示例 NetworkWordCount
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext} /**
* WordCount程序,Spark Streaming消费TCP Server发过来的实时数据的例子:
*
* 1、在master服务器上启动一个Netcat server
* `$ nc -lk 9998` (如果nc命令无效的话,我们可以用yum install -y nc来安装nc)
*
*
*/
object LocalNetworkWordCount {
def main(args: Array[String]) { // StreamingContext 编程入口
//local[2] 启用两个core, 一个线程用于接收数据,一个线程用于处理数据
//Seconds(1) 每隔一秒钟处理一次
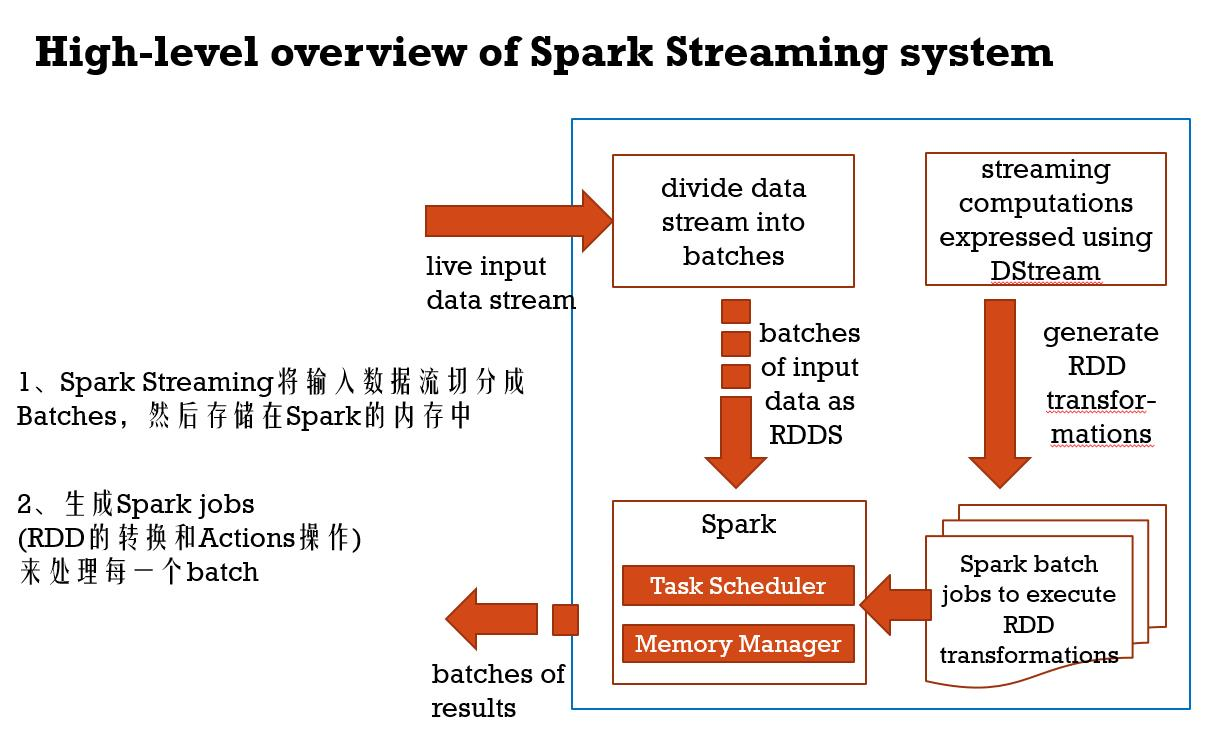
val ssc = new StreamingContext("local[2]", "LocalNetworkWordCount", Seconds(1),
System.getenv("SPARK_HOME"), StreamingContext.jarOfClass(this.getClass).toSeq) //数据接收器(Receiver)
//创建一个接收器(ReceiverInputDStream),这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理
val lines = ssc.socketTextStream("localhost", 9998, StorageLevel.MEMORY_AND_DISK_SER) //数据处理(Process)
//处理的逻辑,就是简单的进行word count
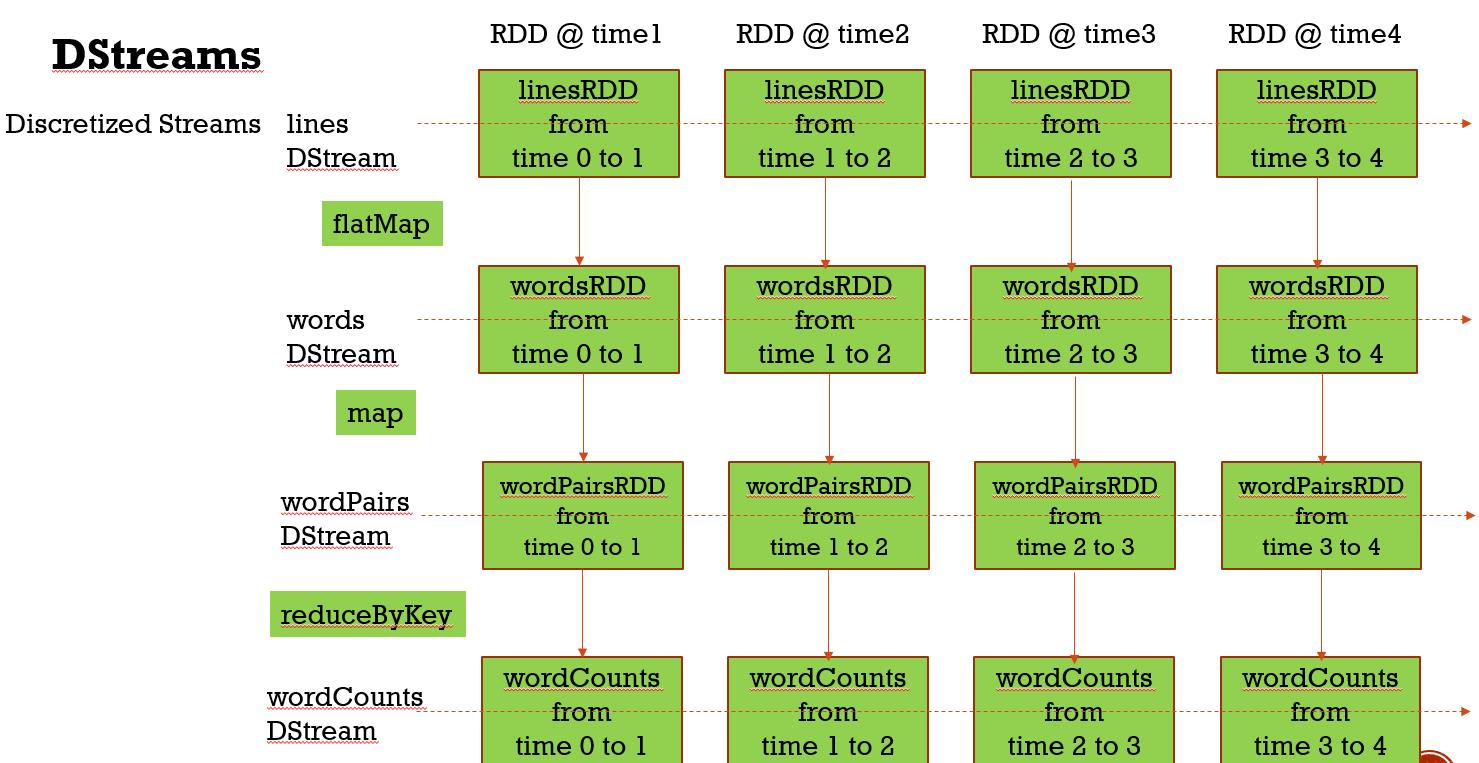
val words = lines.flatMap(_.split(" "))
val wordPairs = words.map(x => (x, 1))
val wordCounts = wordPairs.reduceByKey(_ + _) //结果输出(Output)
//将结果输出到控制台
wordCounts.print() //启动Streaming处理流
ssc.start() //等待Streaming程序终止
// 7 X 24 小时运行,一直等待不会停止
//注释该行代码后,运行一次便终止(必须打开)
ssc.awaitTermination()
}
}
NetworkWordCount
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* WordCount程序,Spark Streaming消费TCP Server发过来的实时数据的例子:
*
* 1、在master服务器上启动一个Netcat server
* `$ nc -lk 9998` (如果nc命令无效的话,我们可以用yum install -y nc来安装nc)
*
* 2、用下面的命令在在集群中将Spark Streaming应用跑起来
spark-submit --class com.twq.streaming.NetworkWordCount \
