在 ...
- Redis 分布式锁,C#通过Redis实现分布式锁(转)
目录(?)[+] 分布式锁一般有三种实现方式: 可靠性 分布式锁一般有三种实现方式: 1. 数据库乐观锁; 2. 基于Redis的分布式锁; 3. 基于ZooKeeper的分布式锁.本篇博客将介绍 ...
- 多分类评测标准(micro 和 macro)
- JVM知识点总览-高级Java工程师面试必备
jvm 总体梳理 jvm体系总体分四大块: 类的加载机制 jvm内存结构 GC算法 垃圾回收 GC分析 命令调优 当然这些知识点在之前的文章中都有详细的介绍,这里只做主干的梳理 这里画了一个思维导图, ...
- 卓金武《MATLAB在数学建模中的应用》 第2版
内容介绍 本书的作者都具有实际的数学建模参赛经历和竞赛指导经验.书中内容完全是根据数学建模竞赛的需要而编排的,涵盖了绝大部分数学建模问题的matlab求解方法.本书内容分上下两篇.上篇介绍数学建模中常 ...
- spark提交任务详解
- 三伏天里小试牛刀andriod 开发 #华为云·寻找黑马程序员#【华为云技术分享】
2019年07月,北京,三伏天,好热啊.越热自己还越懒得动换(肉身给的信号),但是做为产品经理/交互设计师的,总想着思考些什么(灵魂上给的信号),或者是学习些什么,更有利于将来的职业发展吧,哈哈哈.工 ...