Spark SQL里concat_ws和collect_set的作用
concat_ws: 用指定的字符连接字符串
例如:
连接字符串:
concat_ws("_", field1, field2),输出结果将会是:“field1_field2”。
数组元素连接:
concat_ws("_", [a,b,c]),输出结果将会是:"a_b_c"。
collect_set: 把聚合的数据组合成一个数组,一般搭配group by 使用。
例如有下表T_course;
| id | name | course |
| 1 | zhang san | Chinese |
| 2 | zhang san | Math |
| 3 | zhang san | English |
spark.sql("select name, collect_set(course) as course_set from T_course group by name");
结果是:
| name | course_set |
| zhang san | [Chinese,Math,English] |
贴上套牌车项目代码:
public class TpcCompute2 {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder().enableHiveSupport().appName("TpcCompute2").master("local").getOrCreate();
JavaSparkContext sc = new JavaSparkContext(spark.sparkContext());
sc.setLogLevel("ERROR");
//hphm,id,tgsj,lonlat&
spark.udf().register("getTpc", new ComputeUDF(), DataTypes.StringType);
spark.sql("use traffic");
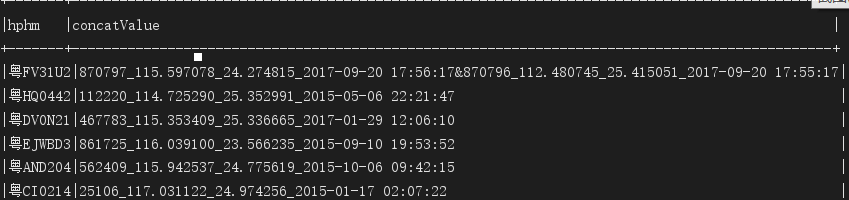
spark.sql("select hphm,concat_ws('&',collect_set(concat_ws('_',id,kk_lon_lat,tgsj))) as concatValue from t_cltgxx t where t.tgsj>'2015-01-01 00:00:00' group by hphm").show(false);
Dataset<Row> cltgxxDF =
spark.sql("select hphm,concatValue from (select hphm,getTpc(concat_ws('&',collect_set(concat_ws('_',id,kk_lon_lat,tgsj)))) as concatValue from t_cltgxx t where t.tgsj>'2015-01-01 00:00:00' group by hphm) where concatValue is not null");
cltgxxDF.show();
//创建集合累加器
CollectionAccumulator<String> acc = sc.sc().collectionAccumulator();
cltgxxDF.foreach(new ForeachFunction<Row>() {
@Override
public void call(Row row) throws Exception {
acc.add(row.getAs("concatValue"));
}
});
List<String> values = acc.value();
for (String id : accValues) {
System.out.println("accValues: " + id);
Dataset<Row> resultDF = spark.sql("select hphm,clpp,clys,tgsj,kkbh from t_cltgxx where id in (" + id.split("_")[] + "," + id.split("_")[] + ")");
resultDF.show();
Dataset<Row> resultDF2 = resultDF.withColumn("jsbh", functions.lit(new Date().getTime()))
.withColumn("create_time", functions.lit(new Timestamp(new Date().getTime())));
resultDF2.show();
resultDF2.write()
.format("jdbc")
.option("url","jdbc:mysql://lin01.cniao5.com:3306/traffic?characterEncoding=UTF-8")
.option("dbtable","t_tpc_result")
.option("user","root")
.option("password","")
.mode(SaveMode.Append)
.save();
}
}
spark.sql语句输出样式:
Spark SQL里concat_ws和collect_set的作用的更多相关文章
- 第三篇:Spark SQL Catalyst源码分析之Analyzer
/** Spark SQL源码分析系列文章*/ 前面几篇文章讲解了Spark SQL的核心执行流程和Spark SQL的Catalyst框架的Sql Parser是怎样接受用户输入sql,经过解析生成 ...