--master spark://master:7077 \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--total-executor-cores 4 \
--executor-cores 2 \
/home/hadoop-twq/spark-course/streaming/spark-streaming-basic-1.0-SNAPSHOT.jar
*/
object NetworkWordCount {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf)
// StreamingContext 编程入口
val ssc = new StreamingContext(sc, Seconds(1))
//数据接收器(Receiver)
//创建一个接收器(ReceiverInputDStream),这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理
// StorageLevel.MEMORY_AND_DISK_SER_2 通过该方式存储在内存中 先放入内存中,内存不够放在磁盘中,以字节的方式储存,储存两份
val lines = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER_2)
//数据处理(Process)
//处理的逻辑,就是简单的进行word count
val words = lines.flatMap(_.split(" "))
val wordPairs = words.map(x => (x, 1))
val wordCounts = wordPairs.reduceByKey(_ + _)
//结果输出(Output)
//将结果输出到控制台
wordCounts.print()
//启动Streaming处理流
ssc.start()
//等待Streaming程序终止
ssc.awaitTermination()
}
}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext} /**
* WordCount程序,Spark Streaming消费TCP Server发过来的实时数据的例子:
*
* 1、在master服务器上启动一个Netcat server
* `$ nc -lk 9998` (如果nc命令无效的话,我们可以用yum install -y nc来安装nc)
*
* 2、用下面的命令在在集群中将Spark Streaming应用跑起来
spark-submit --class com.twq.streaming.NetworkWordCountDetail \
--master spark://master:7077 \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--total-executor-cores 4 \
--executor-cores 2 \
/home/hadoop-twq/spark-course/streaming/spark-streaming-basic-1.0-SNAPSHOT.jar
*/
