数据分析之sklearn
一,介绍
Python 中的机器学习库
- 简单高效的数据挖掘和数据分析工具
- 可供大家使用,可在各种环境中重复使用
- 建立在 NumPy,SciPy 和 matplotlib 上
- 开放源码,可商业使用 - BSD license

二,线性回归算法模型
2个概念
样本集:用于对机器学习算法模型对象进行训练。样本集通常为一个DataFrame。
- 特征数据:特征数据的变化会影响目标数据的变化。必须为多列。
- 目标数据:结果。通常为一列1,建立线性回归算法模型对象
from sklearn.linear_model import LinearRegression
linear = LinearRegression() # 实例化 线性回归算法模型对象
2,使用样本数据对模型进行训练
数据:
near_citys_dist: array([47, 8, 71, 14, 37], dtype=int64) # 城市距离海边的最远距离
near_citys_max_temp: array([32.75, 32.79, 33.85, 32.81, 32.74]) # 城市的最高温度
# 使用这两组数据预测 城市温度与距离海边距离的关系
linear.fit(near_citys_dist.reshape(-1,1),near_citys_max_temp) # 注意特征数据必须时多列,所以把array转化为多列的
返回值: LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
3,对模型进行精准度的评分
linear.score(near_citys_dist.reshape(-1,1),near_citys_max_temp) # 0.5549063263099332
4,使用模型进行预测
x = np.array([65,44,12,99]).reshape(-1,1) # 给定一组特征数据
y = linear.predict(x) # 预测其值
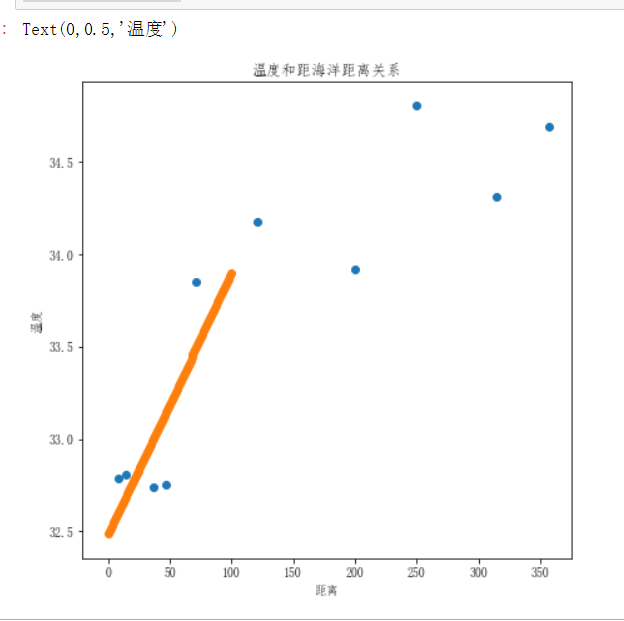
# array([ 33.40442982, 33.10898974, 32.65879535, 33.88276137]) #绘制回归曲线
x = np.linspace(0,100,num=100) # 给定一组特征数据
y = linear.predict(x.reshape(-1,1)) # 预测其值 plt.figure(figsize=(7,7))
plt.scatter(citys_dist,citys_max_temp)
plt.scatter(x,y)
plt.title('温度和距海洋距离关系')
plt.xlabel('距离')
plt.ylabel('温度')
数据分析之sklearn的更多相关文章
- python实现线性回归
参考:<机器学习实战>- Machine Learning in Action 一. 必备的包 一般而言,这几个包是比较常见的: • matplotlib,用于绘图 • numpy,数组处 ...
- Python数据挖掘之随机森林
主要是使用随机森林将four列缺失的数据补齐. # fit到RandomForestRegressor之中,n_estimators代表随机森林中的决策树数量 #n_jobs这个参数告诉引擎有多少处理 ...
- 数组与pandas模块
'''数组与pandas模块''' # numpy模块:用来做数据分析,对numpy数组(既有行又有列)--矩阵进行科学运算 # tensorflow/pytorch(数学专业/物理专业/计科专业硕士 ...
- 文本分类:Keras+RNN vs传统机器学习
摘要:本文通过Keras实现了一个RNN文本分类学习的案例,并详细介绍了循环神经网络原理知识及与机器学习对比. 本文分享自华为云社区<基于Keras+RNN的文本分类vs基于传统机器学习的文本分 ...
