cudnn 卷积例子
#include <iomanip>
#include <iostream>
#include <cstdlib>
#include <vector>
#include <stdio.h>
#include <cuda.h>
#include <cudnn_v7.h> #define CUDA_CALL(f) { \
cudaError_t err = (f); \
if (err != cudaSuccess) { \
std::cout \
<< " Error occurred: " << err << std::endl; \
std::exit(1); \
} \
} #define CUDNN_CALL(f) { \
cudnnStatus_t err = (f); \
if (err != CUDNN_STATUS_SUCCESS) { \
std::cout \
<< " Error occurred: " << err << std::endl; \
std::exit(1); \
} \
} __global__ void dev_const(float *px, float k) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
px[tid] = k;
} __global__ void dev_iota(float *px) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
px[tid] = tid;
} void print(const float *data, int n, int c, int h, int w) {
std::vector<float> buffer(1 << 20);
CUDA_CALL(cudaMemcpy(
buffer.data(), data,
n * c * h * w * sizeof(float),
cudaMemcpyDeviceToHost));
int a = 0;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < c; ++j) {
std::cout << "n=" << i << ", c=" << j << ":" << std::endl;
for (int k = 0; k < h; ++k) {
for (int l = 0; l < w; ++l) {
std::cout << std::setw(4) << std::right << buffer[a];
++a;
}
std::cout << std::endl;
}
}
}
std::cout << std::endl;
} int main() {
cudnnHandle_t cudnn;
CUDNN_CALL(cudnnCreate(&cudnn)); // input
const int in_n = 1;
const int in_c = 1;
const int in_h = 5;
const int in_w = 5;
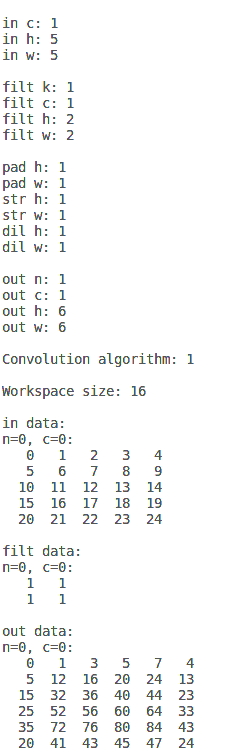
std::cout << "in_n: " << in_n << std::endl;
std::cout << "in_c: " << in_c << std::endl;
std::cout << "in_h: " << in_h << std::endl;
std::cout << "in_w: " << in_w << std::endl;
std::cout << std::endl; cudnnTensorDescriptor_t in_desc;
CUDNN_CALL(cudnnCreateTensorDescriptor(&in_desc));
CUDNN_CALL(cudnnSetTensor4dDescriptor(
in_desc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT,
in_n, in_c, in_h, in_w)); float *in_data;
CUDA_CALL(cudaMalloc(
&in_data, in_n * in_c * in_h * in_w * sizeof(float))); // filter
const int filt_k = 1;
const int filt_c = 1;
const int filt_h = 2;
const int filt_w = 2;
std::cout << "filt_k: " << filt_k << std::endl;
std::cout << "filt_c: " << filt_c << std::endl;
std::cout << "filt_h: " << filt_h << std::endl;
std::cout << "filt_w: " << filt_w << std::endl;
std::cout << std::endl; cudnnFilterDescriptor_t filt_desc;
CUDNN_CALL(cudnnCreateFilterDescriptor(&filt_desc));
CUDNN_CALL(cudnnSetFilter4dDescriptor(
filt_desc, CUDNN_DATA_FLOAT, CUDNN_TENSOR_NCHW,
filt_k, filt_c, filt_h, filt_w)); float *filt_data;
CUDA_CALL(cudaMalloc(
&filt_data, filt_k * filt_c * filt_h * filt_w * sizeof(float))); // convolution
const int pad_h = 1;
const int pad_w = 1;
const int str_h = 1;
const int str_w = 1;
const int dil_h = 1;
const int dil_w = 1;
std::cout << "pad_h: " << pad_h << std::endl;
std::cout << "pad_w: " << pad_w << std::endl;
std::cout << "str_h: " << str_h << std::endl;
std::cout << "str_w: " << str_w << std::endl;
std::cout << "dil_h: " << dil_h << std::endl;
std::cout << "dil_w: " << dil_w << std::endl;
std::cout << std::endl; cudnnConvolutionDescriptor_t conv_desc;
