L1比L2更稀疏
1. 简单列子:
一个损失函数L与参数x的关系表示为:

则 加上L2正则化,新的损失函数L为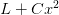 :(蓝线)
:(蓝线)
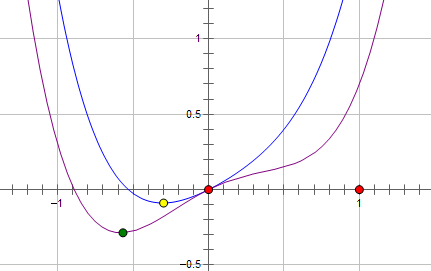
最优点在黄点处,x的绝对值减少了,但依然非零。
如果加上L1正则化,新的损失函数L为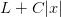 :(粉线)
:(粉线)
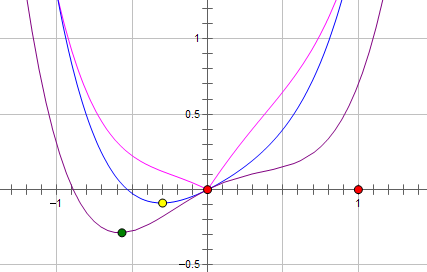
最优点为红点,变为0,L1正则化让参数的最优值变为0,更稀疏。

L1在江湖上人称Lasso,L2人称Ridge。
两种正则化,能不能将最优的参数变为0,取决于最原始的损失函数在0点处的导数,如果原始损失函数在0点处的导数不为0,则加上L2正则化之后(+2Cx),导数依然不为0。而加上L1正则化(导数为-C),如果C大于原先损失函数在0点处的导数的绝对值,x=0就变成了极小值。
2. 概念上理解:

加上正则化约束,要达到最小化损失函数,就是不能随心所欲的取参数的值了,要保证在满足的限制之内。假设有一个参数,L2的限制条件为|w|^2<c,为上图的红线,而L1的限制条件为|w|<c; L1 有角,L2无角
对于L1和L2规则化的代价函数来说,我们可以写成以下形式:

也就是说,我们将模型空间限制在w的一个L1-ball 中。为了便于可视化,我们考虑两维的情况,在(w1, w2)平面上可以画出目标函数的等高线,而约束条件则成为平面上半径为C的一个 norm ball 。等高线与 norm ball 首次相交的地方就是最优解:

可以看到,L1-ball 与L2-ball 的不同就在于L1在和每个坐标轴相交的地方都有“角”出现,而目标函数的测地线除非位置摆得非常好,大部分时候都会在角的地方相交。注意到在角的位置就会产生稀疏性,例如图中的相交点就有w1=0,而更高维的时候(想象一下三维的L1-ball 是什么样的?)除了角点以外,还有很多边的轮廓也是既有很大的概率成为第一次相交的地方,又会产生稀疏性。
相比之下,L2-ball 就没有这样的性质,因为没有角,所以第一次相交的地方出现在具有稀疏性的位置的概率就变得非常小了。这就从直观上来解释了为什么L1-regularization 能产生稀疏性,而L2-regularization 不行的原因了。
因此,一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
3. 概率上理解
如果认为数据是来自高斯密度函数,取对数后就剩一个平方项,这就是L2范式(数据来自高斯分布,应该在代价函数中加入数据先验的高斯密度函数---L2范数)
如果数据稀疏,认为来自于laplace分布,

laplace数据分布时稀疏的,laplace概率密度函数
去对数,剩下一个一次项就是L1范式。加入laplace先验作为正则项的代价函数,说明数据是稀疏的。
L2正则化相当于假设我们所求w的分布为高斯分布,L1对应的先验概率函数为拉普拉斯分布。 高斯分布对大w的概率低,对于小w的概率高,所以它限制w到一个小数,但不为0. 拉普拉斯分布对小w的概率低,希望逼近为0, 对于大w的概率比高斯分布高。
L1 更 容易稀疏化。
为什么正则化能防止过拟合:
过拟合表现在训练数据上的误差非常小,而在测试数据上误差反而增大。其原因一般是模型过于复杂,过分得去拟合数据的噪声和outliers. 正则化则是对模型参数添加先验,使得模型复杂度较小,对于噪声以及outliers的输入扰动相对较小。

