mysql-查询(DQL)

+
注释:mysql中的+号只有一个作用,就是运算符,没有连接字符串的作用,连接字符串用concat。
select 1+3;两个操作数都是数值型,则做加法运算。
select 'wj'+28;
select ''+94;只要其中有一个时字符型,则会试图将字符转换为数值型。如果转换成功,则做加法运算;如果转换失败,则将字符转换为0继续做加法运算。
select null+100;如果其中一方为null,则结果肯定为null。
concat(str1,str2,…)
注释:连接多个字符串
select concat('a','b','c');
select concat(first_name,last_name) from employees;
条件运算符:> < = != <> >= <=
注释:mysql支持两个形式的不等运算符,!=和<>都支持,但是建议<>。
作用:用于在where关键词后,用于条件筛选。
select * from employees where salary<>100;
逻辑运算符:and or not
注释:逻辑运算符用于连接条件表达式,可以用括号把条件包起来进行逻辑运算。
and(&&)两个条件都是true,则结果为true。
or(||)两个条件有一个为true,则结果为true。
not(!)条件如果为true,则结果为false。
#查询部门编号不是在90到110之间,或者工资高于15000的员工信息
select * from employees where department_id<90 and department_id>110 or salary>15000;
select * from employees where not(department_id>=90 and department_id<=110) or salary>15000;
模糊查询:like、between and、in、is null、is not null
like:与like搭配使用的的通配符有(_:匹配任意一个字符,%:匹配任意多个字符,如果想匹配_或%则可以通过转移符号\反斜杠来标明,或者通过一个关键字escape进行转义)
select last_name from employees where last_name like '_\_%'; 或者用escape关键字转义 select last_name from employees where last_name like '_$_%' escape '$';通过escape关键字标识$为转义字符,这样$后面的第一个字符将被转义,_不会再被解读为通配符。
between and:1.使用between and 可以提高语句的简洁度,两边的类型必须一致或者能阴式的转换。
2.包含临界值,也就是如果说between 10 and 20,这个10和20是包含的。
3.临界值不能调换,左边的数要小于等于右边的数,也就是说上面的10和20不能调换,再通俗点即between and完全等价于,大于等于左边的值,小于等于右边的值。
select * from employees where salary between 10000 and 20000;
in:判断某字段的值是否属于in列表中的某一项;in列表的值类型必须一致或可以隐式转换;完全等价于xxx=### or ...;不支持通配符
select job_id from employees where job_id in('it_prot','ad_vp');
is null:=或<>等条件运算符不能判断null值;is null或is not null 可以判断null值
select commission_pct from employees where commission_pct is null;
安全等于:<=>
注释:既可以判断null值,又可以判断普通类型的值,可读性较低,不建议使用,不能与!等搭配使用只能判断是否相等。 is null:仅仅可以判断null值,可读性高,建议使用。
select * from employees where salary <=> 10000; select commission_pct from employees where commission_pct <=> null;
ifnull(expr1,expr2,…)
注释:判空
案例:查询员工的年薪
错误的:select salary*12*(1+commission_pct) as 年薪 from employees; 错误是因为commission_pct奖金率可能存在空值的情况。 正确的: select salary*12*(1+ifnull(commission_pct,0)) as 年薪 from employees; 如果是null就转化为0
isnull(expr)
注释:判断是否为空,如果表达式或字段是null,则结果为1,否则为0;
select isnull(commission_pct) from employees;最后可以看到结果,如果是null的查询出来的都是1,不是null的查询出来都是0。
length(str)
注释:可以计算一个字符串的长度
查询-排序
注释: 1.order by 字段 asc/desc,排序默认升序排序,支持单个字段,多个字段,表达式,别名,函数。
2.可以对多个字段分别排序,如果第一个相等,会按第二个进行排序。
3.order by 子句一般是放在查询语句的最后面,limit子句除外。
案例:查询员工信息,先按工资升序,再按员工编号降序。
select * from employees order by salary asc,employee_id desc;如果都不写排序方式,直接order by 字段1,字段2,则会按照两个字段升序排序。
