Spark目前支持三种开发语言:Scala、Java、Python,目前我们大量使用Python来开发Spark App(Spark 1.2开始支持使用Python开发Spark Streaming App,我们也准备尝试使用Python开发Spark Streaming App),在这期间关于数据类型的问题曾经困扰我们很长时间,故在此记录一下心路历程。
Spark是使用Scala语言开发的,Hadoop是使用Java语言开发的,Spark兼容Hadoop Writable,而我们使用Python语言开发Spark (Streaming) App,Spark Programming Guides(Spark 1.5.1)其中有一段文字说明了它们相互之间数据类型转换的关系:
也说是说,我们需要处理两个方向的转换:
(1)Writable => Java Type => Python Type;
(2)Python Type => Java Type => Writable;
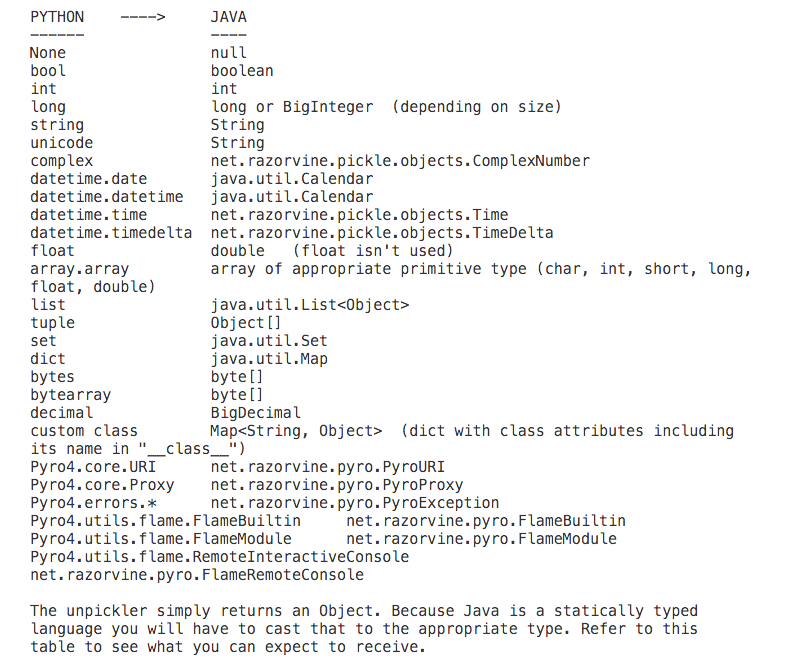
其中Java Type与Python Type之间数据类型的转换依赖开源组件Pyrolite,相应的数据类型转换如下:
(1)Python Type => Java Type;
(2)Java Type => Python Type;
也就是说,Pyrolite已经为Java Type与Python Type之间的数据类型转换建立了“标准”,我们仅仅需要处理Writable与Java Type之间的数据转换就可以了。
从上图“Writable Support”中可以看出PySpark已经为我们解决了常用的数据类型转换问题,但可以理解为“基本”数据类型,遇到复杂的情况,还是需要我们特殊处理,PySpark已经为我们考虑到了这种业务场景,为我们提供接口Converter(org.apache.spark.api.python.Converter),使得我们可以根据自己的需要扩展数据类型转换机制:
接口Converter仅仅只有一个方法convert,其中T表示源数据类型,U表示目标数据类型,参数obj表示源数据值,返回值表示目标数据值。
Spark Programming Guides(Spark 1.5.1)也为我们举例说明了一个需要自定义Converter的场景:
ArrayWritable是Hadoop Writable的一种,因为Array涉及到元素数据类型的问题,因此使用时需要实现相应的子类,如元素数据类型为整型:
从上面的描述可知,PySpark使用ArrayWritable时涉及到如下两个方向的数据类型转换:
(1)Tuple => Object[] => ArrayWritable;
(2)ArrayWritable => Object[] => Tuple;
我们以IntArrayWritable为例说明如何自定义扩展Converter,同理也需要处理两个方向的数据类型转换:Tuple => Object[] => ArrayWritable、ArrayWritable => Object[] => Tuple。
(1)Tuple => Object[] => IntArrayWritable;
假设我们有一个list,list的元素类型为tuple,而tuple的元素类型为int,我们需要将这个list中的所有数据以SequenceFile的形式保存至HDFS。对于list中的每一个元素tuple,Pyrolite可以帮助我们完成Tuple => Object[]的转换,而Object[] => IntArrayWritable则需要我们自定义Converter实现。
PySpark中使用这个Converter写入数据:
注意:SequenceFile的数据结构为<key, value>,为了简单起见,key指定为com.sina.dip.spark.converter.IntArrayWritable,value指定为org.apache.hadoop.io.NullWritable(即空值)。
运行上述程序时,因为有使用到我们自定义的类,因此需要将com.sina.dip.spark.converter.IntArrayWritable、com.sina.dip.spark.converter.ObjectArrayToIntArrayWritableConverter编译打包为独立的Jar:converter.jar,并通过参数指定,如下:
/usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-submit --jars converter.jar 1.5.1/examples/app/spark_app_save_data_to_seqfile.py
(2)IntArrayWritable => Object[] => Tuple;
我们需要将(1)中写入SequenceFile的Key(IntArrayWritable)还原为list,其中list的元素类型为tuple,tuple的元素类型为int,IntArrayWritable => Object[]也需要用到我们自定义的Converter(Object[] => Tuple由Pyrolite负责):
PySpark使用这个Converter读取数据:
同(1),我们需要将com.sina.dip.spark.converter.IntArrayWritable、com.sina.dip.spark.converter.IntArrayWritableToObjectArrayConverter编译打包为独立的Jar:converter.jar,并通过参数指定,如下:
/usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-submit --jars converter.jar 1.5.1/examples/app/spark_app_read_data_from_seqfile.py
输出结果:
可以看出,通过自定义扩展的Converter:com.sina.dip.spark.converter.ObjectArrayToIntArrayWritableConverter、com.sina.dip.spark.converter.IntArrayWritableToObjectArrayConverter,我们实现了IntArrayWritable(com.sina.dip.spark.converter.IntArrayWritable)与Tuple(Python)之间的转换。
- 开发板A/D转换原理
A/D转换器(Analog-to-Digital Converter)又叫模/数转换器,即使将模拟信(电压或是电流的形式)转换成数字信号.这种数字信号可让仪表,计算机外设接口或是微处理机来加以操作或是 ...
