HBase官方文档 之 Region的相关知识
HBase是以Region为最小的存储和负载单元(这里可不是HDFS的存储单元),因此Region的负载管理,关系到了数据读写的性能。先抛开Region如何切分不说,看看Region是如何分配到各个RegionServer的吧。
更多内容参考——我的大数据学习之路
Region在HBase中的角色

Table (HBase表)
Region (Region)
Store (每个Region的每个列族独立存储)
MemStore (MemStore每个Store有一个,用于在内存中保存数据)
StoreFile (StoreFiles对应于Store,是具体存储在磁盘的文件)
Block (Blocks是HDFS上的存储单元)
Region的管理
一般来说对于每个Region Server,官方推荐最好是控制Region的数量在20-200个、大小在5-20Gb左右。
为什么要控制region的数量呢?
- 默认MemStore需要2MB的空间用来存储数据,如果一台机器上有1000个Region,每个有两个列族,那就需要3.9GB的数据。
- 如果同时以某个相同的频率更新所有的Region,当同时进行数据持久化的时候也会有问题
- Master对于维护大量的Region有很大的性能问题,因为在平衡Region的时候,在ZK中的操作都是同步的。
- Region Server需要维护Region的索引信息
那么Region Server是如何管理Region的呢?
启动
- Master创建AssignmentManager
- AssignmentManager查看当前的Region分配信息
- 满足条件后,通过LoadBalancerFactory创建LoadBalancer,1.0后的版本默认是StochasticLoadBalancer
- 判断是否需要进行负载平衡,并更新相关信息
容错
- 如果平衡负载的时候报错,RegionServer会直接关闭
- Master检测到resgion Server异常
- 重启Region server
- 请求进行重试;超时会请求其他的节点
Region的状态机
Hbase中每个Region自己维护其在hbase:meta表中的信息。
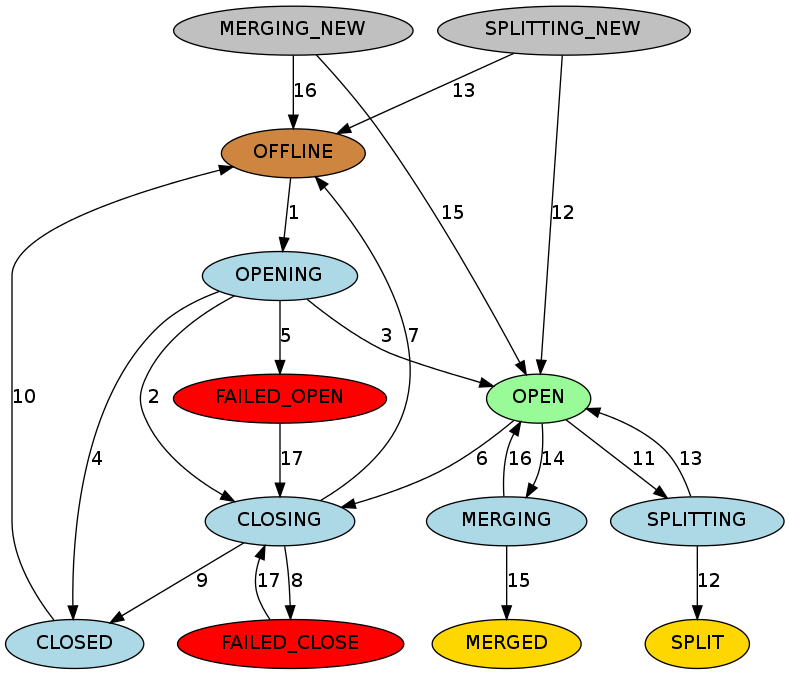
状态机中包括下面几种状态:
- offline:region离线没有开启
- opening:region正在被打开
- open:region正在打开,并且region server通知了master
- failed_open:regionserver打开失败
- closing:region正在被关闭
- closed:regionserver正在关闭,并且已经通知了master
- failed_close:regionserver关闭失败了
- splitting:region server通知master,region正在被切分
- split:region server通知master,region已经被切分完了
- spliting_new:region是切分过程中新建的文件
- merging:regionserver通知master region正在合并
- merged:regionserver通知master region合并完了
- merging_new:region是合并新建出来的
不同的颜色是不同含义:
- 棕色:离线状态,属于一种短暂的瞬间状态(比如关闭后开启的中间状态)、停止状态或者初始化的时候的状态
- 绿色:正常的状态,可以支持请求访问
- 蓝色:短暂的状态
- 红色:失败
- 黄色:合并或者切分的状态
- 灰色:刚开始的状态
各个序号代表不同的操作场景:
- Master向region server发起region从offline到openning的状态请求,regionserver如果没有收到,master会尝试重试几次。RegionServer接收到请求后,regin状态变成opening
- 如果Master发起的open请求超过次数,那么无论region server是否已经打开region,master都会命令region server关闭文件,状态变为closing
- 当region server打开region后,会尝试通知master,让他把region状态修改为open,并通知regsion server。这样region才能变为open状态
- 如果region server打开四百,会尝试通知master。master会把region的状态变更为closed,并且尝试去其他的region server打开region
- 如果master尝试几次后,都没有打开region,就会把状态变更为failed_open
- master通知region server关闭region,如果没有反应,会重试
- 如果region server没有在线,会抛出异常。然后region的状态会变成closing
- 如果region server在线,但是好几次都没响应,就会更新状态为failed_close
- 如果region server收到请求,并且关闭了region,那么会通知master把region状态修改为closed。并且把region分配给其他的server
- 在分配之前,master会先把region从closed状态转换为offline
- 如果region server正在切分region,会通知mastere。master把region状态由open变为splitting,并且把新增两个region的信息,这两个region都是splitting_new状态
- 如果region切分成功,当前的region状态从splitting变成split;新增的两个region状态从splitting_new变成open