CUDNN_CALL(cudnnCreateConvolutionDescriptor(&conv_desc));
CUDNN_CALL(cudnnSetConvolution2dDescriptor(
conv_desc,
pad_h, pad_w, str_h, str_w, dil_h, dil_w,
CUDNN_CONVOLUTION, CUDNN_DATA_FLOAT)); // output
int out_n;
int out_c;
int out_h;
int out_w; CUDNN_CALL(cudnnGetConvolution2dForwardOutputDim(
conv_desc, in_desc, filt_desc,
&out_n, &out_c, &out_h, &out_w)); std::cout << "out_n: " << out_n << std::endl;
std::cout << "out_c: " << out_c << std::endl;
std::cout << "out_h: " << out_h << std::endl;
std::cout << "out_w: " << out_w << std::endl;
std::cout << std::endl; cudnnTensorDescriptor_t out_desc;
CUDNN_CALL(cudnnCreateTensorDescriptor(&out_desc));
CUDNN_CALL(cudnnSetTensor4dDescriptor(
out_desc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT,
out_n, out_c, out_h, out_w)); float *out_data;
CUDA_CALL(cudaMalloc(
&out_data, out_n * out_c * out_h * out_w * sizeof(float))); // algorithm
cudnnConvolutionFwdAlgo_t algo;
CUDNN_CALL(cudnnGetConvolutionForwardAlgorithm(
cudnn,
in_desc, filt_desc, conv_desc, out_desc,
CUDNN_CONVOLUTION_FWD_PREFER_FASTEST, 0, &algo)); std::cout << "Convolution algorithm: " << algo << std::endl;
std::cout << std::endl; // workspace
size_t ws_size;
CUDNN_CALL(cudnnGetConvolutionForwardWorkspaceSize(
cudnn, in_desc, filt_desc, conv_desc, out_desc, algo, &ws_size)); float *ws_data;
CUDA_CALL(cudaMalloc(&ws_data, ws_size)); std::cout << "Workspace size: " << ws_size << std::endl;
std::cout << std::endl; // perform
float alpha = 1.f;
float beta = 0.f;
dev_iota<<<in_w * in_h, in_n * in_c>>>(in_data);
dev_const<<<filt_w * filt_h, filt_k * filt_c>>>(filt_data, 1.f);
CUDNN_CALL(cudnnConvolutionForward(
cudnn,
&alpha, in_desc, in_data, filt_desc, filt_data,
conv_desc, algo, ws_data, ws_size,
&beta, out_desc, out_data)); // results
std::cout << "in_data:" << std::endl;
print(in_data, in_n, in_c, in_h, in_w); std::cout << "filt_data:" << std::endl;
print(filt_data, filt_k, filt_c, filt_h, filt_w); std::cout << "out_data:" << std::endl;
print(out_data, out_n, out_c, out_h, out_w); // finalizing
CUDA_CALL(cudaFree(ws_data));
CUDA_CALL(cudaFree(out_data));
CUDNN_CALL(cudnnDestroyTensorDescriptor(out_desc));
CUDNN_CALL(cudnnDestroyConvolutionDescriptor(conv_desc));
CUDA_CALL(cudaFree(filt_data));
CUDNN_CALL(cudnnDestroyFilterDescriptor(filt_desc));
CUDA_CALL(cudaFree(in_data));
CUDNN_CALL(cudnnDestroyTensorDescriptor(in_desc));
CUDNN_CALL(cudnnDestroy(cudnn));
return 0;
}
运行:
nvcc conv_cudnn.cu -lcudnn
./a.out
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">
cudnn 卷积例子的更多相关文章
- 由浅入深:CNN中卷积层与转置卷积层的关系
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由forrestlin发表于云+社区专栏 导语:转置卷积层(Transpose Convolution Layer)又称反卷积层或分数卷 ...
- SciPy模块应用
1.图像模糊 图像的高斯模糊是非常经典的图像卷积例子.本质上,图像模糊就是将(灰度)图像I 和一个高斯核进行卷积操作:,其中是标准差为σ的二维高斯核.高斯模糊通常是其他图像处理操作的一部分,比如图像 ...
- Python图像处理库(2)
1.4 SciPy SciPy(http://scipy.org/) 是建立在 NumPy 基础上,用于数值运算的开源工具包.SciPy 提供很多高效的操作,可以实现数值积分.优化.统计.信号处理,以 ...
- Python中的图像处理
第 1 章 基本的图像操作和处理 本章讲解操作和处理图像的基础知识,将通过大量示例介绍处理图像所需的 Python 工具包,并介绍用于读取图像.图像转换和缩放.计算导数.画图和保存结果等的基本工具.这 ...
