[Node.js] 00 - Where do we put Node.js
Ref: 前后端分离的思考与实践(五篇软文)
其实就是在吹淘宝自己的Midway-ModelProxy架构。
第一篇
起因
为了提升开发效率,前后端分离的需求越来越被重视,
同一份数据接口,我们可以定制开发多个版本。
(1) 后端 - 业务/数据接口,
(2) 前端 - 展现/交互逻辑,
措施
探索一套基于 Node.js 的前后端分离方案,过程中有一些不断变化的认识以及思考,记录在这里。
一、什么是前后端分离?
一个基准例子
每个人对前后端分离的理解不一样,
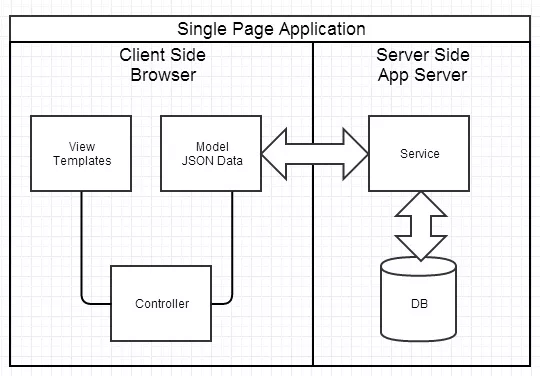
前后端分离的例子就是SPA(Single Page Application),所有用到的展现数据都是后端通过异步接口(AJAX/JSONP)的方式提供的,前端只管展现。
后端会帮我们处理一些展现逻辑,这就意味着后端还是涉足了 View 层的工作,不是真正的前后端分离。
【后端不能关心界面的展示部分,所以spa分离的不完全】
从职责上划分才能满足目前我们的使用场景:
(1) 前端:View 和 Controller 层。
(2) 后端:Model 层 (业务处理/数据等)。
二、为什么要前后端分离?
玉伯 -《Web 研发模式演变》
Web 1.0 时代
页面由 JSP、PHP 等工程师在服务端生成,浏览器负责展现。
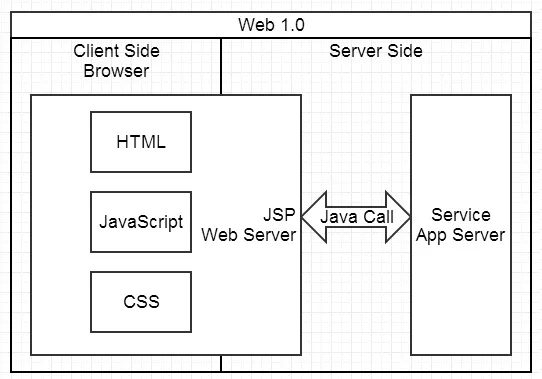
Service 越来越多,调用关系变复杂。JSP 等代码的可维护性越来越差。
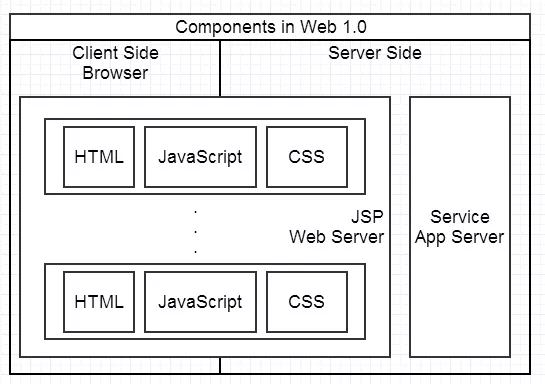
提出问题
但可维护性更多是工程含义,有时候需要通过限制带来自由,需要某种约定,使得即便是新手也不会写出太糟糕的代码。
如何让前后端分工更合理高效,如何提高代码的可维护性,在 Web 开发中很重要。
后端为主的 MVC 时代
Web Server 层的架构升级,比如 Structs、Spring MVC 等,这是后端的 MVC 时代。

Web 2.0 时代
2004 年 Gmail 像风一样的女子来到人间,很快 2005 年 Ajax 正式提出,加上 CDN 开始大量用于静态资源存储,
于是出现了 JavaScript 王者归来的 SPA(Single Page Application) 的时代。Ajax 带来的 SPA 时代!
