十七. Python基础(17)--正则表达式
十七. Python基础(17)--正则表达式
1 ● 正则表达式
|
定义: Regular expressions are sets of symbols that you can use to create searches for finding and replacing patterns of text. |
|
零宽断言(zero width assertion): 零宽断言--不是去匹配字符串文本,而是去匹配位置(开头, 结尾也是位置)。 常见的: ① 起始位置^(单行)和/A(多行), ② 末尾位置 $(单行)和/Z(多行) ③ 单词边界/b, 非单词边界/B等等。 ④ (?=exp): 匹配后面是exp的位置 (?!exp): 匹配后面不是exp的位置 (?<=exp): 匹配前面是exp的位置 (?<!exp): 匹配前面不是exp的位置 (?#exp): 表示括号内是注释
※ |
|
参考文章: ① 正则基础 http://www.cnblogs.com/Eva-J/articles/7228075.html#_label10 http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html http://www.runoob.com/regexp/regexp-metachar.html ② 向后引用(回溯引用)以及零宽断言 http://www.cnblogs.com/linux-wangkun/p/5978462.html http://www.cnblogs.com/leezhxing/p/4333773.html |
2 ● 正则的难点示例
|
① \b匹配这样的位置: 简单来说: 单词边界(word boundary) 具体来说: 它的前一个字符和后一个字符不全是(一个是, 一个不是或不存在)\w. 例如: a!bc, 经过如下替换:
结果变成: !bc
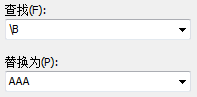
② \B匹配这样的位置: 简单来说: 非单词边界(not word boundary) 例如: ab cd ef, 经过如下替换:
结果变成: aAAAb cAAAd eAAAf
③ abc ab,c
AaAbAcA AaAb,AcA
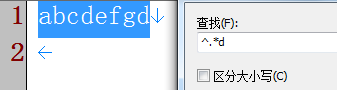
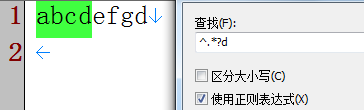
④ 匹配不包括逗号的行 abcd abcd, ,abcd ab,cd
^((?!,).)*$表示不包括逗号","的行 ^((?<!,).)*$不能表示不包括逗号的行, 因为会把"abc,"这种情况也错误匹配上 ※ ^((?![A-Za-z]).)*$
※ ^((?!^[0-9]).)*$
※ (?<!(^))'''或者(?<!^)'''
※ (?<=\()\S+(?=\))
⑤(?#expr) 2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)
⑥ 贪婪(greedy)与非贪婪(non-greedy) 贪婪—尽可能多地重复
非贪婪—尽可能少地重复
|

 结果是:
结果是: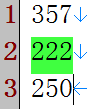
3 ● python反向引用(back-reference)
|
import re text = "Hello Arroz, Nihao Arroz" rep = re.sub(r"Hello (\w+), Nihao \1", "GOOD", text) # GOOD rep = re.sub(r"Hello (\w+), Nihao \1", "\g<1>", text) # Arroz rep = re.sub(r"Hello (\w+), Nihao \1", "\g<0>", text) # Hello Arroz, Nihao Arroz |
|
※ (...) matches whatever regular expression is inside the parentheses, and indicates the start and end of a group. ※ \g<N> 是用来反向引用(backreferences)的; 如果N是正数, 那么\g<N> 匹配(对应) 从左边数起,第N个括号里的内容; 例如上面的\g<1>匹配Arroz 如果N是0,那么\g<N> 匹配(对应) 整个字符串的内容; 例如上面的\g<0>匹配Hello Arroz, Nihao Arroz |
|
详见: http://blog.5ibc.net/p/80058.html |
4 ● 反向引用的案例
|
match(pattern, string, flags=0) returns the first match(返回_sre.SRE_Match对象) from the beginning of the string, if any; otherwise, a "NoneType" object. search(pattern, string, flags=0) returns the first match(返回_sre.SRE_Match对象) within the whole string, if any; otherwise, a "NoneType" object. ※ flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
findall() returns a list of all non-overlapping matches(in the tuple form), if any; otherwise, an empty list. finditer() return an iterator yielding match objects over all non-overlapping matches for the RE pattern in string, if any; otherwise, an empty generator.