- 以KNN为例用sklearn进行数据分析和预测
准备 相关的库 相关的库包括: numpy pandas sklearn 带入代码如下: import pandas as pd import numpy as np from sklearn.nei ...
- 大数据分析——sklearn模块安装
前提条件:numpy.scipy以及matplotlib库的安装 (注:所有操作都在pycharm命令终端进行) ①numpy安装 pip install numpy ②scipy安装 pip ins ...
- 使用sklearn优雅地进行数据挖掘【转】
目录 1 使用sklearn进行数据挖掘 1.1 数据挖掘的步骤 1.2 数据初貌 1.3 关键技术2 并行处理 2.1 整体并行处理 2.2 部分并行处理3 流水线处理4 自动化调参5 持久化6 回 ...
- kaggle数据挖掘竞赛初步--Titanic<原始数据分析&缺失值处理>
Titanic是kaggle上的一道just for fun的题,没有奖金,但是数据整洁,拿来练手最好不过啦. 这道题给的数据是泰坦尼克号上的乘客的信息,预测乘客是否幸存.这是个二元分类的机器学习问题 ...
- 使用sklearn优雅地进行数据挖掘
目录 1 使用sklearn进行数据挖掘 1.1 数据挖掘的步骤 1.2 数据初貌 1.3 关键技术2 并行处理 2.1 整体并行处理 2.2 部分并行处理3 流水线处理4 自动化调参5 持久化6 回 ...
随机推荐
- 数据结构各种算法实现(C++模板)
目 录 1.顺序表 1 Seqlist.h 1 Test.cpp 6 2.单链表 8 ListNode.h 8 SingleList.h 10 test.cpp ...
- Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable) 解决办法
1:我遇到的问题: 在开机运行apt install vim 命令的时候,如下报错: 2:参考博客: 在Ubuntu中,有时候运用sudo apt-get install 安装软件时,会出现一下的情 ...
- GPRS 智能门禁控制器
本模块居于GPRS 2G网络,信号覆盖广,而且好. 主要用于微信门禁等,提供用户服务端搭建及相关接口. 您可以向门禁发送开门信号,并提醒开门成功的信号反馈. 同时支持发送开门ID号,并反馈成功ID号
- spring boot前后端参数传递方式
使用spring boot2X做后端,postman做前端测试 1.获取json字符串 @RestController public class Demo { @RequestMapping(&quo ...
- SignalR 填坑记
1.发送文字消息没有问题,如何发送文件消息 SignalR可以将参数序列化和反序列化. 这些参数被序列化的格式叫做Hub 协议, 所以Hub协议就是一种用来序列化和反序列化的格式. Hub协议的默认协 ...
- VS2017/VS 2019查看源代码
通过VS2017/VS 2019使用F12 查看DLL源代码 今天在一本书中偶然看到原来VS2017中是可以查看dll中的源码,具体步骤是:工具>选项>文本编辑器>c#>高 ...
- python 的技巧
pi = 0 n = 100 for k in range(n): pi+=1/pow(16,k)*(\ #一行不够写或不易读时用\,则多行与一行一样 4/(8*k+1)-2/(8*k+4)-\ 1/ ...
- 005 SpringCloud 学习笔记01-----系统架构的演变
1.系统架构的演变 随着互联网的发展,网站应用的规模不断扩大.需求的激增,带来的是技术上的压力.系统架构也因此不断的演进.升级.迭代.从单一应用,到垂直拆分,到分布式服务,到SOA,以及现在火热的微服 ...
- Word页眉实现首页不同、奇偶页不同 、更改页眉横线、页眉文字对齐 -- 视频教程(8)
1. 目标 目标1:实现页眉"首页不同,奇偶页不同" 目标2:更改页眉横线 目标3:页眉文字有三部分:第一部分左对齐,第二部分居中,第三部分右对齐 2. 教程 未完 ...... ...
- 嵌入式02 STM32 实验08 外部中断
一.中断 由于某个事件的发生,CPU暂停当前正在执行的程序,转而执行处理事件的一个程序.该程序执行完成后,CPU接着执行被暂停的程序.这个过程称为中断.(我正在捉泥鳅,但是我妈喊我回家吃饭,我必须回家 ...