【开始在浏览器中重视起Javascript】
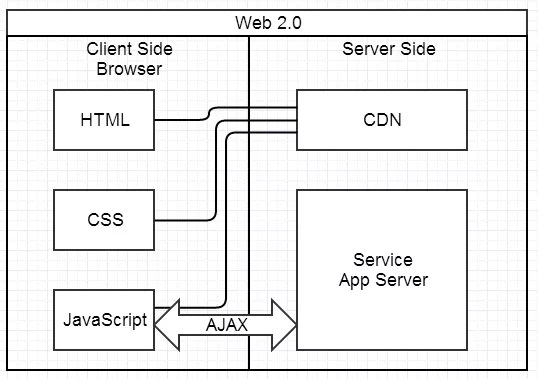
AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。
AJAX 不是新的编程语言,而是一种使用现有标准的新方法。
AJAX 最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网页内容。
AJAX 不需要任何浏览器插件,但需要用户允许JavaScript在浏览器上执行。
浏览器端的分层架构
这种模式下,前后端的分工非常清晰,前后端的关键协作点是 Ajax 接口。
看起来美妙,但实际上与 JSP 时代区别不大。
复杂度从 服务端的 JSP 里移到了浏览器的 JavaScript,浏览器端变得很复杂。
类似 Spring MVC,这个时代开始出现浏览器端的分层架构:
前端为主的 MV* 时代
SPA 让前端看到了一丝绿色,但依旧是在荒漠中行走。
为了降低前端开发复杂度,除了 Backbone,还有大量框架涌现,比如 EmberJS、KnockoutJS、AngularJS 等等。
这些框架总的原则是先按类型分层,比如 Templates、Controllers、Models,然后再在层内做切分,如下图:
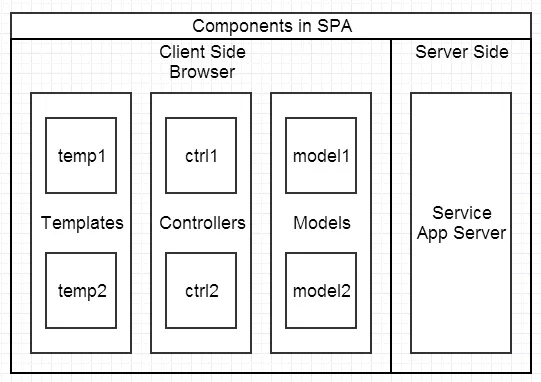
但依旧有不足之处:
1、代码不能复用。
2、全异步,对 SEO 不利。往往还需要服务端做同步渲染的降级方案。
3、性能并非最佳,特别是移动互联网环境下。
4、SPA 不能满足所有需求,依旧存在大量多页面应用。URL Design 需要后端配合,前端无法完全掌控。
Node 带来的全栈时代
随着 Node.js 的兴起,JavaScript 开始有能力运行在服务端。这意味着可以有一种新的研发模式:

在这种研发模式下,前后端的职责很清晰。对前端来说,两个 UI 层各司其职:
1、Front-end UI layer 处理浏览器层的展现逻辑。通过 CSS 渲染样式,通过 JavaScript 添加交互功能,HTML 的生成也可以放在这层,具体看应用场景。
2、Back-end UI layer 处理路由、模板、数据获取、cookie 等。
通过路由,前端终于可以自主把控 URL Design,这样无论是单页面应用还是多页面应用,前端都可以自由调控。后端也终于可以摆脱对展现的强关注,转而可以专心于业务逻辑层的开发。
前一种模式的不足,通过这种模式几乎都能完美解决掉:
通过 Node,Web Server 层也是 JavaScript 代码,这意味着部分代码可前后复用,需要 SEO 的场景可以在服务端同步渲染,由于异步请求太多导致的性能问题也可以通过服务端来缓解。
SEO参考:前端后端分离,怎么解决SEO优化的问题呢
基于 Node 的全栈模式,依旧面临很多挑战:
1、需要前端对服务端编程有更进一步的认识。比如 network/tcp、PE 等知识的掌握。
2、Node 层与 Java 层的高效通信。Node 模式下,都在服务器端,RESTful HTTP 通信未必高效,通过 SOAP 等方式通信更高效。一切需要在验证中前行。
3、对部署、运维层面的熟练了解,需要更多知识点和实操经验。
4、大量历史遗留问题如何过渡。这可能是最大最大的阻力。
小结
回顾历史总是让人感慨,展望未来则让人兴奋。上面讲到的研发模式,除了最后一种还在探索期,其他各种在各大公司都已有大量实践。几点小结:
1、模式没有好坏高下之分,只有合不合适。
2、Ajax 给前端开发带来了一次质的飞跃,Node 很可能是第二次。
3、SoC(关注度分离) 是一条伟大的原则。上面种种模式,都是让前后端的职责更清晰,分工更合理高效。
4、还有个原则,让合适的人做合适的事。比如 Web Server 层的 UI Layer 开发,前端是更合适的人选。
把node做为UI渲染的“后端服务器"的使用方式,我觉得还是很有道理,很值得尝试的。
以后端开发而言,我会更加看好go,但目前go在UI渲染方面还是比较弱,把go挪去“真·后端”,UI渲染换成node,我觉得会是挺不错的选择。
三、怎么做前后端分离?
基于NodeJS“全栈”式开发
提问者
- SPA 模式中,后端已供了所需的数据接口,View 前端已经可以控制,为什么要多加 Node.js 这一层?
- 多加一层,性能怎么样?
- 多加一层,前端的工作量是不是增加了?
- 多加一层就多一层风险,怎么破?
- Node.js 什么都能做,为什么还要 Java?
回答者
为什么要增加一层 Node.js?
