kafka系列八、kafka消息重复和丢失的场景及解决方案分析
消息重复和丢失是kafka中很常见的问题,主要发生在以下三个阶段:
- 生产者阶段
- broke阶段
- 消费者阶段
一、生产者阶段重复场景
1、根本原因
生产发送的消息没有收到正确的broke响应,导致producer重试。
producer发出一条消息,broke落盘以后因为网络等种种原因发送端得到一个发送失败的响应或者网络中断,然后producer收到一个可恢复的Exception重试消息导致消息重复。
2、重试过程
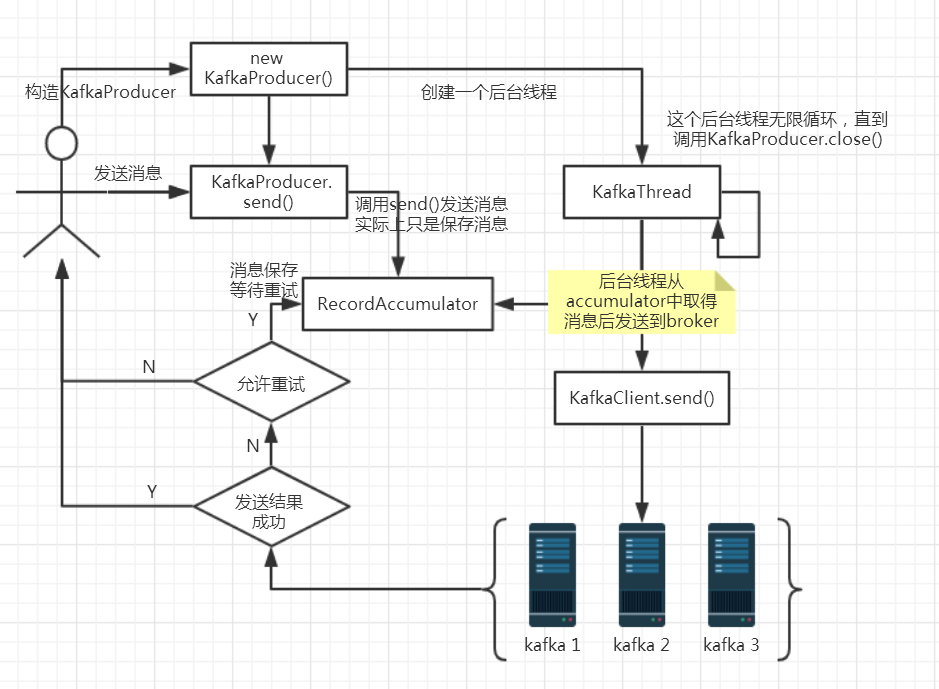
说明:
1. new KafkaProducer()后创建一个后台线程KafkaThread扫描RecordAccumulator中是否有消息;
2. 调用KafkaProducer.send()发送消息,实际上只是把消息保存到RecordAccumulator中;
3. 后台线程KafkaThread扫描到RecordAccumulator中有消息后,将消息发送到kafka集群;
4. 如果发送成功,那么返回成功;
5. 如果发送失败,那么判断是否允许重试。如果不允许重试,那么返回失败的结果;如果允许重试,把消息再保存到RecordAccumulator中,等待后台线程KafkaThread扫描再次发送;
3、可恢复异常说明
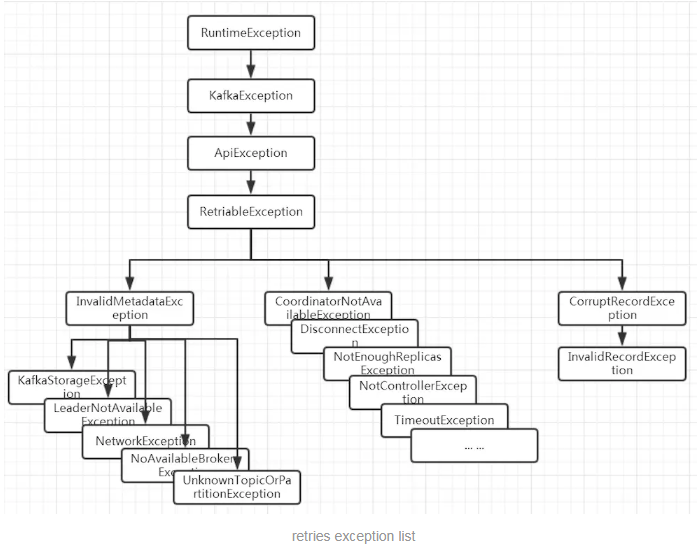
异常是RetriableException类型或者TransactionManager允许重试;RetriableException类继承关系如下:
4、记录顺序问题
如果设置max.in.flight.requests.per.connection大于1(默认5,单个连接上发送的未确认请求的最大数量,表示上一个发出的请求没有确认下一个请求又发出了)。大于1可能会改变记录的顺序,因为如果将两个batch发送到单个分区,第一个batch处理失败并重试,但是第二个batch处理成功,那么第二个batch处理中的记录可能先出现被消费。
设置max.in.flight.requests.per.connection为1,可能会影响吞吐量,可以解决单台producer发送顺序问题。如果多个producer,producer1先发送一个请求,producer2后发送请求,这是producer1返回可恢复异常,重试一定次数成功了。虽然时producer1先发送消息,但是producer2发送的消息会被先消费。
二、生产者发送重复解决方案
1、启动kafka的幂等性
要启动kafka的幂等性,无需修改代码,默认为关闭,需要修改配置文件:enable.idempotence=true 同时要求 ack=all 且 retries>1。
幂等原理:
每个producer有一个producer id,服务端会通过这个id关联记录每个producer的状态,每个producer的每条消息会带上一个递增的sequence,服务端会记录每个producer对应的当前最大sequence,producerId + sequence ,如果新的消息带上的sequence不大于当前的最大sequence就拒绝这条消息,如果消息落盘会同时更新最大sequence,这个时候重发的消息会被服务端拒掉从而避免消息重复。该配置同样应用于kafka事务中。
2、ack=0,不重试。
可能会丢消息,适用于吞吐量指标重要性高于数据丢失,例如:日志收集。