- 如果切分失败,状态从splitting回到open,两个region也从splitting_new变成offline
- 如果region server想要合并两个region,那么也会先通知master。master把两个region从open变成merging,然后增加一个新的region,状态为merging_new
- 如果合并成功, 旧的region从merging变为merged,新的region从merging_new变为open
- 如果合并失败,region的状态从merging变回open,新建的一个region状态又变成offline
- 如果管理员通过hbase shell操作分配region,master会尝试把失败的状态变成close
Region的数据本地性
数据本地性通过来自于hdfs client和hdfs block存储的节点差异性,针对数据备份来说,会按照下面的机制进行:
- 第一个备份会优先卸载本地node节点上
- 第二个备份会随机选择一个不同的机架
- 第三个备份会在第二个备份所在的机架上,再随机选择一个节点
- 如果还有其他的备份节点,就在集群中随机选择了。
这样Hbase在刷新或者压缩时,可以体现数据的本地性。如果一个region server出现故障,那么就没有数据本地性可言了,因为它的备份都在其他的节点上。
Region的切分
HBase会配置一个切分的阈值,当到达阈值后,就会执行region的切分。Master不会参与Region的切分,切分由Region Server独立完成。执行切分的时候,会先把region下线,然后在meta表中增加子region的信息,最后通知给master。
默认使用的切分策略是IncreasingToUpperBoundRegionSplitPolicy(1.2.0版本),通过修改配置可以切换切分规则:
<property>
<name>hbase.regionserver.region.split.policy</name>
<value>org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy</value>
</property>
也可以通过Admin API指定规则:
HTableDescriptor tableDesc = new HTableDescriptor("test");
tableDesc.setValue(HTableDescriptor.SPLIT_POLICY, ConstantSizeRegionSplitPolicy.class.getName());
tableDesc.addFamily(new HColumnDescriptor(Bytes.toBytes("cf1")));
admin.createTable(tableDesc);
或者通过HBase shell管理:
hbase> create 'test', {METHOD => 'table_att', CONFIG => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy'}},
{NAME => 'cf1'}
也可以通过HBaseConfiguration来配置:
HTableDescriptor myHtd = ...;
myHtd.setValue(HTableDescriptor.SPLIT_POLICY, MyCustomSplitPolicy.class.getName());
Region的手动切分
Region的切分可以在表创建的时候来执行,也可已在后期来做。最好是在设计表结构的时候,就把切分的规则考虑进去。因为:
- 如果你的数据rowkey是随着时间自增长的,那么所有的新数据都会写在最后一个Region中,这样会导致总是最后一个region是热点,而其他的所有region基本都闲置了。
- 有的时候是一些意外的情况导致的热点问题,比如table中存储的是每个网页对应的点击日志,如果一个网页很受欢迎,那么它对应的region将会成为热点。
- 当集群的region很多的时候,想要加快加载数据的速度
- 在批量导入的时候,可能会造成region热点写
设计切分点
默认HBase都是基于Rowkey的字符进行切分的。如果rowkey是通过数字开头,那么会按照数字的范围进行切分;如果是字母,则会通过它的ASCII码进行切分。用户也可以自定义切分的算法,比如HexStringSplit通过转换成十六进制进行切分。
Region的合并
Master和RegionServer都会参与Region的合并。一般是Client发送合并的请求到Master,然后Master把需要合并的region移动到需要移动比例最高的那个Regsion Server上。比如现在有ABC3个Region Server,A有2个Region,B和C都只有一个,那么会把Region都转移到A Server,再执行合并操作。跟切分的过程一样,也需要先将region设置离线,然后执行合并,再去更新meta表信息。
下面是Hbase shell中合并的例子:
$ hbase> merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME'
$ hbase> merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME', true
合并操作是异步操作,发送请求后,客户端这边不需要登到合并结束。
第三个参数,表示是否强制合并。因为默认合并操作只能针对相邻的region,force参数可以强制跨Region的合并。
HBase官方文档 之 Region的相关知识的更多相关文章
- hbase官方文档(转)
FROM:http://www.just4e.com/hbase.html Apache HBase™ 参考指南 HBase 官方文档中文版 Copyright © 2012 Apache Soft ...