match(string[, pos[, endpos]])方法在字符串开头或指定位置进行搜索,模式必须出现在字符串开头或指定位置; search(string[, pos[, endpos]])方法在整个字符串或指定范围中进行搜索; findall(string[, pos[, endpos]])方法在字符串指定范围中查找所有符合正则表达式的字符串并以列表形式返回。 |
|
m.group() == m.group(0) == 返回模式(pattern)匹配的所有字符,与括号无关 m.group(N) 返回第N组括号(第N个子模式(subpattern))匹配的字符 m.groups() |
|
import re pat = re.compile(r"(\d{4})-(\d{2})-(\d{2})") m1 = re.match(pat, "2017-09-10, 2017-09-11") print(m1.groups()) # ('2017', '09', '10') print(m1.group()) # '2017-09-10' print(m1.group(0)) #'2017-09-10' ''' m1.group(1) #'2017' m1.group(2) # '09' m1.group(1,2) #('2017', '09') m1.group(3) # '10' m1.group(4) Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: no such group '''
m2 = re.search(pat, "2017-09-10, 2017-09-11") m2.groups() # ('2017', '09', '10') m2.group() # '2017-09-10' ''' m2.group(0) # '2017-09-10' m2.group(1) # '2017' m2.group(2) # '09' m2.group(3) # '10' m2.group(4) Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: no such group '''
lst = re.findall(pat, "2017-09-10, 2017-09-11") print(lst) # [('2017', '09', '10'), ('2017', '09', '11')]
it = re.finditer(pat, "2017-09-10, 2017-09-11") print(it) # <callable_iterator object at 0x0000000002943A20> print('--------------')
for matchnum, match in enumerate(it): print(match.group()) print(match.groups()) for group_num in range(0, len(match.groups())): group_num +=1 print(match.group(group_num)) ''' 2017-09-10 ('2017', '09', '10') 2017 09 10 2017-09-11 ('2017', '09', '11') 2017 09 11 ''' |
5 ● 命名分组(named grouping)
|
反斜杠加g以及中括号内一个名字,即:\g<name>,对应着命了名的组,named group (?P<name>expr)是分组(grouping): 除了原有的编号外, 再给匹配到的字符串expr指定一个额外的别名 (?P=expr)是反向引用/回溯(back reference): 引用别名为<name>的分组匹配到的字符串
text = "Hello Arroz, Nihao Arroz" ret = re.sub(r"Hello (?P<name>\w+), Nihao (?P=name)", "\g<name>",text) print(ret) # Arroz 注意: (?P=name)是反向引用(reference), (?<name>) |
|
import re m = re.search(r"\d{4}-(?P<na>\d{2})-\d{2}", "2006-09-03") print(m.group('na')) # 09 |
|
import re m = re.search(r'(\d{4})-(?:\d{2})-(\d{2})', "2006-09-03") # Non-capturing group(非捕获组) m.groups() # ('2006', '03') m.group(1) # '2006' m.group(2) # '03' # (?:\d{2})这一组被忽略 m.group(3) ''' Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: no such group ''' |
※ MatchObject的另外几个方法:
|
groupdict(default=None):返回包含匹配的所有命名子模式内容的字典 start([group]):返回指定子模式内容的起始位置 end([group]):返回指定子模式内容的结束位置的前一个位置 span([group]):返回一个包含指定子模式内容起始位置和结束位置前一个位置的元组。 |
|
import re text = "Hello Arroz, Nihao Alex" pat=re.compile(r"Hello (?P<name1>\w+), Nihao (?P<name2>\w+)") mo= re.search(pat, text) print(mo.group('name1')) # Arroz print(mo.groupdict()) # {'name1': 'Arroz', 'name2': 'Alex'} print(mo.span()) # (0, 23) print(mo.span(0)) # (0, 23) print(mo.span(1)) # (6, 11) print(mo.start(1)) # 6 print(mo.end(1)) # 11 print(mo.span(2)) # (19, 23) |
|
# fullmatch(pattern, string, flags=0) 尝试把模式作用于整个字符串,返回match对象或None import re text = "Hello Arroz, Nihao Alex" pat=re.compile(r"Hello (?P<name1>\w+), Nihao (?P<name2>\w+)") is_full_match = re.fullmatch(pat, text) print("isfullmatch:", is_full_match) # isfullmatch: <_sre.SRE_Match object; span=(0, 23), match='Hello Arroz, Nihao Alex'> # 如果不完全匹配, 返回:isfullmatch: None |
|
# escape(string) 将字符串中所有的非字母, 非数字字符转义(escape all non-alphanumerics) print(re.escape('http://www.py thon.org')) # http\:\/\/www\.py\ thon\.org→Pycharm的结果 # 'http\\:\\/\\/www\\.py\\ thon\\.org'→cmd的结果 |
|
# expand(template) 将匹配到的分组代入template中然后返回。template中可以使用 \id 、\g<id> 、\g<name> 引用分组。id为捕获组的编号,name为命名捕获组的名字。 import re s="abcdefghijklmnopqrstuvwxyz" pattern=r'(\w)(\w)(\w)(\w)(\w)(\w)(\w)(\w)(\w)(\w)(\w)(\w)(\w)' m=re.search(pattern,s) print(m.expand(r'\1'), m.expand(r'\10'), m.expand(r'\g<10>')) # a j j
# purge() 清空正则表达式缓存 |
6 ● 文本编辑器(EmEditor, NotePad++)中匹配汉字字符
|
Python中匹配汉字字符, 用平时见到的统一字名的形式就可以了: [\u4e00-\u9fa5] 但是在文本编辑器(EmEditor, NotePad++)中, 需要把上面的形式改为(x表示十六进制): [\x{4e00}-\x{9fa5}] 或者: [一-龥] 就可以实现匹配中文了.