现阶段我们主要以后端 MVC 的模式进行开发,这种模式严重阻碍了前端开发效率,也让后端不能专注于业务开发。
解决方案是让前端能控制 Controller 层,但是如果在现有技术体系下很难做到,因为不可能让所有前端都学 Java,安装后端的开发环境,写 VM。
Node.js 就能很好的解决这个问题,我们无需学习一门新的语言,就能做到以前开发帮我们做的事情,一切都显得那么自然。
性能问题
分层就涉及每层之间的通讯,肯定会有一定的性能损耗。但是合理的分层能让职责清晰、也方便协作,会大大提高开发效率。分层带来的损失,一定能在其他方面的收益弥补回来。
另外,一旦决定分层,我们可以通过优化通讯方式、通讯协议,尽可能把损耗降到最低。
举个例子:
淘宝宝贝详情页静态化之后,还是有不少需要实时获取的信息,比如物流、促销等等,因为这些信息在不同业务系统中,所以需要前端发送 5,6 个异步请求来回填这些内容。
有了 Node.js 之后,前端可以在 Node.js 中去代理这 5 个异步请求,还能很容易的做 Bigpipe,这块的优化能让整个渲染效率提升很多。
可能在 PC 上你觉得发 5、6 个异步请求也没什么,但是在无线端,在客户手机上建立一个 HTTP 请求开销很大,有了这个优化,性能一下提升好几倍。
淘宝详情基于 Node.js 的优化我们正在进行中,上线之后我会分享一下优化的过程。
前端的工作量是否增加了?
相对于只切页面/做 demo,肯定是增加了一点,但是当前模式下有联调、沟通环节,这个过程非常花时间,也容易出 bug,还很难维护。所以,虽然工作量会增加一点,但是总体开发效率会提升很多。
另外,测试成本可以节省很多。以前开发的接口都是针对表现层的,很难写测试用例。如果做了前后端分离,甚至测试都可以分开,一拨人专门测试接口,一拨人专注测试 UI(这部分工作甚至可以用工具代替)。
增加 Node.js 层带来的风险怎么控制?
随着 Node.js 大规模使用,系统/运维/安全部门的同学也一定会加入到基础建设中,他们会帮助我们去完善各个环节可能出现的问题,保障系的稳定性。
Node.js 什么都能做,为什么还要 Java?
我们的初衷是做前后端分离,如果考虑这个问题就有点违背我们的初衷了。即使用 Node.js 替代 Java,我们也没办法保证不出现今天遇到的种种问题,比如职责不清。
我们的目的是分层开发,专业的人,专注做专业的事。基于 Java 的基础架构已经非常强大而且稳定,而且更适合做现在架构的事情。
四、淘宝基于 Node.js 的前后端分离
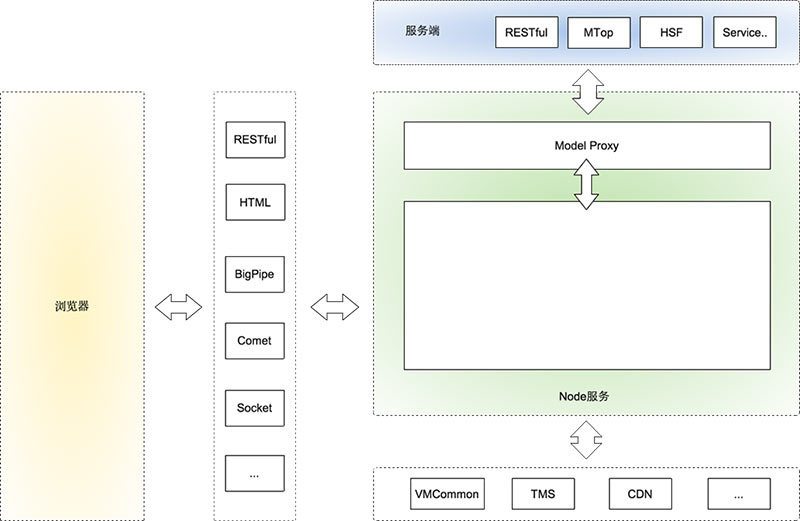
- 最上端是服务端,就是我们常说的后端。后端对于我们来说,就是一个接口的集合,服务端提供各种各样的接口供我们使用。因为有 Node.js 层,也不用局限是什么形式的服务。对于后端开发来说,他们只用关心业务代码的接口实现。
- 服务端下面是 Node.js 应用。
- Node.js 应用中有一层 Model Proxy 与服务端进行通讯。这一层主要目前是抹平我们对不同接口的调用方式,封装一些 View 层需要的 Model。
- Node.js 层还能轻松实现原来 vmcommon, tms(引用淘宝内容管理系统)等需求。
- Node.js 层要使用什么框架由开发者自己决定。不过推荐使用 Express + XTemplate 的组合,XTemplate 能做到前后端公用。
- 怎么用 Node.js 大家自己决定,但是令人兴奋的是,我们终于可以使用 Node.js 轻松实现我们想要的输出方式: JSON/JSONP/RESTful/HTML/BigPipe/Comet/Socket/同步、异步,想怎么整就怎么整,完全根据你的场景决定。
