multi-head attention
■ 论文 | Attention Is All You Need
■ 链接 | https://www.paperweekly.site/papers/224
■ 源码 | https://github.com/Kyubyong/transformer
■ 论文 | Weighted Transformer Network for Machine Translation
■ 链接 | https://www.paperweekly.site/papers/2013
■ 源码 | https://github.com/JayParks/transformer
思想:舍弃 RNN,只用注意力模型来进行序列的建模
新型的网络结构: Transformer,里面所包含的注意力机制称之为 self-attention。这套 Transformer 是能够计算 input 和 output 的 representation 而不借助 RNN 的的 model,所以作者说有 attention 就够了。
模型:同样包含 encoder 和 decoder 两个 stage,encoder 和 decoder 都是抛弃 RNN,而是用堆叠起来的 self-attention,和 fully-connected layer 来完成,模型的架构如下:
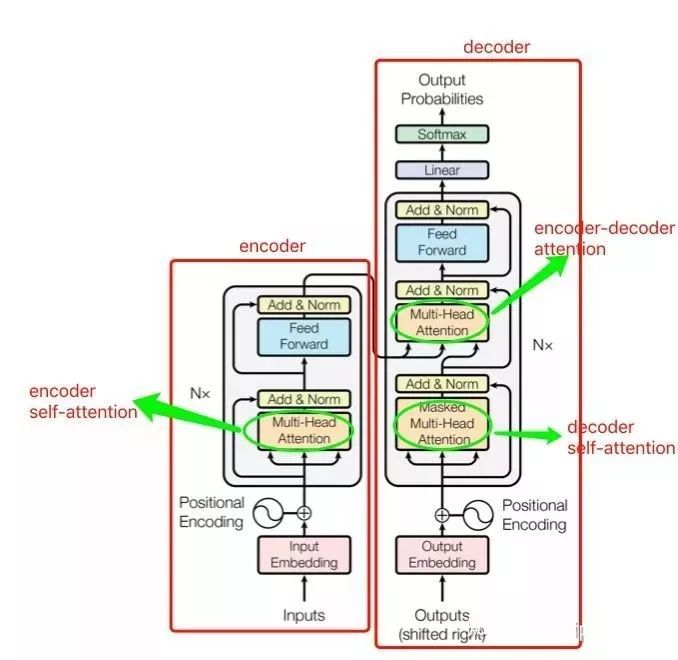
模型共包含三个 attention 成分,分别是 encoder 的 self-attention,decoder 的 self-attention,以及连接 encoder 和 decoder 的 attention。这三个 attention block 都是 multi-head attention 的形式,输入都是 query Q 、key K 、value V 三个元素,只是 Q 、 K 、 V 的取值不同罢了。接下来重点讨论最核心的模块 multi-head attention(多头注意力)。
multi-head attention 由多个 scaled dot-product attention 这样的基础单元经过 stack 而成。
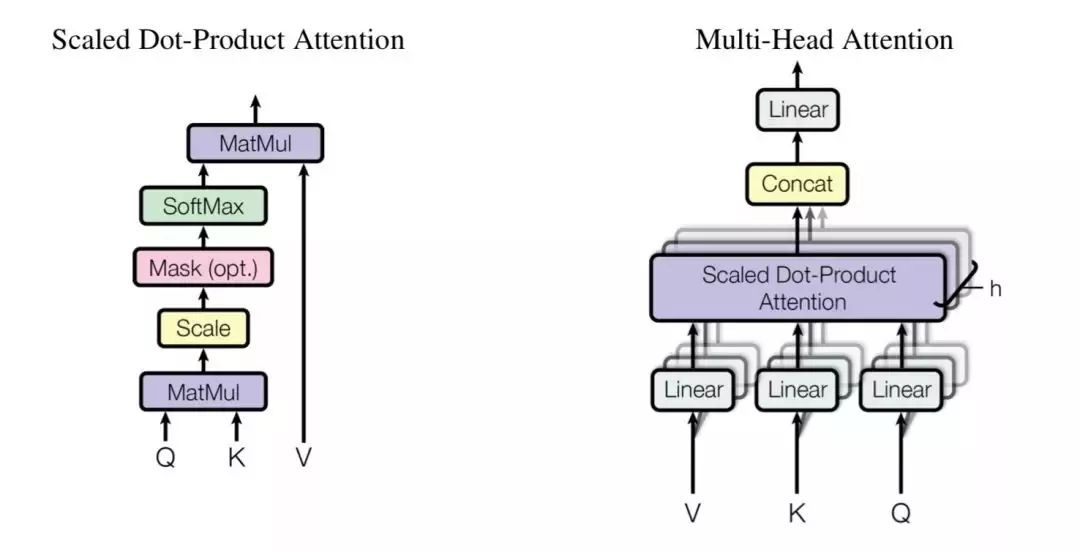
按字面意思理解,scaled dot-product attention 即缩放了的点乘注意力,我们来对它进行研究。
那么 Q、K、V 到底是什么?encoder 里的 attention 叫 self-attention,顾名思义,就是自己和自己做 attention。在传统的 seq2seq 中的 encoder 阶段,我们得到 n 个时刻的 hidden states 之后,可以用每一时刻的 hidden state hi,去分别和任意的 hidden state hj,j=1,2,…,n 计算 attention,这就有点 self-attention 的意思。回到当前的模型,由于抛弃了 RNN,encoder 过程就没了 hidden states,那拿什么做 self-attention 来自嗨呢?