三、生产者和broke阶段消息丢失场景
1、ack=0,不重试
producer发送消息完,不管结果了,如果发送失败也就丢失了。
2、ack=1,leader crash
producer发送消息完,只等待lead写入成功就返回了,leader crash了,这时follower没来及同步,消息丢失。
3、unclean.leader.election.enable 配置true
允许选举ISR以外的副本作为leader,会导致数据丢失,默认为false。producer发送异步消息完,只等待lead写入成功就返回了,leader crash了,这时ISR中没有follower,leader从OSR中选举,因为OSR中本来落后于Leader造成消息丢失。
四、生产者和broke阶段消息丢失解决方案
1、配置:ack=all / -1,tries > 1,unclean.leader.election.enable : false
producer发送消息完,等待ollower同步完再返回,如果异常则重试。这是副本的数量可能影响吞吐量,最大不超过5个,一般三个足够了。
不允许选举ISR以外的副本作为leader。
2、配置:min.insync.replicas > 1
当producer将acks设置为“all”(或“-1”)时,min.insync。副本指定必须确认写操作成功的最小副本数量。如果不能满足这个最小值,则生产者将引发一个异常(要么是NotEnoughReplicas,要么是NotEnoughReplicasAfterAppend)。
当一起使用时,min.insync.replicas和ack允许执行更大的持久性保证。一个典型的场景是创建一个复制因子为3的主题,设置min.insync复制到2个,用“all”配置发送。将确保如果大多数副本没有收到写操作,则生产者将引发异常。
3、失败的offset单独记录
producer发送消息,会自动重试,遇到不可恢复异常会抛出,这时可以捕获异常记录到数据库或缓存,进行单独处理。
五、消费者数据重复场景及解决方案
1、根本原因
数据消费完没有及时提交offset到broke。
2、场景
消息消费端在消费过程中挂掉没有及时提交offset到broke,另一个消费端启动拿之前记录的offset开始消费,由于offset的滞后性可能会导致新启动的客户端有少量重复消费。
3、解决方案
1、取消自动自动提交
每次消费完或者程序退出时手动提交。这可能也没法保证一条重复。
2、下游做幂等
一般的解决方案是让下游做幂等或者尽量每消费一条消息都记录offset,对于少数严格的场景可能需要把offset或唯一ID,例如订单ID和下游状态更新放在同一个数据库里面做事务来保证精确的一次更新或者在下游数据表里面同时记录消费offset,然后更新下游数据的时候用消费位点做乐观锁拒绝掉旧位点的数据更新。
kafka系列八、kafka消息重复和丢失的场景及解决方案分析的更多相关文章
- Java 集合系列 07 List总结(LinkedList, ArrayList等使用场景和性能分析)
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Kafka系列之-Kafka Protocol实例分析
本文基于A Guide To The Kafka Protocol文档,以及Spark Streaming中实现的org.apache.spark.streaming.kafka.KafkaClust ...