- 浏览器层在我们这个架构中没有变化,也不希望因为引入 Node.js 改变你以前在浏览器中开发的认知。
- 引入 Node.js,只是把本该就前端控制的部分交由前端掌控。
第二篇
可以观察到在这几年,大家都倾向将 渲染这件事,从服务器端端移向了浏览器端。
而服务器端则专注于 服务化 ,提供数据接口。
View 这个层面的工作,经过了许多次的变革:
(1) Form Submit 全页刷新 => AJAX 局部刷新
(2) 服务端续染 + MVC => 客户端渲染 + MVC
(3) 传统换页跳转 => 单页面应用
浏览器端渲染造成的坏处
(1) 模版分离在不同的库。有的模版放在服务端(JAVA),而有的放在浏览器端(JS)。前后端模版语言不相通。
(2) 需要等待所有模版与组件在浏览器端载入完成后才能开始渲染,无法即开即看。
(3) 首次进入会有白屏等待渲染的时间,不利于用户体验
(4) 开发单页面应用时,前端 Route 与服务器端 Route 不匹配,处理起来很麻烦。
(5) 重要内容都在前端组装,不利于 SEO
一个误区
很多人认定了 后端 = 服务端,前端 = 浏览器端 ,就像下面这张图。
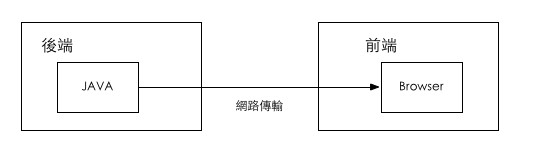
一个方案
在中途岛项目中,我们把前后端分界的那条线,从浏览器端移回到了服务器端。

后端,专注于:(1) 服务层。 (2) 数据格式、数据稳定。 (3) 业务逻辑。
前端,专注于:(1) UI 层。 (2) 控制逻辑、渲染逻辑。 (3) 交互、用户体验。
用着一样的模版语言 XTemplate,一样的渲染引擎 JavaScript。
也因为有了 Node.js 这一层,可以更细致的控制路由。
模版共享的实践
通常我们在浏览器端渲染一份模版时,流程不外乎是
在浏览器端載入模版引擎(XTmpleate、Juicer、handlerbar 等)
(2) 在浏览器端载入模版档案,方法可能有
* 使用 <script type="js/tpl"> ... </script> 印在页面上
* 使用模块载入工具,载入模版档案 (KISSY, requireJS, etc.)
* 其他
(3) 取得数据,使用模版引擎产生 HTML
(4) 将 HTML 插入到指定位置。
從以上的流程可以观察到,要想要做到模版的跨端共享,重点其实在一致的模块选型这件事。
市面上流行很多种模块标准,例如 KMD、AMD、CommonJS,只要能将NodeJS的模版档案透过一致模块规范输出到 Node.js 端,就可以做基本的模版共享了。
案例一 复杂交互应用(如购物车、下单页面)
- 状况:全部的 HTML 都是在前端渲染完成,服务端仅提供接口。
- 问题:进入页面时,会有短暂白屏。
- 解答:
- 首次进入页面,在 Node.js 端进行全页渲染,并在背景下载相关的模版。
- 后续交互操作,在浏览器端完成局部刷新
- 用的是同一份模版,产生一样的结果
案例二 单页面应用
- 状况:使用 Client-side MVC 框架,在浏览器换页。
- 问题:渲染与换页都在浏览器端完成,直接输入网址进入或 F5 刷新时,无法直接呈现同样的内容。
- 解答:
- 在浏览器端与 Node.js 端共享同样的 Route 设定
- 浏览器端换页时,在浏览器端进行 Route 变更与页面内容渲染
- 直接输入同样的网址时,在 Node.js 端进行“页面框架 + 页面内容”渲染
- 不管是浏览器端换页,或直接输入同样的网址,看到的内容都是一样的。
- 除了增加体验、减少逻辑複杂度外。更解决了 SEO 的问题
案例三 纯浏览型页面
- 状况:页面仅提供资讯,较少或没有交互
- 问题:HTML 在服务端产生,CSS 与 JS 放在另外一个位置,彼此间有依赖。
- 解答:
