Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三十):使用flatMapGroupsWithState替换agg
flatMapGroupsWithState的出现解决了什么问题:
flatMapGroupsWithState的出现在spark structured streaming原因(从spark.2.2.0开始才开始支持):
1)可以实现agg函数;
2)就目前最新spark2.3.2版本来说在spark structured streming中依然不支持对dataset多次agg操作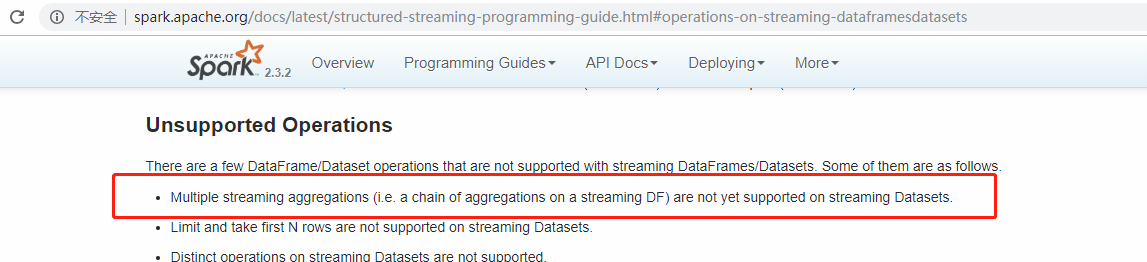
,而flatMapGroupsWithState可以替代agg的作用,同时它允许在sink为append模式下在agg之前使用。
注意:尽管允许agg之前使用,但前提是:输出(sink)方式Append方式。

flatMapGroupsWithState的使用示例(从网上找到):
参考:《https://jaceklaskowski.gitbooks.io/spark-structured-streaming/spark-sql-streaming-KeyValueGroupedDataset-flatMapGroupsWithState.html》
说明:以下示例代码实现了“select deviceId,count(0) as count from tbName group by deviceId.”。
1)spark2.3.0版本下定义一个Signal实体类:
scala> spark.version
res0: String = 2.3.0-SNAPSHOT import java.sql.Timestamp
type DeviceId = Int
case class Signal(timestamp: java.sql.Timestamp, value: Long, deviceId: DeviceId)
2)使用Rate source方式生成一些测试数据(随机实时流方式),并查看执行计划:
// input stream
import org.apache.spark.sql.functions._
val signals = spark.
readStream.
format("rate").
option("rowsPerSecond", 1).
load.
withColumn("value", $"value" % 10). // <-- randomize the values (just for fun)
withColumn("deviceId", rint(rand() * 10) cast "int"). // <-- 10 devices randomly assigned to values
as[Signal] // <-- convert to our type (from "unpleasant" Row)
scala> signals.explain
== Physical Plan ==
*Project [timestamp#0, (value#1L % 10) AS value#5L, cast(ROUND((rand(4440296395341152993) * 10.0)) as int) AS deviceId#9]
+- StreamingRelation rate, [timestamp#0, value#1L]
3)对Rate source流对象进行groupBy,使用flatMapGroupsWithState实现agg
// stream processing using flatMapGroupsWithState operator
val device: Signal => DeviceId = { case Signal(_, _, deviceId) => deviceId }
val signalsByDevice = signals.groupByKey(device) import org.apache.spark.sql.streaming.GroupState
type Key = Int
type Count = Long
type State = Map[Key, Count]
case class EventsCounted(deviceId: DeviceId, count: Long)
def countValuesPerKey(deviceId: Int, signalsPerDevice: Iterator[Signal], state: GroupState[State]): Iterator[EventsCounted] = {
val values = signalsPerDevice.toList
println(s"Device: $deviceId")
println(s"Signals (${values.size}):")
values.zipWithIndex.foreach { case (v, idx) => println(s"$idx. $v") }
println(s"State: $state") // update the state with the count of elements for the key
val initialState: State = Map(deviceId -> 0)
val oldState = state.getOption.getOrElse(initialState)
// the name to highlight that the state is for the key only
val newValue = oldState(deviceId) + values.size
val newState = Map(deviceId -> newValue)
state.update(newState) // you must not return as it's already consumed
// that leads to a very subtle error where no elements are in an iterator
// iterators are one-pass data structures
Iterator(EventsCounted(deviceId, newValue))
}
import org.apache.spark.sql.streaming.{GroupStateTimeout, OutputMode} val signalCounter = signalsByDevice.flatMapGroupsWithState(
outputMode = OutputMode.Append,
timeoutConf = GroupStateTimeout.NoTimeout)(func = countValuesPerKey)
4)使用Console Sink方式打印agg结果:
import org.apache.spark.sql.streaming.{OutputMode, Trigger}
import scala.concurrent.duration._
val sq = signalCounter.
writeStream.
format("console").
option("truncate", false).
trigger(Trigger.ProcessingTime(10.seconds)).
outputMode(OutputMode.Append).
start
5)console print
...