- Kafka系列之-Kafka监控工具KafkaOffsetMonitor配置及使用
KafkaOffsetMonitor是一个可以用于监控Kafka的Topic及Consumer消费状况的工具,其配置和使用特别的方便.源项目Github地址为:https://github.com/q ...
- Kafka系列之-Kafka入门
接下来的这些博客,主要内容来自<Learning Apache Kafka Second Edition>这本书,书不厚,200多页.接下来摘录出本书中的重要知识点,偶尔参考一些网络资料, ...
- Kafka系列二 kafka相关问题理解
1.kafka是什么 类JMS消息队列,结合JMS中的两种模式,可以有多个消费者主动拉取数据,在JMS中只有点对点模式才有消费者主动拉取数据. kafka是一个生产-消费模型. producer:生产 ...
- Apache Kafka系列(七)Kafka Repartition操作
Kafka提供了重新分区的命令,但是只能增加,不能减少 我的kafka安装在/usr/local/kafka_2.12-1.0.2目录下面, [root@i-zk1 kafka_2.-]# bin/k ...
- Apache Kafka系列(五) Kafka Connect及FileConnector示例
Apache Kafka系列(一) 起步 Apache Kafka系列(二) 命令行工具(CLI) Apache Kafka系列(三) Java API使用 Apache Kafka系列(四) 多线程 ...
- Kafka系列文章
Kafka系列文章 Kafka设计解析(一)- Kafka背景及架构介绍 Kafka设计解析(二)- Kafka High Availability (上) Kafka设计解析(三)- Kafka H ...
- Kafka在高并发的情况下,如何避免消息丢失和消息重复?kafka消费怎么保证数据消费一次?数据的一致性和统一性?数据的完整性?
1.kafka在高并发的情况下,如何避免消息丢失和消息重复? 消息丢失解决方案: 首先对kafka进行限速, 其次启用重试机制,重试间隔时间设置长一些,最后Kafka设置acks=all,即需要相应的 ...
随机推荐
- BZOJ 5308 [ZJOI2018] Day2T2 胖 | 二分 ST表
题目链接 LOJ 2529 BZOJ 5308 题解 这么简单的题 为什么考场上我完全想不清楚 = = 对于k个关键点中的每一个关键点\(a\),二分它能一度成为哪些点的最短路起点(显然这些点在一段包 ...
- Office web apps 打补丁后(安装PDF在线浏览) 错误解决
最近为了能让PDF在线review,所以安装了460287_intl_x64_zip.exe 这个OWA的hotfix, 安装后,发现OWA挂了,一段搜索之后,发现要重新配置OWA: 1. 在 ...
- (转)JVM——自定义类加载器
背景:为什么要自定义,如何自定义,实现过程 转载:http://blog.csdn.net/SEU_Calvin/article/details/52315125 0. 为什么需要自定义类加载器 网上 ...
- SQL Server 操作XML数据
.xml.exist 输入为XQuery表达式,返回0,1或是Null.0表示不存在,1表示存在,Null表示输入为空 .xml.value 输入为XQuery表达式,返回一个SQL Server标量 ...
- 关于表单----html杂记
前言:总结了一些关于表单的东西,发下内心的感慨,以前感觉自己什么都会,今天竟然连最基本的表单的东西都忘了,好丢人, 学习的过程中,切勿眼高手低,一定要做好自己的笔记,然后多写代码,多想为什么,我比较笨 ...
- Cookie浅谈
相信大家对Cookie多多少少都有点了解吧~~下面我来谈谈吧: 每个Cookie不超过4K数据,每个网站不超过20个Cookie,所有网站的Cookie总和不超过300个 虽然cookie已经是上世纪 ...
- Hadoop生态圈-CDH与HUE使用案例
Hadoop生态圈-CDH与HUE使用案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HUE的介绍 1>.HUE的由来 HUE全称是HadoopUser Experi ...
- free命令常用参数详解
free命令常用参数详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在运维期间我们会经常去查看服务器硬件信息,比如说内存,大家可能知道看内存用“[root@yinzhengji ...
- Java中Dom解析XML
DOM将整个XML文件加载到内存中,并构建出节点树:应用程序可以通过遍历节点树的方式来解析XML文件中的各个节点.属性等信息:这种方式便于对XML节点的添加修改等,而且解析也很方便,然后它比较耗费内存 ...
- Nginx的alias的用法及与root的区别
以前只知道Nginx的location块中的root用法,用起来总是感觉满足不了自己的一些想法.然后终于发现了alias这个东西. 先看toot的用法 location /request_path/i ...