- 透过 Node.js,统一管理 HTML + CSS + JS
- 日后若需要扩展成复杂应用或是单页面应用,也可以轻易转移。
案例四 跨终端页面
- 状况:同样的应用要在不同端点呈现不同的介面与交互
- 问题:HTML 管理不易,常常会在服务端产生不一样的HTML,浏览器端又要做不一样的处理
- 解答:
- 跨终端的页面是渲染的问题,统一由前端来处理。
- 透过 Node.js 层与后端服务化,可以针对这类型复杂应用,设计最佳的解决方案。
第三篇
《Midway-ModelProxy — 轻量级的接口配置建模框架》
Node.js 在整个环境中最重要的工作之一就是代理这些业务接口,以方便前端(Node.js 端和浏览器端)整合数据做页面渲染。
如何做好代理工作,使得前后端开发分离之后,仍然可以在流程上无缝衔接。
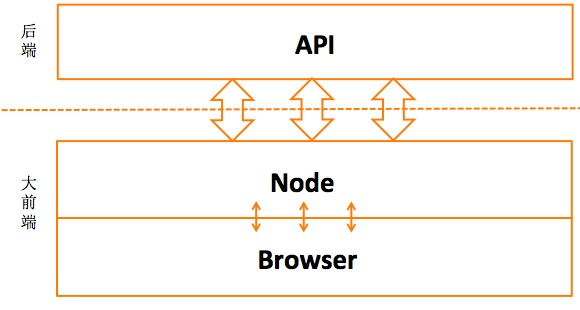
于是我们希望有这样一个框架,通过该框架提供的机制去描述工程项目中依赖的所有外部接口,对他们进行统一管理,同时提供灵活的接口建模及调用方式,并且提供便捷的线上环境和生产环境切换方法,使前后端开发无缝结合。
ModelProxy 就是满足这样要求的轻量级框架,它是 Midway Framework 核心构件之一,也可以单独使用。
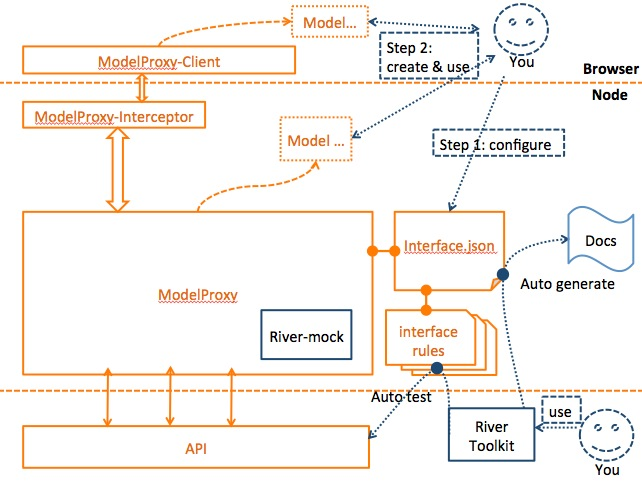
(1) 开发者首先需要将工程项目中所有依赖的后端接口描述,按照指定的 JSON 格式,写入 interface.json 配置文件。
(2) 必要时,需要对每个接口编写一个规则文件,也即图中 interface rules 部分。
该规则文件用于在开发阶段mock数据或者在联调阶段使用 River 工具集去验证接口。
规则文件的内容取决于采用哪一种 mock 引擎(比如 mockjs, river-mock 等等)。
Ref: 你是如何构建 Web 前端 Mock Server 的?【这一部分算是单独的一块儿知识点】
(3) 配置完成之后,即可在代码中按照自己的需求创建自己的业务 Model。
举例子 - 摆事实,讲道理
例一
第一步 在工程目录中创建接口配置文件 interface.json, 并在其中添加主搜接口 JSON 定义。
{
"title": "pad淘宝项目数据接口集合定义",
"version": "1.0.0",
"engine": "mockjs",
"rulebase": "./interfaceRules/",
"status": "online",
"interfaces": [{
"name": "主搜索接口",
"id": "Search.getItems",
"urls": {
"online": "http://s.m.taobao.com/client/search.do"
}
}]
}
第二步 在代码中创建并使用 Model。
// 引入模块
var ModelProxy = require('modelproxy'); // 全局初始化引入接口配置文件 (注意:初始化工作有且只有一次)
ModelProxy.init('./interface.json'); // 创建model 更多创建模式请参后文
var searchModel = new ModelProxy({
searchItems: 'Search.getItems' // 自定义方法名: 配置文件中的定义的接口ID
}); // 使用model, 注意: 调用方法所需要的参数即为实际接口所需要的参数。
searchModel.searchItems({q: 'iphone6'})
// !注意 必须调用 done 方法指定回调函数,来取得上面异步调用searchItems获得的数据!