可以想到,假如作为 input 的 sequence 共有 n 个 word,那么我可以先对每一个 word 做 embedding 吧?就得到 n 个 embedding,然后我就可以用 embedding 代替 hidden state 来做 self-attention 了。所以 Q 这个矩阵里面装的就是全部的 word embedding,K、V 也是一样。
所以为什么管 Q 叫query?就是你每次拿一个 word embedding,去“查询”其和任意的 word embedding 的 match 程度(也就是 attention 的大小),你一共要做 n 轮这样的操作。
我们记 word embedding 的 dimension 为 dmodel ,所以 Q 的 shape 就是 n*dmodel, K、V 也是一样,第 i 个 word 的 embedding 为 vi,所以该 word 的 attention 应为:

scaled dot-product attention 基本就是这样了。基于 RNN 的传统 encoder 在每个时刻会有输入和输出,而现在 encoder 由于抛弃了 RNN 序列模型,所以可以一下子把序列的全部内容输进去,来一次 self-attention 的自嗨。
理解了 scaled dot-product attention 之后,multi-head attention 就好理解了,因为就是 scaled dot-product attention 的 stacking。
先把 Q、K、V 做 linear transformation,然后对新生成的 Q’、K’、V’ 算 attention,重复这样的操作 h 次,然后把 h 次的结果做 concat,最后再做一次 linear transformation,就是 multi-head attention 这个小 block 的输出了。

以上介绍了 encoder 的 self-attention。decoder 中的 encoder-decoder attention 道理类似,可以理解为用 decoder 中的每个 vi 对 encoder 中的 vj 做一种交叉 attention。
decoder 中的 self-attention 也一样的道理,只是要注意一点,decoder 中你在用 vi 对 vj 做 attention 时,有一些 pair 是不合法的。原因在于,虽然 encoder 阶段你可以把序列的全部 word 一次全输入进去,但是 decoder 阶段却并不总是可以,想象一下你在做 inference,decoder 的产出还是按从左至右的顺序,所以你的 vi 是没机会和 vj ( j>i ) 做 attention 的。
那怎么将这一点体现在 attention 的计算中呢?文中说只需要令 score(vi,vj)=-∞ 即可。为何?因为这样的话:
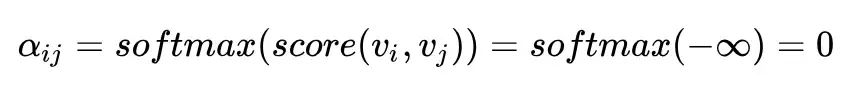
所以在计算 vi 的 self-attention 的时候,就能够把 vj 屏蔽掉。所以这个问题也就解决了。
multi-head attention的更多相关文章
- multi lstm attention 坑一个
multi lstm attention时序之间,inputs维度是1024,加上attention之后维度是2018,输出1024,时序之间下次再转成2048的inputs 但是如果使用multi ...