- Spark SQL Catalyst源代码分析之Analyzer
/** Spark SQL源代码分析系列文章*/ 前面几篇文章解说了Spark SQL的核心运行流程和Spark SQL的Catalyst框架的Sql Parser是如何接受用户输入sql,经过解析生 ...
- 第九篇:Spark SQL 源码分析之 In-Memory Columnar Storage源码分析之 cache table
/** Spark SQL源码分析系列文章*/ Spark SQL 可以将数据缓存到内存中,我们可以见到的通过调用cache table tableName即可将一张表缓存到内存中,来极大的提高查询效 ...
- 整理对Spark SQL的理解
Catalyst Catalyst是与Spark解耦的一个独立库,是一个impl-free的运行计划的生成和优化框架. 眼下与Spark Core还是耦合的.对此user邮件组里有人对此提出疑问,见m ...
- 转】 Spark SQL UDF使用
原博文出自于: http://blog.csdn.net/oopsoom/article/details/39401391 感谢! Spark1.1推出了Uer Define Function功能,用 ...
- Spark SQL CLI 实现分析
背景 本文主要介绍了Spark SQL里眼下的CLI实现,代码之后肯定会有不少变动,所以我关注的是比較核心的逻辑.主要是对照了Hive CLI的实现方式,比較Spark SQL在哪块地方做了改动,哪些 ...
- spark sql的agg函数,作用:在整体DataFrame不分组聚合
.agg(expers:column*) 返回dataframe类型 ,同数学计算求值 df.agg(max("age"), avg("salary")) df ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- 【转载】Spark SQL之External DataSource外部数据源
http://blog.csdn.net/oopsoom/article/details/42061077 一.Spark SQL External DataSource简介 随着Spark1.2的发 ...
随机推荐
- 用 ConfigMap 管理配置
1. ConfigMap介绍管理配置 ConfigMap介绍 Secret 可以为 Pod 提供密码.Token.私钥等敏感数据:对于一些非敏感数据,比如应用的配置信息,则可以用 ConfigMap ...
- c#中的解析HTML组件 -- (HtmlAgilityPack,Jumony,ScrapySharp,NSoup,Fizzler)
做数据抓取,网络爬虫方面的开发,自然少不了解析HTML源码的操作.那么问题来了,到底.NET如何来解析HTML,有哪些解析HTML源码的好用的,有效的组件呢? 作者在开始做这方面开发的时候就被这些 ...
- Mysql的安装与环境的配置
Mysql的安装与环境的配置 这里以Mysql5.5为例: (1)双击安装包,点击next (2)选择自定义,点击Next (3)修改路径,点击Next (4)选择精确配置,点击Next (5)选择开 ...
- ajax jsonp函数调用
jsonp数据 jsonpHandler({name:"liujinyu",age:"24"}) ajax调用 $.ajax({ type:'GET', ...
- win10怎么查看当前用户账号
https://jingyan.baidu.com/article/9225544679ab37851648f489.html
- Atcoder Beginner Contest 138 简要题解
D - Ki 题意:给一棵有根树,节点1为根,有$Q$次操作,每次操作将一个节点及其子树的所有节点的权值加上一个值,问最后每个节点的权值. 思路:dfs序再差分一下就行了. #include < ...
- Numpy | 02 Ndarray 对象
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引. ndarray 对象是用于存放同类型元素的多维数组. ndarr ...
- [Java] Spring boot2 整合 Thymeleaf 后 去除模板缓存
Spring boot2 整合 Thymeleaf 后 去除模板缓存 网上好多文章只是简单粗暴的说,在 application.properties 做如下配置即可: #Thymeleaf cach ...
- trutle库的使用基础
turtle库的使用: 概括: turtle绘图体系:1969年诞生,主要用于程序设计入门 Python语言的标准库之一 入门级的图形绘制函数库 原理: turtle的原(wan)理(fa) (tur ...
- 04-树5 Root of AVL Tree (25 分)
An AVL tree is a self-balancing binary search tree. In an AVL tree, the heights of the two child sub ...