.done(function(data) {
console.log(data);
})
.error(function(err) {
console.log(err);
});
ModelProxy 的功能丰富性在于它支持各种形式的 profile 以创建需要业务 Model:
- 使用接口 ID 创建 > 生成的对象会取ID最后’.’号后面的单词作为方法名
ModelProxy.create('Search.getItem');
- 使用键值 JSON 对象 > 自定义方法名: 接口 ID
ModelProxy.create({
getName: 'Session.getUserName',
getMyCarts: 'Cart.getCarts'
});
- 使用数组形式 > 取最后
.号后面的单词作为方法名
// 下例中生成的方法调用名依次为: Cart_getItem,getItem,suggest,getName
ModelProxy.create(['Cart.getItem', 'Search.getItem', 'Search.suggest', 'Session.User.getName']);
- 前缀形式 > 所有满足前缀的接口ID会被引入对象,并取其后半部分作为方法名
ModelProxy.create('Search.*');
同时,使用这些 Model,你可以很轻易地实现合并请求或者依赖请求,并做相关模板渲染。
例二
合并请求
var model = new ModelProxy('Search.*');
// 合并请求 (下面调用的 Model 方法除 done 之外,皆为配置接口 Id 时指定)
model.suggest({q: '女'})
.list({keyword: 'iphone6'})
.getNav({key: '流行服装'})
.done(function(data1, data2, data3) {
// 参数顺序与方法调用顺序一致
console.log(data1, data2, data3);
});
例三
依赖请求
var model = new ModelProxy({
getUser: 'Session.getUser',
getMyOrderList: 'Order.getOrder'
});
// 先获得用户id,然后再根据id号获得订单列表
model.getUser({sid: 'fdkaldjfgsakls0322yf8'})
.done(function(data) {
var uid = data.uid;
// 二次数据请求依赖第一次取得的id号
this.getMyOrderList({id: uid})
.done(function(data) {
console.log(data);
});
});
例四
浏览器端使用 ModelProxy
此外 ModelProxy 不仅在 Node.js 端可以使用,也可以在浏览器端使用。只需要在页面中引入官方包提供的 modelproxy-client.js 即可。
<!-- 引入modelproxy模块,该模块本身是由KISSY封装的标准模块-->
<script src="modelproxy-client.js"></script>
<script type="text/javascript">
KISSY.use('modelproxy', function(S, ModelProxy) {
// !配置基础路径,该路径与第二步中配置的拦截路径一致!
// 且全局配置有且只有一次!
ModelProxy.configBase('/model/'); // 创建model
var searchModel = ModelProxy.create('Search.*');
searchModel
.list({q: 'ihpone6'})
.list({q: '冲锋衣'})
.suggest({q: 'i'})
.getNav({q: '滑板'})
.done(function(data1, data2, data3, data4) {
console.log({
'list_ihpone6': data1,
'list_冲锋衣': data2,
'suggest_i': data3,
'getNav_滑板': data4
});
});
});
</script>
ModelProxy 以一种配置化的轻量级框架存在,提供友好的接口 model 组装及使用方式,同时很好的解决前后端开发模式分离中的接口使用规范问题。
在整个项目开发过程中,接口始终只需要定义描述一次,前端开发人员即可引用,同时使用 River 工具自动生成文档,形成与后端开发人员的契约,并做相关自动化测试,极大地优化了整个软件工程开发过程。
第四篇
前后端分离模式下的安全解决方案