字符函数
1.length() 获取参数值的字节个数
select length('wujing');结果为6个字节。
select length('诸葛wujing');结果为12个字节,在utf8下,一个汉字占3个字节。
select variables like '%char%';可以查看编码格式。
2.concat() 拼接字符串
select concat('wu','jing');
3.upper、lower 大小写转换
select upper('wujing');将小写转换为大写。
select lower('WUJING');将大写转换为小写。
select concat(upper('wu'),lower('JING'));分别转换为大小写,并进行拼接。
4.substr同substring
截取字符串,索引从1开始。
#截取指定索引后面所有字符
select substr('怀念大学生活',3);结果为:大学生活。从第三个字符串开始截取,包含第三个字符串。
#截取指定索引处指定字符长度的字符串。
select substr('wj小王八蛋',4,2);结果为:王八。
5.instr 返回子串第一次出现的索引,如果找不到返回0
select instr('石家庄市裕华区','裕华');结果为:5
6.trim 将字符串左右去空,或去除字符串左右指定字符。
selct trim(' 你妹的 ');结果为:你妹的
select trim('j' from 'jjjjjjj你好j吗jjjjjjjj');结果为:你好j吗
7.lpad 用指定字符实现左填充指定长度
select lpad('火车',5,'啊');结果为:啊啊啊火车。记住是字符,不是字节
8.rpad 用指定字符实现右填充指定长度
select rpad('今天',7,'烦');结果为:今天烦烦烦烦烦
9.replace 字符替换
select replace('j我有点累了','j','不想了');结果为:不想了我有点累了。这个的三个参数,第一个是原始的字符串,第二个是要替换的字符,第三个是要替换为的字符。
数学函数
1.round 四舍五入
select round(1.56);结果为:2
select round(1.42);结果为:1
select round(-1.56);结果为:-2。这个先别管正负,直接先四舍五入再加上符号即可,貌似与java中的一个四舍五入有点区别。
select round(-1.45);结果为:-1
select round(1.268,2);结果为:1.27。也即小数点后保留两位。
2.ceil 向上取整,返回>=该参数的最小整数。
select ceil(1.26);结果为:2
select ceil(1.0);结果为:1。记住是>=1.0的最小整数
3.floor 向下取整,返回<=该参数的最大整数
select floor(1.59);结果为:1
select floor(1.00);结果为:1
select floor(-1.59);结果为:-2
4.truncate j截断
select truncate(1.899,2);结果为:1.89。保留两位,不会进行四舍五入等操作,直接截断。
5.mod 取余
/*
mod(a,b); 等价于a-a/b*b 最后的正负总与a被除数一致
*/
select mod(10,3);结果为:1。等价于select 10%3;
select mod(10,-3);结果为:-1
日期函数
1.now 当前系统日期+时间
select now();结果为:2019-03-30 16:20:17
2.curdate 当前系统日期,不包括时间
select curdate();结果为:2019-03-30
3.curtime 当前系统时间,不包括日期
select curtime();结果为:16:27:18
4.获取指定的部分,年、月、日、时、分、秒
select year(now());结果为:2019。传入的可以是完整的日期,也可以是能转换为日期的字符串。
select year('2019-03-30');结果为:2019
5.str_to_date 将日期格式的字符转换为指定格式的日期,如:str_to_date('3-09-2013','%d-%m-%y')
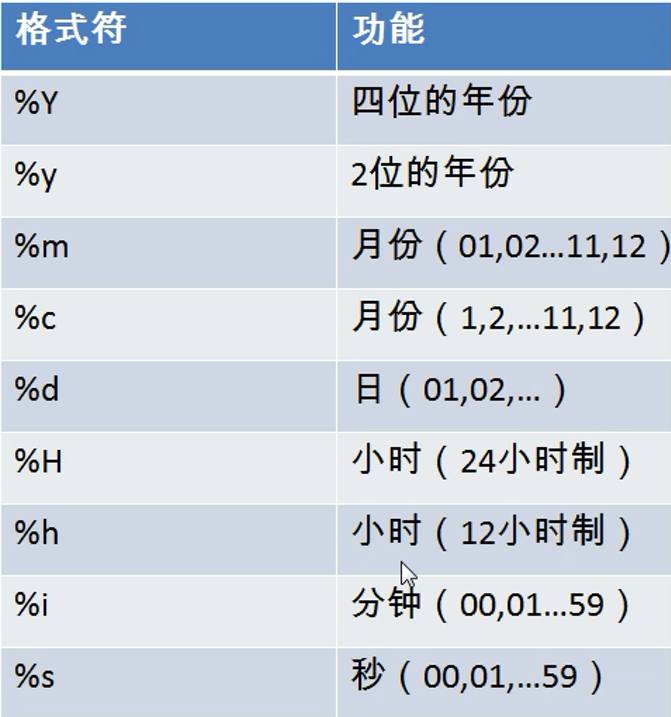
6.date_format 将日期转换为字符,如:date_format('2018/6/6','Y%年%m月%d日')
其他函数
select VERSION();
select database();
select user();
7.datadiff(expr1,expr2) 获取两个日期的相差的天数(左边的日期减右边的日期,如果左边的大则为正数)
select datediff(MAX(hiredate),min(hiredate)) from employees;这其中的两个表达式不仅可以传入时间类型,也可以传入日期字符串
流程控制函数
1.if(expr1,expr2,expr3) if else的效果
select last_name,salary,if(commission_pct is not null,concat('有奖金',commission_pct),'没奖金,呵呵') from employees
2.case函数的使用,switch case的效果
/*
java中
switch(){
case 常量1:语句1;break;
case 常量2:语句2;break;
default:语句n;break;
}
mysql中
case 要判断的字段或表达式
when 常量1 then 要显示的值1或表达式1;
when 常量2 then 要显示的值2或表达式2;
...