-------------------------------------------
Batch:
-------------------------------------------
+--------+-----+
|deviceId|count|
+--------+-----+
+--------+-----+
...
// :: INFO StreamExecution: Streaming query made progress: {
"id" : "a43822a6-500b-4f02-9133-53e9d39eedbf",
"runId" : "79cb037e-0f28-4faf-a03e-2572b4301afe",
"name" : null,
"timestamp" : "2017-08-21T06:57:26.719Z",
"batchId" : ,
"numInputRows" : ,
"processedRowsPerSecond" : 0.0,
"durationMs" : {
"addBatch" : ,
"getBatch" : ,
"getOffset" : ,
"queryPlanning" : ,
"triggerExecution" : ,
"walCommit" :
},
"stateOperators" : [ {
"numRowsTotal" : ,
"numRowsUpdated" : ,
"memoryUsedBytes" :
} ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=8]",
"startOffset" : null,
"endOffset" : ,
"numInputRows" : ,
"processedRowsPerSecond" : 0.0
} ],
"sink" : {
"description" : "ConsoleSink[numRows=20, truncate=false]"
}
}
// :: DEBUG StreamExecution: batch committed
...
-------------------------------------------
Batch:
-------------------------------------------
Device:
Signals ():
. Signal(-- ::27.682,,)
State: GroupState(<undefined>)
Device:
Signals ():
. Signal(-- ::26.682,,)
State: GroupState(<undefined>)
Device:
Signals ():
. Signal(-- ::28.682,,)
State: GroupState(<undefined>)
+--------+-----+
|deviceId|count|
+--------+-----+
| | |
| | |
| | |
+--------+-----+
...
// :: INFO StreamExecution: Streaming query made progress: {
"id" : "a43822a6-500b-4f02-9133-53e9d39eedbf",
"runId" : "79cb037e-0f28-4faf-a03e-2572b4301afe",
"name" : null,
"timestamp" : "2017-08-21T06:57:30.004Z",
"batchId" : ,
"numInputRows" : ,
"inputRowsPerSecond" : 0.91324200913242,
"processedRowsPerSecond" : 2.2388059701492535,
"durationMs" : {
"addBatch" : ,
"getBatch" : ,
"getOffset" : ,
"queryPlanning" : ,
"triggerExecution" : ,
"walCommit" :
},
"stateOperators" : [ {
"numRowsTotal" : ,
"numRowsUpdated" : ,
"memoryUsedBytes" :
} ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=8]",
"startOffset" : ,
"endOffset" : ,
"numInputRows" : ,
"inputRowsPerSecond" : 0.91324200913242,
"processedRowsPerSecond" : 2.2388059701492535
} ],
"sink" : {
"description" : "ConsoleSink[numRows=20, truncate=false]"
}
}
// :: DEBUG StreamExecution: batch committed
...
-------------------------------------------
Batch:
-------------------------------------------
Device:
Signals ():
. Signal(-- ::36.682,,)
State: GroupState(<undefined>)
Device:
Signals ():
. Signal(-- ::32.682,,)
. Signal(-- ::35.682,,)
State: GroupState(Map( -> ))
Device:
Signals ():
. Signal(-- ::34.682,,)
State: GroupState(<undefined>)
Device:
Signals ():
. Signal(-- ::29.682,,)
State: GroupState(<undefined>)
Device:
Signals ():
. Signal(-- ::31.682,,)
. Signal(-- ::33.682,,)
State: GroupState(Map( -> ))
Device:
Signals ():
. Signal(-- ::30.682,,)
. Signal(-- ::37.682,,)
State: GroupState(Map( -> ))
Device:
Signals ():
. Signal(-- ::38.682,,)
State: GroupState(<undefined>)
+--------+-----+
|deviceId|count|
+--------+-----+
| | |
| | |
| | |
| | |
| | |
| | |
| | |
+--------+-----+
...