只负责浏览器环境中开发的前端同学,需要涉猎到服务端层面,编写服务端代码。
而摆在面前的一个基础性问题就是如何保障 Web 安全?
跨站脚本攻击(XSS)的防御 - HTML escape
是什么?
跨站脚本攻击(XSS,Cross-site scripting),攻击者可以在网页上发布包含攻击性代码的数据,当浏览者看到此网页时,特定的脚本就会以浏览者用户的身份和权限来执行。
通过 XSS 可以比较容易地修改用户数据、窃取用户信息以及造成其它类型的攻击,例如:CSRF 攻击。
怎么办?
预防 XSS 攻击的基本方法是:确保任何被输出到 HTML 页面中的数据以 HTML 的方式进行转义(HTML escape)。
Ref: HTML转义字符大全
<textarea name="description">
</textarea><script>alert('hello')'</script>
</textarea>
---------------------------------------------------------------------------
将$description的值进行 HTML escape,转义后的输出代码如下:
--------------------------------------------------------------------------- <textarea name="description">
</textarea><script>alert("hello!")</script>
</textarea>
跨站请求伪造攻击(CSRF)的预防
/* 详见原文 */
关于Node.js
XSS 等注入性漏洞是所有漏洞中最容易被忽略,占互联网总攻击的70%以上;
开发者编写 Node.js 代码时,要时刻提醒自己,永远不要相信用户的输入。
第五篇
基于前后端分离的多终端适配
基于 Web 的多终端适配进行得如火如荼,行业间也发展出依赖各种技术的解决方案。
1) 基于浏览器原生 CSS3 Media Query 的响应式设计、
2) 基于云端智能重排的「云适配」方案等。
本文则主要探讨在前后端分离基础下的多终端适配方案。
方案:因为 Node.js 层彻底与数据抽离,同时无需关心大量的业务逻辑,所以十分适合在这一层进行多终端的适配工作。
UA 探测
进行多终端适配首先要解决的是 UA 探测问题。现在市面上已经有非常成熟的兼容大量设备的 User Agent 特征库和探测工具,这里有 Mozilla 整理的一个Compatibility/UADetectionLibraries。
【值得一提的是,选用 UA 探测工具时必须要考虑特征库的可维护性,因为市面上新增的设备类型越来越多,每个设备都会有独立的 User Agent,所以该特征库必须提供良好的更新和维护策略,以适应不断变化的设备】
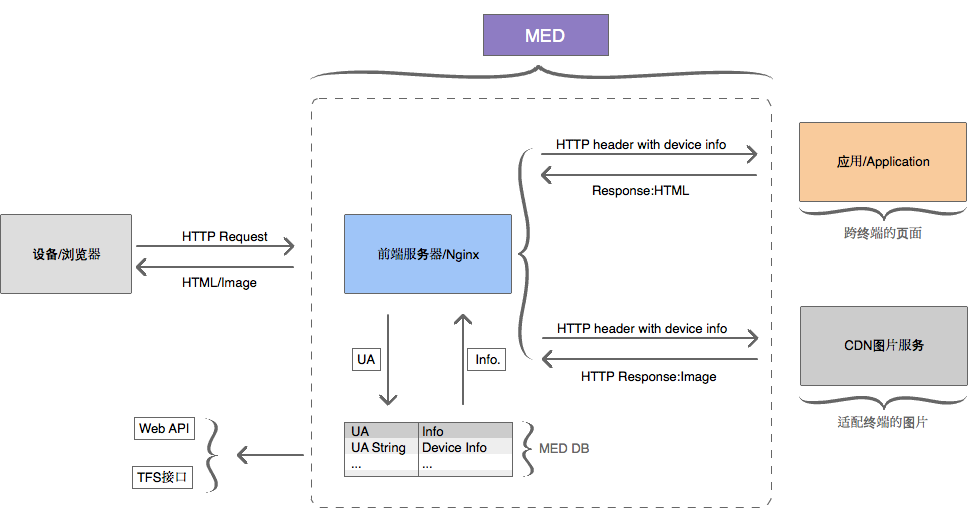
其中,既有运行在浏览器端的,也有运行在服务端代码层的,甚至有些工具提供了 nginx/Apache 的模块,负责解析每个请求的 UA 信息。
我们把这个行为再往前挪,挂在 nginx/Apache 上,它们负责:(1) 解析每个请求的 UA 信息;(2) 再通过如 HTTP Header 的方式传递给业务代码
这样做有几点好处:
(1) 我们的代码里面无需再去关注 UA 如何解析,直接从上层取出解析后的信息即可。
(2) 如果在同一台服务器上有多个应用,则能够共同使用同一个 nginx 解析后的 UA 信息,节省了不同应用间的解析损耗。a
【以下内容,日后再细看】
建立在 MVC 模式中的几种适配方案
取得 UA 信息后,我们就要考虑如何根据指定的 UA 进行终端适配了。
即使在 Node.js 层,虽然没有了大部分的业务逻辑,但我们依然把内部区分为 Model / Controller / View 三个模型。
利用该图,去解析一些已有的多终端适配方案。
建立在 Controller 上的适配方案
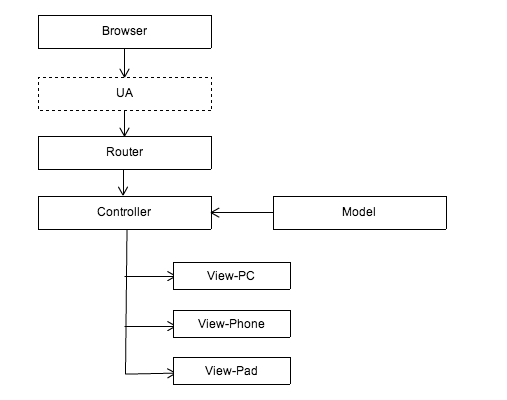
建立在 Router 上的适配方案
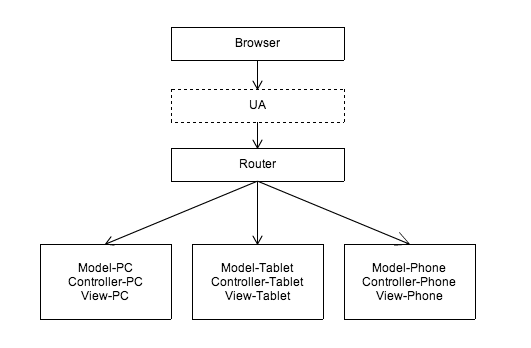
优化后:
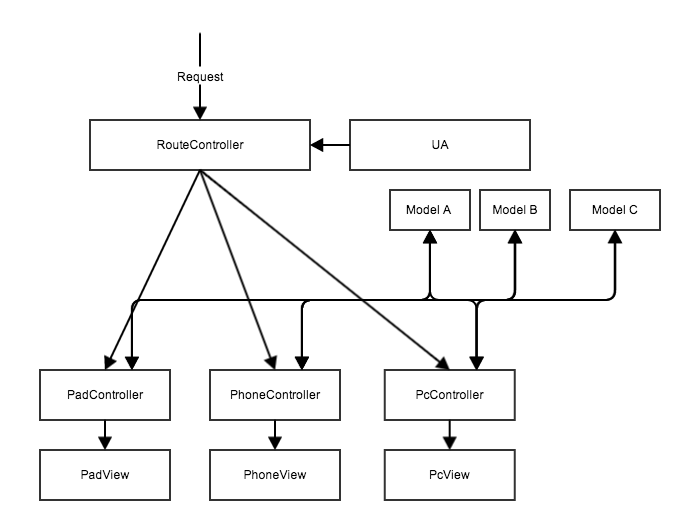
建立在 View 层的适配方案

[Node.js] 00 - Where do we put Node.js的更多相关文章
- Node.app – 用于 iOS App 开发的 Node.js 解释器
Node.app 是用于 iOS 开发的 Node.js 解释器,它允许最大的代码重用和快速创新,占用资源很少,为您的移动应用程序提供 Node.js 兼容的 JavaScript API.你的客户甚 ...