- adc转换原理
模数转换器即A/D转换器,或简称ADC,通常是指一个将模拟信号转变为数字信号的电子元件.通常的模数转换器是将一个输入电压信号转换为一个输出的数字信号.由于数字信号本身不具有实际意义,仅仅表示一个相对大 ...
- java学习笔记(3)数据类型、源码、反码、补码、精度损失、基本数据类型互相转换
关于java中的数据类型: 1.数据类型的作用是什么? 程序当中有很多数据,每一个数据都是有相关类型的,不同数据类型的数据占用的空间大小不同. 数据类型的作用是指导java虚拟机(JVM)在运行程序的 ...
- java中数据类型的转换
数据类型的转换,分为自动转换和强制转换. 自动转换是程序执行过程中“悄然”进行的转换,不需要用户提前声明,一般是从位数低的类型向位数高的类型转换 强制转换必须在代码中声明,转换顺序不受限制 自动数据类 ...
- Java的基本数据类型与转换
1.1 Java为什么需要保留基本数据类型 http://www.importnew.com/11915.html 基本数据类型对大多数业务相关或网络应用程序没有太大的用处,这些应用一般是采用客户端/ ...
- java的数据类型的转换
一:java的数据类型转换除布尔类型boolean(不能转换)有两种:<一> 自动转换: <二> 强制转换 <一>.自动转换:就是将小的数据类型自动转换成大的数据类 ...
- JavaScript学习笔记——数据类型强制转换和隐式转换
javascript数据类型强制转换 一.转换为数值类型 Number(参数) 把任何的类型转换为数值类型 A.如果是布尔值,false为0,true为1 B.如果是数字,转换成为本身.将无意义的后导 ...
- eclipse 提交作业到JobTracker Hadoop的数据类型要求必须实现Writable接口
问:在eclipse中的写的代码如何提交作业到JobTracker中的哪?答:(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法 connect() ...
- JAVA数据类型自动转换,与强制转换
一.数据类型自动转换 public class Test{ public static void main(String[] args){ int a = 1; double b = 1.5; dou ...
随机推荐
- DNS(域名系统)域名解析设置
DNS(Domain Name System,域名系统), 因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串.通过主机名,最 ...
- VS编译出现 HTTP 错误 403.14 - Forbidden 决绝办法
决绝办法: 运行cmd命令,在控制台面板计入Iis Express目录下.运行提示的的就可以了 appcmd set config /section:system.webServe ...
- mvc性能优化
mvc性能优化 (1)移动设备卡顿问题 -1请求方式 在mvc中GET请求有问题,出现错误 在MVC中在进行GET请求获取JSON数据时,需要进行如下设置: return Json("&qu ...
- PHP语言、浏览器、操作系统、IP、地理位置、ISP
)]; } else { $Isp = 'None'; } return $Isp; }}
- C++Primer学习笔记(二、基础)
1.两种初始化方式,直接初始化语法更灵活,且效率更高. ); // 直接初始化 direct-initialization ; // 赋值初始化 copy-initialization 2.const ...
- iOS 地图坐标系之间的转换WGS-84世界标准坐标、GCJ-02中国国测局(火星坐标,高德地图)、BD-09百度坐标系转换
开发过程中遇到地图定位不准确,存在偏差.首先确认你获取到的坐标所在坐标系跟地图数据是不是相匹配的. 常用的地图SDK:高德地图使用的是GCJ-02(也就是火星坐标系),百度使用的是BD-09百度坐标系 ...
- Node之express
Express 是一个简洁.灵活的 node.js Web 应用开发框架, 它提供一系列强大的特性,帮助你创建各种 Web 和移动设备应用. 如何安装: npm install -g express ...
- 上传图片预览 支持IE8+,FF,Chrome ,保留原图片比例
代码及效果:链接
- Android开源项目(转载)
第一部分 界面 ImageView.ProgressBar及其他如Dialog.Toast.EditText.TableView.Activity Animation等等. 一.ListView an ...
- ecshop 报错
ECShop出现Strict Standards: Only variables should be passed b (2014-06-04 17:00:37) 转载▼ 标签: ecshop 报错 ...