CompareTo 基于的排序算法
CompareTo 基于的排序算法(高级排序)
这个是今天学习MapReduce时发现的,自定义类后实现了WritableComparable<>接口后实现了接口中的compareTo方法,返回>1或者<1则会自动进行排序的方法。
然后特别好奇,查了查,学习下做一个总结。
首先说明 实现CompareTo方法的是使用了Collections.sort()和Arrays.sort()底层得算法,是timsort算法,插入排序和归并排序的高级合并 .
详情:https://blog.csdn.net/yangzhongblog/article/details/8184707
而这2个方法在底层实现时,使用到了object1.compareTo(object2)这种方法进行判断谁大谁小,从而调整数组,最终给你返回有序的集合,两个方法的排序算法实现有归并排序和快速排序。
详细将一下:归并排序是属于递归中的一种,而快速排序是是属于高级排序的,与其同时的 还有希尔排序,划分,基数排序。但最常用的还是快速排序。这里详解一下技术排序,归并排序我则在记录递归是将其一并总结。所以我来详解一下这个高级排序
高级排序
希尔排序:
n-增量排序:通过加大插入排序中的元素之间的间隔。n:是指元素之间的间隔几个元素
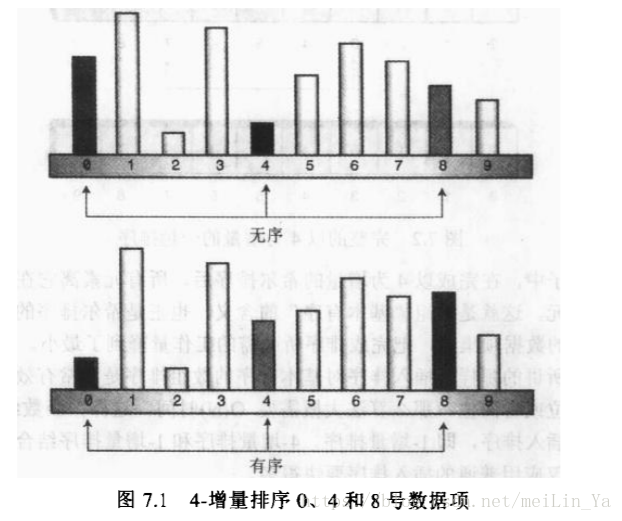
我们来看一下主要的 4- 增量排序的放的排序过程。所有元素在离它最终的有序序列中的位置相差不到两个单元,做到了数据的基本有序,希尔则是做到了数据的基本有序,通过创建这种交错的内部有序的数据项集合,把完成排序所需的工作降调到最小

那么我们来研究一下这个间隔,这个间隔到底是使用多少为合适,可以将希尔的作用发挥到及至。以及间隔的选用。
间隔是通过数组得到大小进行变化的。比如1000个数据,间隔则为364-->121-->40-->13-->4-->1 这个间隔序列是通过递归计算出来的

谈希尔适合的排序环境:
这里是我的个人见解,如有更好的见解,欢迎一起讨论!!!