- JS一般般的网页重构可以使用Node.js做些什么(转)
一.非计算机背景前端如何快速了解Node.js? 做前端的应该都听过Node.js,偏开发背景的童鞋应该都玩过. 对于一些没有计算机背景的,工作内容以静态页面呈现为主的前端,可能并未把玩过Node.j ...
- nw.js桌面程序自动更新(node.js表白记)
Hello Google Node.js 一个基于Google V8 的JavaScript引擎. 一个伟大的端至端语言,或许我对你的热爱源自于web这门极富情感的技术吧! 注: 光阴似水,人生若梦, ...
- node源码详解(三)—— js代码在node中的位置,process、require、module、exports的由来
本作品采用知识共享署名 4.0 国际许可协议进行许可.转载保留声明头部与原文链接https://luzeshu.com/blog/nodesource3 本博客同步在https://cnodejs.o ...
- node.js 之 Hello,World in Node !
创建一个js文件,把下面的内容粘贴进去,命名为helloworld.js. //加载 http 模块 var http = require("http"); //创建 http 服 ...
- react,react native,webpack,ES6,node.js----------今天上午学了一下node.js
http://www.yiibai.com/nodejs/node_install.html---node.js具体入门资料在此 Node JS事件循环 Node JS是单线程应用程序,但它通过事件和 ...
- Node.js学习(第一章:Node.js安装和模块化理解)
Node.js安装和简单使用 安装方法 简单的安装方式是直接官网下载,然后本地安装即可.官网地址:nodejs.org Windows系统下,选择和系统版本匹配的.msi后缀的安装文件.Mac OS ...
- Node.js实战项目学习系列(5) node基础模块 path
前言 前面已经学习了很多跟Node相关的知识,譬如开发环境.CommonJs,那么从现在开始要正式学习node的基本模块了,开始node编程之旅了. path path 模块提供用于处理文件路径和目录 ...
- Node.js 学习笔记(一)--------- Node.js的认识和Linux部署
Node.js 一.Node.js 简介 简单的说 Node.js 就是运行在服务端的可以解析并运行 JavaScript 脚本的软件. Node.js 是一个基于Chrome JavaScript ...
随机推荐
- SLAM(二)----学习资料下载
有位师兄收集了很多slam的学习资料, 做的很赞, 放到了github上, 地址:https://github.com/liulinbo/slam.git ruben update 0823 2016 ...
- .net 企业管理系统快速搭建框架
简言 本人在博客园注册也2年多了,一直没有写自己的博客,因为才疏学浅一直跟着园子里的大哥们学习这.net技术.一年之前跳槽到现在的公司工作,由于公司没有自己一套的开发框架,每次都要重新 ...
- .net core 3.0视图动态编译
之前在使用Visual Studio 2019的时候,就发现asp.net 3.0中没有cshtml动态编译的功能了:也就是说,如果改了cshtml,刷新页面不会立即生效,而是要重新编译一次才行. 这 ...
- CAP:Alantany 谈 CAP
引用Alantany的话:“CAP理论提出就是针对分布式数据库环境的,所以,P这个属性是必须具备的.P就是在分布式环境中,由于网络的问题可能导致某个节点和其它节点失去联系,这时候就形成了P(parti ...
- The system is running in low-graphics mode UB16
1.Ctrl+ALT+F1 进入控制台 2.输入用户名和密码进入系统 3.输入以下命令: cd /etc/X11 sudo cp xorg.conf.failsafe xorg.conf sudo r ...
- UVA11137 Ingenuous Cubrency 完全背包 递推式子
做数论都做傻了,这道题目 有推荐,当时的分类放在了递推里面,然后我就不停的去推啊推啊,后来推出来了,可是小一点的数 输出答案都没问题,大一点的数 输出答案就是错的,实在是不知道为什么,后来又不停的看, ...
- CentOS7 下 keepalived 的安装和配置
安装前准备:yum -y install gcc gcc-c++ autoconf automake make yum -y install zlib zlib-devel openssl opens ...
- Android添加全屏启动画面
有的Android软件需要在启动的时候显示一个启动画面,可以是一张图或者一些设置什么呢,还有一个好处就是,可以趁机在后台加载数据.创建启动画面一般有两种方式:1.建立一个activity,展示启动画面 ...
- grid - gap
grid-gap默认还有两个参数 如果grid写默认方式,则行.列都会使用相同的单位 如果grid写两个参数,则行和列各自生效 如果grid写行方式,则仅有行生效 如果grid写列方式,则仅有列生 ...
- google guice @inject comments
refer this document: http://blog.chinaunix.net/uid-20749563-id-718418.html @Inject注入方式,用@Inject来标识那个 ...