// :: INFO StreamExecution: Streaming query made progress: {
"id" : "a43822a6-500b-4f02-9133-53e9d39eedbf",
"runId" : "79cb037e-0f28-4faf-a03e-2572b4301afe",
"name" : null,
"timestamp" : "2017-08-21T06:57:40.005Z",
"batchId" : ,
"numInputRows" : ,
"inputRowsPerSecond" : 0.9999000099990002,
"processedRowsPerSecond" : 9.242144177449168,
"durationMs" : {
"addBatch" : ,
"getBatch" : ,
"getOffset" : ,
"queryPlanning" : ,
"triggerExecution" : ,
"walCommit" :
},
"stateOperators" : [ {
"numRowsTotal" : ,
"numRowsUpdated" : ,
"memoryUsedBytes" :
} ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=8]",
"startOffset" : ,
"endOffset" : ,
"numInputRows" : ,
"inputRowsPerSecond" : 0.9999000099990002,
"processedRowsPerSecond" : 9.242144177449168
} ],
"sink" : {
"description" : "ConsoleSink[numRows=20, truncate=false]"
}
}
// :: DEBUG StreamExecution: batch committed // In the end...
sq.stop // Use stateOperators to access the stats
scala> println(sq.lastProgress.stateOperators().prettyJson)
{
"numRowsTotal" : ,
"numRowsUpdated" : ,
"memoryUsedBytes" :
}
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三十):使用flatMapGroupsWithState替换agg的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十五)Spark编写UDF、UDAF、Agg函数
Spark Sql提供了丰富的内置函数让开发者来使用,但实际开发业务场景可能很复杂,内置函数不能够满足业务需求,因此spark sql提供了可扩展的内置函数. UDF:是普通函数,输入一个或多个参数, ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十六)Structured Streaming中ForeachSink的用法
Structured Streaming默认支持的sink类型有File sink,Foreach sink,Console sink,Memory sink. ForeachWriter实现: 以写 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十四)定义一个avro schema使用comsumer发送avro字符流,producer接受avro字符流并解析
参考<在Kafka中使用Avro编码消息:Consumer篇>.<在Kafka中使用Avro编码消息:Producter篇> 在了解如何avro发送到kafka,再从kafka ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十八)ES6.2.2 增删改查基本操作
#文档元数据 一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息. 三个必须的元数据元素如下:## _index 文档在哪存放 ## _type 文档表示的对象类别 ## ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
随机推荐
- 利用HTML5开发Android
● Android设备多分辨率的问题 Android浏览器默认预览模式浏览 会缩小页面 WebView中则会以原始大小显示 Android浏览器和WebView默认为mdpi.hdpi相当于mdpi的 ...
- python 全栈开发,Day47(行级块级标签,高级选择器,属性选择器,伪类选择器,伪元素选择器,css的继承性和层叠性,层叠性权重相同处理,盒模型,padding,border,margin)
一.HTML中的行级标签和块级标签 块级标签 常见的块级标签:div,p,h1-h6,ul,li,dl,dt,dd 1.独占一行,不和其他元素待在同一行2.能设置宽高3.如果不设置宽高,默认为body ...
- 步步为营-70-asp.net简单练习(文件的上传和下载)
大文件的上传一般通过FTP协议,而一般小的文件可以通过http协议来完成 1 通过asp.net 完成图片的上传 1.1 创建html页面 注意:1 method="post" ; ...
- 【ioi2011】Dancing elephants
题解: 这题是lct并不难想 关键在于如何建图 如果把每个大象连向第一个不能处理的大象 那么cut操作要删除的就是一个点而不是边 所以可以采用先离散化, 之后对于存在的大象,用边连向第一个不能处理的大 ...
- KNN分类算法补充
KNN补充: 1.K值设定为多大? k太小,分类结果易受噪声点影响:k太大,近邻中又可能包含太多的其它类别的点. (对距离加权,可以降低k值设定的影响) k值通常是采用交叉检验来确定(以k=1为基准) ...
- 基于kubernetes集群部署DashBoard
目录贴:Kubernetes学习系列 在之前一篇文章:Centos7部署Kubernetes集群,中已经搭建了基本的K8s集群,本文将在此基础之上继续搭建K8s DashBoard. 1.yaml文件 ...
- BZOJ1146 [CTSC2008]网络管理Network 树链剖分 主席树 树状数组
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - BZOJ1146 题意概括 在一棵树上,每一个点一个权值. 有两种操作: 1.单点修改 2.询问两点之间的树链 ...
- Linux命令02--系统管理
<1>查看当前日历:cal <2>显示或者设置时间 设置时间格式(需要管理员权限):一般都是有ntp服务的,你的系统会根据这个对照互联网时间 <3>查看进程信息:p ...
- 洛谷 P1141【BFS】+记忆化搜索+染色
题目链接:https://www.luogu.org/problemnew/show/P1141 题目描述 有一个仅由数字 0 与 1 组成的n×n 格迷宫.若你位于一格0上,那么你可以移动到相邻 4 ...
- 【Java】基本I/O的学习总结
计算机I/O 理解IO先要知道计算机对数据的输入输出是怎么处理的,下面一张图可以大致理解: 可以看出所谓输入是外部数据向CPU输入,而输出是CPU将数据输出到我们可见的地方,例如文件.屏幕等.而计算机 ...