希尔排序适合中量数据的基本有序排序,少量数据使用插入排序进行更为稳定。
走开走开~~代码来了
package AdvancedRanking.ShellSort;
public class ArraySh {
//数组
private long[] theArray;
//数组长度
private int nElems;
public ArraySh(int max) {
theArray = new long[max];
nElems = 0;
}
public void insert(long value) {
theArray[nElems] = value;
nElems++;
}
public void display() {
System.out.print("A=");
for (int j = 0; j < nElems; j++) {
System.out.print(theArray[j] + " ");
}
System.out.println("");
}
public void shellSort() {
int inner, outer;
long temp;
//初始时元素之间的间隔
int h = 1;
while (h <= nElems / 3) {
h = h * 3 + 1;
}
while (h > 0) {
for (outer = h; outer < nElems; outer++) {
temp = theArray[outer];
inner = outer;
while (inner > h - 1 && theArray[inner - h] >= temp) {
theArray[inner] = theArray[inner - h];
System.out.println(theArray[inner]);
inner -= h;
}
theArray[inner] = temp;
}
//结束时元素之间的间隔
h = (h - 1) / 3;
}
}
public static void main(String[] args) {
int maxSize = 10;
ArraySh arr = new ArraySh(maxSize);
for (int j = 0; j < maxSize; j++) {
long n = (int) (Math.random() * 99);
arr.insert(n);
}
arr.display();
arr.shellSort();
arr.display();
}
}
二.划分
package AdvancedRanking.PartitionSort;
public class ArrayPar {
private long[] theArray;
private int nElems;
public ArrayPar(int max) {
theArray = new long[max];
nElems = 0;
}
public void insert(long value) {
theArray[nElems] = value;
nElems++;
}
public int size() {
return nElems;
}
public void display() {
System.out.print("A=");
for (int j = 0; j < nElems; j++) {
System.out.print(theArray[j] + " ");
}
System.out.println("");
}
public int partitionIt(int left, int right, long pivot) {
int leftPtr = left - 1;
int rightPtr = right + 1;
while (true) {
//最大得
while (leftPtr < right && theArray[++leftPtr] > pivot) ;
//最小的
while (rightPtr > left && theArray[--rightPtr] > pivot) ;
if (leftPtr > rightPtr) {
break;
} else {
swap(leftPtr, rightPtr);
}
}
return leftPtr;
}
public void swap(int dex1, int dex2) {
long temp;
temp = theArray[dex1];
theArray[dex1] = theArray[dex2];
theArray[dex2] = temp;
}
public static void main(String[] args) {
int maxSize = 10;
ArrayPar arr = new ArrayPar(maxSize);
for (int j = 0; j < maxSize; j++) {
long n = (int) (Math.random() * 199);
arr.insert(n);
}
arr.display();
long piovt = 99;
System.out.print("Piovt is " + piovt);
int size = arr.size();
int partDex = arr.partitionIt(0, size - 1, piovt);
System.out.println(", Partition is at index " + partDex);
arr.display();
}
}

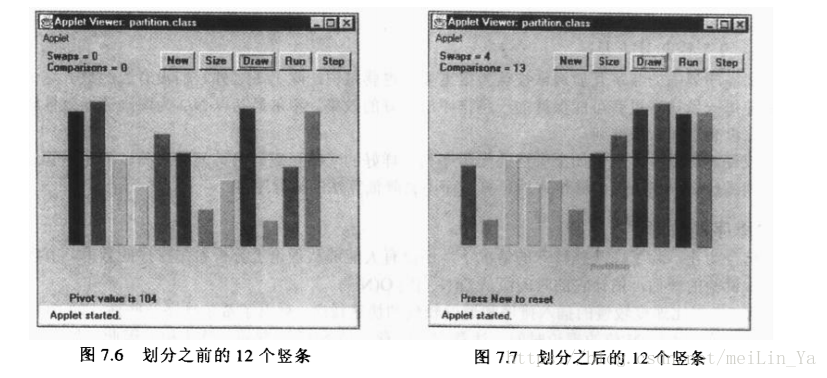
划分算法是由两个指针开始工作的,两个指针分别指向数据的两头leftPtr初始化是在第一个数据项的左边的一位,rightPtr是在最后一个数据项的右边一位。他们分别要-1 +1
//找小于于piovt
while (leftPtr < right && theArray[++leftPtr] > pivot) ;
//找小于pivot
while (rightPtr > left && theArray[--rightPtr] > pivot) ;划分算法运行时间为O(N),他其中的piovt枢纽,根据枢纽来移动指针和交换数据位置,虽然交换次数少,但是比较次数多。100个数大约交换25次,102次的比较。
快速排序:
CompareTo 基于的排序算法的更多相关文章
- Arrays.Sort()中的那些排序算法
本文基于JDK 1.8.0_211撰写,基于java.util.Arrays.sort()方法浅谈目前Java所用到的排序算法,仅个人见解和笔记,若有问题欢迎指证,着重介绍其中的TimSort排序,其 ...
- 常见排序算法基于JS的实现
一:冒泡排序 1. 原理 a. 从头开始比较相邻的两个待排序元素,如果前面元素大于后面元素,就将二个元素位置互换 b. 这样对序列的第0个元素到n-1个元素进行一次遍历后,最大的一个元素就“沉”到序列 ...