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 第五课第四周笔记4:Transformer Network变压器网络
Transformer Network变压器网络 你已经了解了 self attention,你已经了解了 multi headed attention.在这个视频中,让我们把它们放在一起来构建一个变 ...
- 第五课第四周笔记1:Transformer Network Intuition 变压器网络直觉
目录 Transformer Network Intuition 变压器网络直觉 Transformer Network Intuition 变压器网络直觉 深度学习中最令人兴奋的发展之一是 Tran ...
- [源码解析] 分布式训练Megatron (1) --- 论文 & 基础
[源码解析] 分布式训练Megatron (1) --- 论文 & 基础 目录 [源码解析] 分布式训练Megatron (1) --- 论文 & 基础 0x00 摘要 0x01 In ...
- einsum函数介绍-张量常用操作
einsum函数说明 pytorch文档说明:\(torch.einsum(equation, **operands)\) 使用基于爱因斯坦求和约定的符号,将输入operands的元素沿指定的维数求和 ...
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
https://zhuanlan.zhihu.com/p/25928551 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文题目便是文本分类问题,趁此机会总结下文本分类 ...
- [转] 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
转自知乎上看到的一篇很棒的文章:用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文 ...
- 《An Attentive Survey of Attention Models》阅读笔记
本文是对文献 <An Attentive Survey of Attention Models> 的总结,详细内容请参照原文. 引言 注意力模型现在已经成为神经网络中的一个重要概念,并已经 ...
- Attention:本博客暂停更新
Attention:本博客暂停更新 2016年11月17日08:33:09 博主遗产 http://www.cnblogs.com/radiumlrb/p/6033107.html Dans cett ...
随机推荐
- Spring之缓存注解@Cacheable
https://www.cnblogs.com/fashflying/p/6908028.html https://blog.csdn.net/syani/article/details/522399 ...
- MSOCache office问题
\MSOCache 链接:https://pan.baidu.com/s/1dVvjYnD0D6DG6oFK_Mww2w密码:qrvp undefied
- easyui中如何为validatebox添加事件(onblur、onclick等)
在我们一般html的input标签,textbox事件可以直接使用onblur().onclick()事件,但是在easyui的validatebox没有onblur事件, 如果我们需要为valida ...
- shell 多重条件判断
多重条件判断 '判断1 -a 判断2' 逻辑与,判断1和判断2都成立,最终的结果才为真 '判断1 -o 判断2' 逻辑或,判断1和判断2有一个成立,最终的结果就为真 '!判断' 逻辑非,使原始的判断式 ...
- Win10系列:VC++ Direct3D模板介绍2
(3)CreateDeviceResources函数 CreateDeviceResources函数默认添加在CubeRenderer.cpp源文件中,此函数用于创建着色器和立体图形顶点.接下来分别介 ...
- 深入研究sqlalchemy连接池
简介: 相对于最新的MySQL5.6,MariaDB在性能.功能.管理.NoSQL扩展方面包含了更丰富的特性.比如微秒的支持.线程池.子查询优化.组提交.进度报告等. 本文就主要探索MariaDB当中 ...
- MYSQL的存储函数
创建存储函数与创建存储过程大体相同,格式如下: create function sp_name([func_parameter[,...]]) returns type [characteristic ...
- בוא--来吧--IPA--希伯来语
灰常好听的希伯来语歌曲, Rita唱得真好.
- 下载python中package的简便方法
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xxx
- 用Java给数组排序
public class BubbleDemo {public static void main(String[] args) { int arr[]={1,3,5,7,2,4,6,8,9}; bub ...