单独的统一字名加不加中括号都可以. |
|
详见:http://www.crifan.com/answer_question_notepadplusplus_regular_expression_match_chinese_character |
● 补充
|
\num 此处的num是一个正整数。例如,"(.)\1"匹配两个连续的相同字符, 如abccde \f 换页符匹配 |
十七. Python基础(17)--正则表达式的更多相关文章
- python基础(17):正则表达式
1. 正则表达式 1.1 正则表达式是什么 正则表达式本身也和python没有什么关系,就是匹配字符串内容的一种规则. 官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符 ...
- Python基础之 正则表达式指南
本文介绍了Python对于正则表达式的支持,包括正则表达式基础以及Python正则表达式标准库的完整介绍及使用示例.本文的内容不包括如何编写高效的正则表达式.如何优化正则表达式,这些主题请查看其他教程 ...
- python基础之正则表达式
正则表达式语法 正则表达式 (或 RE) 指定一组字符串匹配它;在此模块中的功能让您检查一下,如果一个特定的字符串匹配给定的正则表达式 (或给定的正则表达式匹配特定的字符串,可归结为同一件事). 正则 ...
- Python高手之路【五】python基础之正则表达式
下图列出了Python支持的正则表达式元字符和语法: 字符点:匹配任意一个字符 import re st = 'python' result = re.findall('p.t',st) print( ...
- python基础之正则表达式和re模块
正则表达式 就其本质而言,正则表达式(或 re)是一种小型的.高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现.正则表达式模式被编译成一系列的字节码,然后由用 ...
- python基础之 正则表达式,re模块
1.正则表达式 正则表达式:是字符串的规则,只是检测字符串是否符合条件的规则而已 1.检测某一段字符串是否符合规则 2.将符合规则的匹配出来re模块:是用来操作正则表达式的 2.正则表达式组成 字符组 ...
- python基础-RE正则表达式
re 正则表示式 正则表达式(或 RE)是一种小型的.高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现.正则表达式模式被编译成一系列的字节码,然后由用 C 编写 ...
- python基础之正则表达式。
简介 就其本质而言,正则表达式是内嵌在python内,由re模块实现,小型的专业化语言,最后由c写的匹配引擎执行.正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来 ...
- Python开发【第一篇】Python基础之正则表达式补充
正则表达式 一简介:就其本质而言,正则表达式(或RE)是一种小型的.高度专业化的标称语言,(在Python中)它内嵌在Python中,并通过re模块实现.正则表达式模式被编译成一系列的字节码,然后由用 ...
随机推荐
- Axure XMind整理交互思路
本部分主要是为了研究Xmind思维导图总结设计原型的思路
- (转)C# System.Diagnostics.Process.Start使用
经常会遇到在Winform或是WPF中点击链接或按钮打开某个指定的网址, 或者是需要打开电脑中某个指定的硬盘分区及文件夹, 甚至是"控制面板"相关的东西, 如何做呢? 方法:使用 ...
- idea maven环境下 java实现发送邮件验证
1.开通smtp授权 QQ邮箱-设置-账户-开启 得到一个授权码 2.下载javax.email包 maven项目中 pom文件加入: <dependency> <groupId&g ...
- [maven] introduction to the standard directory layout
The next section documents the directory layout expected by Maven and the directory layout created b ...
- English trip V1 - B 19. Life of Confucius 孔子的生活 Teacher:Patrick Key:
In this lesson you will learn to describe a daily routine. (日常生活) 课上内容(Lesson) 词汇(Key Word ) contrac ...
- Confluence 6 从一个模板中创建一个空间
Confluence 已经存储了一系列的模板,这些模板被称为 空间蓝图(space blueprints),这模板具有一些自定义的主页,边栏或者可能有蓝图页面或一些示例内容来帮助你开始使用 Confl ...
- python2.7 目录下没有scripts
1.python2.7 配置环境完成或,python目录下没有scripts目录,先下载setuptools,cmd下载该目录下,输入python setup.py install 2.完成后,pyt ...
- Linux系统常见内核问题修复(转发)
Linux系统常见内核问题修复(转发) 常见Linux系统破坏修复 http://blog.csdn.net/jmilk/article/details/49619587
- Ugly Number II leetcode java
问题描述: Write a program to find the n-th ugly number. Ugly numbers are positive numbers whose prime fa ...
- csu oj 1342: Double
Description 有一个由M个整数组成的序列,每次从中随机取一个数(序列中每个数被选到的概率是相等的)累加,一共取N次,最后结果能被3整除的概率是多少? Input 输入包含多组数据. ...