- 第32讲:List的基本操作实战与基于模式匹配的List排序算法实现
今天来学习一下list的基本操作及基于模式匹配的排序操作 让我们从代码出发 val bigData = List("hadoop","spark") val d ...
- 排序算法总结(基于Java实现)
前言 下面会讲到一些简单的排序算法(均基于java实现),并给出实现和效率分析. 使用的基类如下: 注意:抽象函数应为public的,我就不改代码了 public abstract class Sor ...
- 转载~基于比较的排序算法的最优下界为什么是O(nlogn)
基于比较的排序算法的最优下界为什么是O(nlogn) 发表于2013/12/21 16:15:50 1024人阅读 分类: Algorithm 1.决策二叉树 回答这个问题之前我们先来玩一个猜数字的 ...
- 基于python的七种经典排序算法
参考书目:<大话数据结构> 一.排序的基本概念和分类 所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作.排序算法,就是如何使得记录按照要求排列的方法. ...
- 八大排序算法---基于python
本文节选自:http://python.jobbole.com/82270/ 本文用Python实现了插入排序.希尔排序.冒泡排序.快速排序.直接选择排序.堆排序.归并排序.基数排序. 1.插入排序 ...
- 温习排序算法(基于C指针)
以前学过的数据结构课,貌似已经忘得一干二净了,偶然又翻起,书中最后一章详细介绍了7种排序算法,现在对其中4种做个总结.(为啥只总结4种,当然是因为偷懒,只想总结简单又常用的!) 先贴一张排序分类图: ...
- 基于python的七种经典排序算法(转)
一.排序的基本概念和分类 所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作.排序算法,就是如何使得记录按照要求排列的方法. 排序的稳定性:经过某种排序后,如果两个 ...
随机推荐
- DAG最小路径点覆盖
Problem 给出一个有向无环图 (\(DAG\)),求出最少使用其中多少条互不相交的路径覆盖所有点. Solution 若有 \(n\) 个点,对于每个点 \(i\) ,我们将它拆成两个点 \(i ...
- Java 基础功底
Java 基础语法特性: 首先了解并做好Java Web 开发环境配置(包含 JDK 的配置)是非常必要的.其中 CLASSPATH 的值开始必须包含 ".",否则用 javac ...
- 草珊瑚的redux使用方式
前言 阮大师写入门教程能力一流. 首推它的Redux三篇入门文章. http://www.ruanyifeng.com/blog/2016/09/redux_tutorial_part_one_bas ...
- HDU3377 Plan
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3377 简单路径要求权值最大,那么为了回避括号序列单独插头的情况特判多,考虑使用最小表示法. #incl ...
- JVM——Java虚拟机架构
0. 前言 Java虚拟机(Java virtualmachine)实现了Java语言最重要的特征:即平台无关性. 平台无关性原理:编译后的 Java程序(.class文件)由 JVM执行.JVM屏蔽 ...
- 懒懒的Rain的寒假小结
快开学了,才发现这个寒假算是又废了,放假前满满的雄心壮志要刷多少多少题回家写一会都不行了,唉,在家真不适合学习.可能还是因为没有学习的气氛吧,在家老是就自己一个人,遇到问题或者出现什么错误了没有人可以 ...
- cookie的常用操作
cookie介绍: 1. cookie的简单介绍就是把用户的登录信息缓存在本机的浏览器中,且最大容量为4KB, 2. 这种存储是不安全的,通常一般会进行加密处理,但是依旧不能做到安全,所以一般要优先考 ...
- [原][粒子特效][spark]事件action
深入浅出spark粒子特效连接:https://www.cnblogs.com/lyggqm/p/9956344.html group调用action的地方: 可以看到使用action的可以是出生一次 ...
- 记录一次在centos下使用gmp的悲伤
有个作业是需要在linux下做的,并且需要用到gmp这个 library : 我使用的是虚拟机centos7.很久没碰过linux了,忘得差不多了,一点点百度出来的 1. 首先检查是否已存在gmp库 ...
- python3+虹软2.0 离线人脸识别 demo
python3+虹软2.0的所有功能整合测试完成,并对虹软所有功能进行了封装,现提供demo主要功能,1.人脸识别2.人脸特征提取3.特征比对4.特征数据存储与比对其他特征没有添加 虹软SDK下载戳这 ...