else 要显示的值n或表达式n;
end;
注意:用的时候如果是跟在select后面作为一个值输出时,then后面不要加分号,而且此时case后面要加某个字段,如果是在存储过程中,则then后可以是一个语句,此时才可以加分号。
*/
select salary 原始工资,department_id as 部门id,
case department_id
when 30 then salary*1.1
when 40 then salary*1.2
else salary
end as 新工资
from employees;
3.case函数的使用,if else的效果
mysql中格式为:
case
when 条件1 then 要显示的值1/语句1;如果是值则没有分号,以下类推。
when 条件2 then 要显示的值2/语句2;
...
else 要显示的值n/语句n;
end 案例:查询员工工资级别
如果工资>20000,显示A级别
如果工资>15000,显示B级别
如果工资>10000,显示C级别
否则显示D级别
select last_name,salary,
case
when salary>20000 then 'A'
when salary>15000 then 'B'
when salary>10000 then 'C'
else 'D'
end as 工资级别
from employees;
分组函数
注解:用作统计使用,又称为聚合函数,或统计函数,或组函数。
分类:sum 求和、avg 平均值、max 最大值、min 最小值、count 计算个数
注意:1.sum、avg用于处理数值型
2.max、min、count可以处理任何类型
3.以上分组函数都忽略null值
4.可以和distinct搭配使用实现去重运算的效果,格式:select count(distinct salary) from employees;
5.count函数的单独介绍,一般使用count(*)作为统计行数。
6.和分组函数一同查询的字段要求是group by后的字段。
分组查询
语法:
select 分组函数,列(要出现在group by的后面)
from 表
【where 筛选条件】
group by 分组的列表
【having】分组后条件
【order by 子句】
注意:查询列表比较特殊,必须是group by后面出现的字段;并且如果在分组后加条件的话要用having关键字(在分组前加条件或在分组后加条件,就看你的条件是依赖分组前的原始表还是分组后的虚表。)
特点:
| 数据源 | 位置 | 关键字 | |
| 分组前筛选 | 原始表 | group by 子句前面 | where |
| 分组后筛选 | 分组后的结果集 | group by 子句后面 | having |
①分组函数作条件肯定是放在having子句中
②能用分组前筛选的,就优先使用分组前筛选。
③grou by子句支持单个字段分组、多个字段分组(多个字段用逗号隔开,没先后顺序)、表达式或函数(用的较少)
④可以添加排序(排序放在整个分组查询的最后) 案例1:查询每个工种有奖金的员工的最高工资>12000的工种编号和最高工资(分组前后都加条件)
select job_id,MAX(salary) from employees where commission_pct is not null group by job_id HAVING MAX(salary)>12000;
案例2:查询领导编号>102的每个领导手下的最低工资>5000的领导编号是哪个,以及其最低工资
select manager_id,min(salary) from employees where manager_id>102 group by manager_id HAVING MIN(salary)>5000;
分组查询-按多个字段分组
注释:直接在group by子句中添加多个字段用逗号隔开即可,没有先后顺序要求。
查询每个部门每个工种的平均工资
select avg(salary),department_id,job_id from employees group by department_id,job_id;
分组查询-添加排序
查询每个部门每个工种的平均工资,并按工资高低显示
select avg(salary),department_id,job_id from employees group by department_id,job_id order by avg(salary) desc;
连接查询(sql92语法)
内连接
等值连接
①多表等值连接的结果为多表的交集部分
②n表连接,至少需要n-1个连接条件
③多表的顺序没有要求
④一般需要为表起别名
⑤可以搭配其他所有子句使用,比如分组、排序、筛选
非等值连接
注释:也即连接的条件是非等值的,是在一个区间中。
#查询员工的工资和工资级别
select salary,grade_level from employees e,job_grades j where e.salary between j.lowest_sal and j.highest_sal;
自连接
注释:把本张表当成两张表,甚至更多表使用,自己连接自己。
#查询员工名和上级的名称
select e1.last_name 员工名,e2.last_name 上级名 from employees e1,employees e2 where e1.manager_id=e2.employee_id;
连接查询(sql99语法)
语法:
select 查询列表
from 表1 别名 【连接类型】
join 表2 别名