object NetworkWordCountDetail {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf) // Create the context with a 1 second batch size //1、StreamingContext 是 Spark Streaming程序的入口,那么StreamingContext和SparkContext的关系是什么呢?
//1.1、StreamingContext需要持有一个SparkContext的引用
val ssc = new StreamingContext(sc, Seconds(1)) //1.2、如果SparkContext没有启动的话,我们可以用下面的代码启动一个StreamingContext
val ssc2 = new StreamingContext(sparkConf, Seconds(1)) //这行代码会在内部启动一个SparkContext
ssc.sparkContext //可以从StreamingContext中获取到SparkContext
//1.3、对StreamingContext调用stop的话,可能会将SparkContext stop掉,
// 如果不想stop掉SparkContext,我们可以调用
ssc.stop(false) sc.stop() //2:StreamingContext的注意事项:
// 2.1、在同一个时间内,同一个JVM中StreamingContext只能有一个
// 2.2、如果一个StreamingContext启动起来了,
// 那么我们就不能为这个StreamingContext添加任何的新的Streaming计算
// 2.3、如果一个StreamingContext被stop了,那么它不能再次被start
// 2.4、一个SparkContext可以启动多个StreamingContext,
// 前提是前面的StreamingContext被stop掉了,而SparkContext没有被stop掉 //创建一个接收器(ReceiverInputDStream),这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理
val lines = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER) //处理的逻辑,就是简单的进行word count
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) //将结果输出到控制台
wordCounts.print() //启动Streaming处理流
ssc.start() //等待Streaming程序终止
ssc.awaitTermination()
}
}
示例 NetworkWordCount的更多相关文章
- Apache Spark 2.2.0 中文文档 - Spark Streaming 编程指南 | ApacheCN
Spark Streaming 编程指南 概述 一个入门示例 基础概念 依赖 初始化 StreamingContext Discretized Streams (DStreams)(离散化流) Inp ...
- Spark Streaming编程指南
Overview A Quick Example Basic Concepts Linking Initializing StreamingContext Discretized Streams (D ...