- Convolutional Neural Networks 笔记
1 Foundations of Convolutional Neural Networks 1.1 cv问题 图像分类.目标检测.风格转换.但是高像素的图片会带来许多许多的特征. 1.2 边缘检测( ...
- TextCNN 代码详解(附测试数据集以及GitHub 地址)
前言:本篇是TextCNN系列的第三篇,分享TextCNN的优化经验 前两篇可见: 文本分类算法TextCNN原理详解(一) 一.textCNN 整体框架 1. 模型架构 图一:textCNN 模型结 ...
- 基本图像操作和处理(python)
基本图像操作和处理(python) PIL提供了通用的图像处理功能,以及大量的基本图像操作,如图像缩放.裁剪.旋转.颜色转换等. Matplotlib提供了强大的绘图功能,其下的pylab/pyplo ...
- Relay外部库使用
Relay外部库使用 本文介绍如何将cuDNN或cuBLAS等外部库与Relay一起使用. Relay内部使用TVM生成目标特定的代码.例如,使用cuda后端,TVM为用户提供的网络中的所有层生成cu ...
- CUDA 矩阵乘法终极优化指南
作者:马骏 | 旷视 MegEngine 架构师 前言 单精度矩阵乘法(SGEMM)几乎是每一位学习 CUDA 的同学绕不开的案例,这个经典的计算密集型案例可以很好地展示 GPU 编程中常用的优化技巧 ...
随机推荐
- 编辑器模式下如何实例化Prefab
当我们在EditMode下需要用脚本批量添加prefab时,可以用 PrefabUtility.InstantiatePrefab(prefab) as GameObject; 注意:如果用GameO ...
- hihoCoder#1037 : 数字三角形(DP)
[题目链接]:click here~~ 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 问题描写叙述 小Hi和小Ho在经历了螃蟹先生的任务之后被奖励了一次出国旅游的机会,于是他 ...
- Android-BroadcastReceiver具体解释
什么是Broadcast Broadcast即广播,在Android广播是很重要的功能.比如我们想在系统开机之后做某些事情.监控手机的电量.监控手机的网络状态等等.这些功能都须要用到广播.当然我们也能 ...
- 附004.Kubernetes Dashboard简介及使用
一 Kubernetes dashboard简介 1.1 Web UI简介 dashboard是基于Web的Kubernetes用户界面.可以使用dashboard将容器化应用程序部署到Kuberne ...
- 【BZOJ4375】Selling Tickets 随机化
[BZOJ4375]Selling Tickets Description 厨师在一次晚宴上准备了n道丰盛的菜肴,来自世界各地的m位顾客想要购买宴会的门票.每一位顾客都有两道特别喜爱的菜,而只要吃到了 ...
- MAC 脚本批量启动应用
1.touch batchStart.sh 2. #!/bin/bash cd /xxx open 1.app open 2.app 3.chmod +x batchStart.sh 4.ok
- Qt状态机框架(状态机就开始异步的运行了,也就是说,它成为了我们应用程序事件循环的一部分了)
状态机框架 Qt中的状态机框架为我们提供了很多的API和类,使我们能更容易的在自己的应用程序中集成状态动画.这个框架是和Qt的元对象系统机密结合在一起的.比如,各个状态之间的转换是通过信号触发的,状态 ...
- Django用ajax发送post请求时csrf拦截的解决方案
把下面的代码写在模版文件中就可以了, 注:不是js文件,是模版文件加载的执行的,所有写js里没效果 $.ajaxSetup({ data: {csrfmiddlewaretoken: '{{ csrf ...
- SAP内表转XML文件
今天有个兄弟问如何实现以XML的方式输出内表的内容,这个问题我以前好像没有写过.倒不是不会写,而是写的方法太多了,有极其简单的,也有很复杂的,而且网上资料也很多. 找到以前写的一个程序,稍微修改了一下 ...
- matlab 调用 python
众所周知,Python凭借其众多的第三方模块,近年来被数据分析.机器学习.深度学习等爱好者所喜爱,最主要的是Python还是开源的.另一方面,MATLAB因其在仿真方面的独特优势也被众多人追捧.而在国 ...