on 连接条件
【where 筛选条件】
【group by 分组条件】
【having 筛选条件】
【order by 排序列表】 分类:
内连接☆: inner
外连接:
左外☆:left 【outer】
右外☆:rigth 【outer】
全外:full 【outer】
交叉连接:cross
内连接
等值连接
特点:
1、添加排序、分组、筛选
2、inner 可以省略
3、筛选条件放在where后面,连接条件放在on后面,提高分离性,便于阅读
4、inner join连接和sql92语法中的等值连接效果是一样的,都是查询多表的交集部分 案例1:查询员工名、部门名
select last_name,department_name from employees e inner join departments d on e.department_id=d.department_id;
案例2:查询名字中包含e的员工名和工种名(添加筛选)
select last_name,job_title from employees e inner join jobs j on e.job_id=j.job_id where e.last_name like '%e%';
案例3:查询部门个数>3的城市名和部门个数(添加分组+筛选)
select city,count(*) 部门个数 from departments d inner join locations l on d.location_id =l.location_id group by city having count(*)>3;
非等值连接
查询员工的工资级别
select salary,grade_level from employees e join job_grades g on e.salary between g.lowest_sal and g.highest_sal group by grade_level;
外链接
应用场景:用于查询一个表中有,另一个表中没有的记录
特点:
1、外连接的查询结果为主表中的所有记录
如果从表中有和他匹配的,则显示匹配的值
如果从表中没有和他匹配的,则显示null
外连接查询结果=内连接结果+主表中有而从表中没有的记录
2、左外连接:left join 左边的是主表
3、右外连接:right join 右边的是主表
4、左外连接和右外连接交换两个表的顺序实现的是相同的效果 案例1:查询男朋友不在男生表的女神名
select be.name from beauty be left join boys bo on be.boyfriend_id=be.id where bo.id is null;
子查询
含义:出现在其他语句中的select语句,成为子查询或内查询。外部的查询语句,称为主查询或外查询。
分类:
按子查询出现的位置:
select后面:
仅仅支持标量子查询
from后面:
支持表子查询
where或having后面:☆
标量子查询(单行)√
列子查询(多行)√
行子查询
exists后面(相关子查询)
表子查询
按结果集的行列数不同:
标量子查询(结果集只有一行一列)
列子查询(结果集只有一列多行)
行子查询(结果集有一行多列)
表子查询(结果集一般为多行多列)
where或having后面
1、标量子查询(单行子查询)
2、列子查询(多行子查询)
3、行子查询(多列多行)
特点:
①子查询放在小括号内
②子查询一般放到条件右侧
③标量子查询一般搭配着单行操作符使用>、<、=、>=、<=、<>
列子查询,一般搭配着多行操作符使用in、any、some、all
>any:只要比其中的任意的一个大即可,类似这种。
④子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果
#2.列子查询(多行子查询)★
#案例1:返回location_id是1400或1700的部门中的所有员工姓名 #①查询location_id是1400或1700的部门编号
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
#②查询员工姓名,要求部门号是①列表中的某一个
SELECT last_name
FROM employees
WHERE department_id <>ALL(
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
);
#3、行子查询(结果集一行多列或多行多列)
#案例:查询员工编号最小并且工资最高的员工信息
SELECT *
FROM employees
WHERE (employee_id,salary)=(
SELECT MIN(employee_id),MAX(salary)
FROM employees
);
#①查询最小的员工编号
SELECT MIN(employee_id)
FROM employees
#②查询最高工资
SELECT MAX(salary)
FROM employees
#③查询员工信息
SELECT *
FROM employees
WHERE employee_id=(
SELECT MIN(employee_id)
FROM employees
)AND salary=(
SELECT MAX(salary)
FROM employees
);
select后面
/*
仅仅支持标量子查询
*/
#案例:查询每个部门的员工个数
SELECT d.*,(
SELECT COUNT(*)
FROM employees e
WHERE e.department_id = d.`department_id`