- Apache Spark 2.2.0 中文文档
Apache Spark 2.2.0 中文文档 - 快速入门 | ApacheCN Geekhoo 关注 2017.09.20 13:55* 字数 2062 阅读 13评论 0喜欢 1 快速入门 使用 ...
- SparkStreaming 编程指南
摘要:学习SparkStreaming从官网的编程指南开始,由于Python编码修改方便不用打包,这里只整理python代码! 一.概述 Spark Streaming 是 Spark Core AP ...
- Apache Spark 2.2.0 中文文档 - Spark Streaming 编程指南
Spark Streaming 编程指南 概述 一个入门示例 基础概念 依赖 初始化 StreamingContext Discretized Streams (DStreams)(离散化流) Inp ...
- Spark Streaming编程示例
近期也有开始研究使用spark streaming来实现流式处理.本文以流式计算word count为例,简单描述如何进行spark streaming编程. 1. 依赖的jar包 参考<分别用 ...
- Swift3.0服务端开发(一) 完整示例概述及Perfect环境搭建与配置(服务端+iOS端)
本篇博客算是一个开头,接下来会持续更新使用Swift3.0开发服务端相关的博客.当然,我们使用目前使用Swift开发服务端较为成熟的框架Perfect来实现.Perfect框架是加拿大一个创业团队开发 ...
- .NET跨平台之旅:将示例站点升级至 ASP.NET Core 1.1
微软今天在 Connect(); // 2016 上发布了 .NET Core 1.1 ,ASP.NET Core 1.1 以及 Entity Framework Core 1.1.紧跟这次发布,我们 ...
- 通过Jexus 部署 dotnetcore版本MusicStore 示例程序
ASPNET Music Store application 是一个展示最新的.NET 平台(包括.NET Core/Mono等)上使用MVC 和Entity Framework的示例程序,本文将展示 ...
随机推荐
- LVS的基础使用
LVS的基础使用 LVS的介绍 A:什么是LVS B:cluster(集群的概念) C:LVS的介绍 LVS的使用 A:ipvsadm命令的使用 ♣一:LVS的介绍 A:什么是lvs LVS的英文全称 ...
- IP通信学习心得02
1.7层模型 2.OSI的应用 3.如何辨别.数清冲突域和广播域 1)首先,须知第一层不能隔离冲突域和广播域.例如集线器或者直接连PC 2)其次,第二层可以隔离冲突域,但不能隔离广播域.例如,二层交换 ...
- oracle11g数据库导入导出方法教程
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/xinxiaoyonng/article/ ...
- Python学习日记(一) String函数使用
s = "abcaDa a" s2 = "123a abc ABCSAa s " s3 = "\tas \t\tb123" s4 = ' & ...
- MySQL运维中的Tips--持续更新
1.into outfile 生成sql:一般都是生成文本或者其他形式的文件,现在需要生成sql形式的文件.配置文件加secure_file_priv=''select concat('insert ...
- Java基础系列3:多线程超详细总结
该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架. 1.线程概述 几乎所 ...
- MVC-09安全
部分8:添加安全. MVC应用程序安全性 Models文件夹包含表示应用程序模型的类. Visual Web Developer自动创建AccountModels.cs文件,该文件包含用于应用程序认证 ...
- 【转载】C#使用Random类来生成指定范围内的随机数
C#的程序应用的开发中,可以使用Random随机数类的对象来生成相应的随机数,通过Random随机数对象生成随机数的时候,支持设置随机数的最小值和最大值,例如可以指定生成1到1000范围内的随机数.R ...
- linux设备树的建立过程
为了阐明表示总线.设备和设备驱动程序的各个数据结构之间彼此的关联,它们的注册过程是很有必要的.顺序一定是如下:(1)注册总线---bus_register:(2)注册设备device_register ...
- [LeetCode] 581. 最短无序连续子数组 ☆
描述 给定一个整数数组,你需要寻找一个连续的子数组,如果对这个子数组进行升序排序,那么整个数组都会变为升序排序. 你找到的子数组应是最短的,请输出它的长度. 示例 1: 输入: [2, 6, 4, 8 ...