- HBase官方文档
HBase官方文档 目录 序 1. 入门 1.1. 介绍 1.2. 快速开始 2. Apache HBase (TM)配置 2.1. 基础条件 2.2. HBase 运行模式: 独立和分布式 2.3. ...
- HBase 官方文档
HBase 官方文档 Copyright © 2010 Apache Software Foundation, 盛大游戏-数据仓库团队-颜开(译) Revision History Revision ...
- HBase 官方文档0.90.4
HBase 官方文档0.90.4 Copyright © 2010 Apache Software Foundation, 盛大游戏-数据仓库团队-颜开(译) Revision History Rev ...
- hBase官方文档以及HBase基础操作封装类
HBase 官方文档 0.97 http://abloz.com/hbase/book.html HBase基本操作封装类(以课堂爬虫为例) package cn.crxy.spider.utils; ...
- HBase 官方文档中文版
地址链接: http://abloz.com/hbase/book.html 里面包含基本的API和使用说明
- Android 线性布局(LinearLayout)相关官方文档 - 指南部分
Android 线性布局(LinearLayout)相关官方文档 - 指南部分 太阳火神的漂亮人生 (http://blog.csdn.net/opengl_es) 本文遵循"署名-非商业用 ...
- Android 线性布局(LinearLayout)相关官方文档 - 布局參数部分
Android 线性布局(LinearLayout)相关官方文档 - 布局參数部分 太阳火神的漂亮人生 (http://blog.csdn.net/opengl_es) 本文遵循"署名-非商 ...
- Spark官方文档 - 中文翻译
Spark官方文档 - 中文翻译 Spark版本:1.6.0 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 引入Spark(Linki ...
随机推荐
- python实现简单登陆流程
登陆流程图: 代码实现: #-*- coding=utf-8 -*- import os,sys,getpass ''' user.txt 格式 账号 密码 是否锁定 错误次数 jack 123 un ...
- 为cobbler自动化安装系统工具添加epel源
关于cobbler的安装及部署,参考:CentOS 6.5自动化运维之基于cobbler服务的自动化安装操作系统详解http://blog.csdn.net/reblue520/article/det ...
- 火狐mozilla官方ftp站点获取旧版本火狐的下载地址
http://ftp.mozilla.org/pub/firefox/releases/
- 搭建ssh框架项目(四)
一.创建控制层 (1)创建VO值对象,对应页面表单的属性值 package com.cppdy.ssh.web.form; /** * VO值对象,对应页面表单的属性值 * VO对象与PO对象的关系: ...
- hdu1423LCIS zoj2432 必须掌握!
LCIS就是最长上升公共子序列,要结合LIS和LCS来求 LIS:f[j]=max(f[i])+1; LCS:f[i,j]=max(f[i-1,j],f[i,j-1]或f[i-1,j-1]+1 那么对 ...
- Redis 5.0 集群搭建
Redis 5.0 集群搭建 单机版的 Redis 搭建 https://www.jianshu.com/p/b68e68bbd725 /usr/local/目录 mkdir redis-cluste ...
- 将SublimeText 添加到鼠标右键的方法
- 在vim中注释多行
使用查找替换的方法 在linux中,文本每一行的起始标志是^,结束标志为$,因此使用vim搜索^并替换为^#即可. :10,20s/^/#/g 表示将10-20行添加注释,同理取消注释为: :10,2 ...
- 鼠标hover元素scale/zoom中心点放大效果实例页面
CSS代码: .box { /* 可见视觉区域 */ width: 480px; height: 250px; position: relative; overflow: hidden; cursor ...
- 【Java】 剑指offer(33) 二叉搜索树的后序遍历序列
本文参考自<剑指offer>一书,代码采用Java语言. 更多:<剑指Offer>Java实现合集 题目 输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果.如 ...