) 个数
FROM departments d;
#案例2:查询员工号=102的部门名
SELECT (
SELECT department_name,e.department_id
FROM departments d
INNER JOIN employees e
ON d.department_id=e.department_id
WHERE e.employee_id=102
) 部门名;
from后面
/*
将子查询结果充当一张表,要求必须起别名
*/
#案例:查询每个部门的平均工资的工资等级
#①查询每个部门的平均工资
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id
#②连接①的结果集和job_grades表,筛选条件平均工资 between lowest_sal and highest_sal
SELECT ag_dep.*,g.`grade_level`
FROM (
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id
) ag_dep
INNER JOIN job_grades g
ON ag_dep.ag BETWEEN lowest_sal AND highest_sal;
exists后面(相关子查询)
/*
语法:
exists(完整的查询语句)
结果:1或0,如果是1说明有查询结果,如果是0说明没有查询结果。
*/
SELECT EXISTS(SELECT employee_id FROM employees WHERE salary=300000);
#案例1:查询有员工的部门名
#in
SELECT department_name
FROM departments d
WHERE d.`department_id` IN(
SELECT department_id
FROM employees
)
#exists
SELECT department_name
FROM departments d
WHERE EXISTS(
SELECT *
FROM employees e
WHERE d.`department_id`=e.`department_id`
);
#案例2:查询没有女朋友的男神信息
#in
SELECT bo.*
FROM boys bo
WHERE bo.id NOT IN(
SELECT boyfriend_id
FROM beauty
)
#exists
SELECT bo.*
FROM boys bo
WHERE NOT EXISTS(
SELECT boyfriend_id
FROM beauty b
WHERE bo.`id`=b.`boyfriend_id`
);
分页查询
/*
应用场景:当要显示的数据,一页显示不全,需要分页提交sql请求
语法:
select 查询列表
from
【join type join 表2
on 连接条件
where 筛选条件
group by 分组字段
having 分组后的筛选
order by 排序的字段】
limit 【offset,】size; offset要显示条目的起始索引(起始索引从0开始)
size 要显示的条目个数
特点:
①limit语句放在查询语句的最后
②公式
要显示的页数 page,每页的条目数size select 查询列表
from 表
limit (page-1)*size,size; size=10
page
1 0
2 10
3 20 */
#案例1:查询前五条员工信息
SELECT * FROM employees LIMIT 0,5;
SELECT * FROM employees LIMIT 5;
#案例2:查询第11条——第25条
SELECT * FROM employees LIMIT 10,15;
#案例3:有奖金的员工信息,并且工资较高的前10名显示出来
SELECT
*
FROM
employees
WHERE commission_pct IS NOT NULL
ORDER BY salary DESC
LIMIT 10 ;
联合查询
/*
union 联合 合并:将多条查询语句的结果合并成一个结果 语法:
查询语句1
union
查询语句2
union
... 应用场景:
要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时 特点:★
1、要求多条查询语句的查询列数是一致的!
2、要求多条查询语句的查询的每一列的类型和顺序最好一致
3、union关键字默认去重,如果使用union all 可以包含重复项
*/
#引入的案例:查询部门编号>90或邮箱包含a的员工信息
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;; SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90;
#案例:查询中国用户中男性的信息以及外国用户中年男性的用户信息
SELECT id,cname FROM t_ca WHERE csex='男'
UNION ALL
SELECT t_id,tname FROM t_ua WHERE tGender='male';
mysql-查询(DQL)的更多相关文章
- MySQL查询基础
MySQL查询 DQL(Data Query Language ) 1.排序查询 # 语法: select 字段 from 表名 order by 字段1 [降序/升序],字段2 [降序/升序],.. ...