因此为了解决过度拟合,有以下两个办法。
&lt;img src="https://pic3.zhimg.com/811f033c45950d743426b9e0d2ab9bce_b.png" data-rawwidth="772" data-rawheight="322" class="origin_image zh-lightbox-thumb" width="772" data-original="https://pic3.zhimg.com/811f033c45950d743426b9e0d2ab9bce_r.png"&gt;
方法一:尽量减少选取变量的数量
具体而言,我们可以人工检查每一项变量,并以此来确定哪些变量更为重要,然后,保留那些更为重要的特征变量。至于,哪些变量应该舍弃,我们以后在讨论,这会涉及到模型选择算法,这种算法是可以自动选择采用哪些特征变量,自动舍弃不需要的变量。这类做法非常有效,但是其缺点是当你舍弃一部分特征变量时,你也舍弃了问题中的一些信息。例如,也许所有的特征变量对于预测房价都是有用的,我们实际上并不想舍弃一些信息或者说舍弃这些特征变量。
方法二:正则化
正则化中我们将保留所有的特征变量,但是会减小特征变量的数量级(参数数值的大小θ(j))。
优化目标,也就是说我们需要尽量减少代价函数的均方误差。因为,如果你在原有代价函数的基础上加上 1000 乘以 参数这一项 ,那么这个新的代价函数将变得很大,所以,当我们最小化这个新的代价函数时, 我们将使 参数 的值接近于 0,就像我们忽略了这个值一样。这种思路就是,如果我们的参数值对应一个较小值的话(参数值比较小),那么往往我们会得到一个形式更简单的假设。
L1比L2更稀疏的更多相关文章
- L1、L2范式及稀疏性约束
L1.L2范式及稀疏性约束 假设需要求解的目标函数为: E(x) = f(x) + r(x) 其中f(x)为损失函数,用来评价模型训练损失,必须是任意的可微凸函数,r(x)为规范化约束因子,用来对模型 ...
- paper 126:[转载] 机器学习中的范数规则化之(一)L0、L1与L2范数
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数(转)
http://blog.csdn.net/zouxy09/article/details/24971995 机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http: ...
- L0、L1与L2范数、核范数(转)
L0.L1与L2范数.核范数 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问题.这里因为篇幅比较庞大 ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数 非常好,必看
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的范数规则化-L0,L1和L2范式(转载)
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 大白话5分钟带你走进人工智能-第十五节L1和L2正则几何解释和Ridge,Lasso,Elastic Net回归
第十五节L1和L2正则几何解释和Ridge,Lasso,Elastic Net回归 上一节中我们讲解了L1和L2正则的概念,知道了L1和L2都会使不重要的维度权重下降得多,重要的维度权重下降得少,引入 ...
- 大白话5分钟带你走进人工智能-第十四节过拟合解决手段L1和L2正则
第十四节过拟合解决手段L1和L2正则 第十三节中, ...
- 4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言 之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松.忆臻.nebulaf91等人的博客以及李航老师的<统计学习方法>后,豁然开朗,于是在此记下一些心得体会. “最大似然估计” ...
随机推荐
- 数据类型+内置方法 python学习第六天
元组 用途:不可变的列表,能存多个值,但多个值只有取的需求而没有改的需求. 定义方式:在()内用逗号分隔开多个元素,可以存放任意类型的值. names=(‘alex’,’blex’,’clex’) 强 ...
- Flask-sqlacodegen
ORM操作有两种方式. 1.模型迁移到数据库中生成表,codefirst:使用flask-migrate: 需要flask-script: from flask_script import Manag ...
- Intent 传递数据
使用INtent 在页面之间跳转,数据传递是必须的,我们可以直接在intent 对象上放置基本数据类型的数据,也可以放置字符串和其他数据类型数据.对于其他数据类型,实现了Parcelable 或Ser ...
- [hgoi#2019/2/16t4]transform
题目描述 植物学家Dustar培养出了一棵神奇的树,这棵有根树有n个节点,每个节点上都有一个数字a[i],而且这棵树的根为r节点. 这棵树非常神奇,可以随意转换根的位置,上一秒钟它的根是x节点,下一秒 ...
- 导出SharePoint2013用户及权限
cls Add-PSSnapin Microsoft.SharePoint.PowerShell -ea 0 $site = New-Object Microsoft.SharePoint.SPSit ...
- 洛谷 P4408 逃学的小孩 解题报告
P4408 [NOI2003]逃学的小孩 题目描述 Chris家的电话铃响起了,里面传出了Chris的老师焦急的声音:"喂,是Chris的家长吗?你们的孩子又没来上课,不想参加考试了吗?&q ...
- Android下载管理DownloadManager功能扩展和bug修改
http://www.trinea.cn/android/android-downloadmanager-pro/ 本文主要介绍如何修改Android系统下载管理,以支持更多的功能及部分bug修改和如 ...
- SDL OPENGL 在linux ubuntu示例
gl画纹理texture /* * SDL OpenGL Tutorial. * (c) Michael Vance, 2000 * briareos@lokigames.com * * Distri ...
- Sublime Text3—系统设置
摘要 软件的设置分为系统设置和快捷键设置两项,这次分享系统设置,Sublime Text3-自带快捷键介绍前面已分享过. 正文 菜单依次选择Preferences | Settings,我们修改设置不 ...
- Solr7.1--- 生产环境搭建
准备三台虚拟机,把Solr-7.1.0.tgz上传到三个节点上.我上传到了自定义的目录/mysoft. 我的环境是CentOS7+Solr7.1.0 如果发现图文不符,因为我之前操作截图后,关闭出去吃 ...