- MySQL的DQL语言(查)
MySQL的DQL语言(查) DQL:Data Query Language,数据查询语言. DQL是数据库中最核心的语言,简单查询,复杂查询,都可以做,用select语句. 1. 查询指定表的全部字 ...
- mysql查询性能优化
mysql查询过程: 客户端发送查询请求. 服务器检查查询缓存,如果命中缓存,则返回结果,否则,继续执行. 服务器进行sql解析,预处理,再由优化器生成执行计划. Mysql调用存储引擎API执行优化 ...
- Mysql查询——深入学习
1.开篇 之前上一篇的随笔基本上是单表的查询,也是mysql查询的一个基本.接下来我们要看看两个表以上的查询如何得到我们想要的结果. 在学习的过程中我们一起进步,成长.有什么写的不对的还望可以指出. ...
- Mysql 查询练习
Mysql 查询练习 ---创建班级表 create table class( cid int auto_increment primary key, caption ) )engine=innodb ...
- mysql 查询去重 distinct
mysql 查询去重 distinct 待完善内容..
- MySQl查询区分大小写的解决办法
通过查询资料发现需要设置collate(校对) . collate规则: *_bin: 表示的是binary case sensitive collation,也就是说是区分大小写的 *_cs: ca ...
- 【转】mysql查询结果输出到文件
转自:http://www.cnblogs.com/emanlee/p/4233602.html mysql查询结果导出/输出/写入到文件 方法一: 直接执行命令: mysql> select ...
- MySQL查询缓存
MySQL查询缓存 用于保存MySQL查询语句返回的完整结果,被命中时,MySQL会立即返回结果,省去解析.优化和执行等阶段. 如何检查缓存? MySQL保存结果于缓存中: 把SELECT语句本身做h ...
- mysql 查询数据时按照A-Z顺序排序返回结果集
mysql 查询数据时按照A-Z顺序排序返回结果集 $sql = "SELECT * , ELT( INTERVAL( CONV( HEX( left( name, 1 ) ) , 16, ...
随机推荐
- 全新优化解决方案:Amplify Impostors
https://mp.weixin.qq.com/s/q6WPDHhMFk0jAMx937MLFg
- 转载 MySQL创建表的语句 示例
show variables like 'character_set_client';#查询字符集 show databases;#列出所有的服务器上的数据库alter create database ...
- Linux errno错误对照表
errno 在 <errno.h> 中定义,错误 Exx 的宏定义在 /usr/include/asm-generic 文件夹下面的 errno-base.h 和 errno.h,分别定 ...
- From表单提交刷新页面?
form表单提交跳转 写作原因: 楼主的html水平一般,偶然想起周围人常说的form表单提交会刷新页面,闲来无事,就想想其中的原因 想来想去为什么会刷新,猜想了以下几条 1.先提交数据,等服务器 ...
- spring中IOC容器注册和获取bean的实例
spring中常用的功能主要的是ioc和aop,此处主要说明下,实例注册和使用的方法,此为学习后的笔记记录总结 1.使用xml文件配置 在idea中创建maven工程,然后创建实例Person,然后在 ...
- 商品录入功能v1.0【持续优化中...】
# 录入商品 def goods_record(): print("欢迎使用铜锣辉的购物商城[商品管理][录入商品]".center(30, "*")) whi ...
- POJ1008 Maya Calendar
题目来源:http://poj.org/problem?id=1008 题目大意: Maya人认为一年有365天,但他们有两种日历.一种叫做Haab,有19个月.前18个月每月20天,每个月的名字分别 ...
- java程序员的从0到1:@Resource与@Autowired的比较
目录: 1.@Resource与@Autowired的源码分析 2.@Resource与@Autowired的相同点 3.@Resource与@Autowired的不同点 正文: 1.@Resourc ...
- 金融量化之tushare模块的使用
一.TuShare简介和环境安装 TuShare是一个著名的免费.开源的python财经数据接口包.其官网主页为:TuShare -财经数据接口包.该接口包如今提供了大量的金融数据,涵盖了股票.基本面 ...
- node js fcoin api 出现 api key check fail : {"status":1090,"msg":"Illegal API signature"}
//主区://ft / btc 不支持市价 买入数量不能小于5个FT 买//ft / eth 支持市价 最小买入eth不能小于0.01 买//ft / usdt 支持市价 最小买入usdt不能小于10 ...