Solr索引配置
Solr主配置文件
schema.xml,在SolrCore的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的。主要包括FieldTypes、Fields和其他的一些缺省设置。

fieldType
打开这个配置文件,我们可以看到许多fieldType标签,string、int什么的,其中我们拿text_general来举例分析:
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
FieldType子结点包括:name,class,positionIncrementGap等一些参数:
1、name:是这个FieldType的名称
2、class:是Solr提供的包solr.TextField,solr.TextField允许用户通过分析器来定制索引和查询,分析器包括一个分词器(tokenizer)和多个过滤器(filter)
3、positionIncrementGap:可选属性,定义在同一个文档中此类型数据的空白间隔,避免短语匹配错误,此值相当于Lucene的短语查询设置slop值,根据经验设置为100。
在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括
1、分词和过滤索引分析器中:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilterFactory停用词过滤器,solr.LowerCaseFilterFactory小写过滤器。
2、搜索分析器中:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilterFactory停用词过滤器,这里还用到了solr.SynonymFilterFactory同义词过滤器。
field
在schema.xml中除了fieldType占有大量篇幅外,还有field,以下是一部分
<field name="name" type="text_general" indexed="true" stored="true"/>
<field name="features" type="text_general" indexed="true" stored="true"multiValued="true"/>
在fields结点内定义具体的Field,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否存储多个值)等属性。
multiValued:该Field如果要存储多个值时设置为true,solr允许一个Field存储多个值,比如存储一个用户的好友id(多个),商品的图片(多个,大图和小图),通过使用solr查询要看出返回给客户端是数组:

UniqueKey
Solr中默认定义唯一主键key为id域,Solr在删除、更新索引时使用id域进行判断,也可以自定义唯一主键。
<uniqueKey>id</uniqueKey>
copyField
copyField复制域,可以将多个Field复制到一个Field中,以便进行统一的检索:
<copyField source="title" dest="text"/>
<copyField source="author" dest="text"/>
<copyField source="description" dest="text"/>
<copyField source="keywords" dest="text"/>
<copyField source="content" dest="text"/>
比如,输入关键字搜索title标题内容content,定义title、content、text的域,根据关键字只搜索text域的内容就相当于搜索title和content,将title和content复制到text中。
dynamicField
动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个 dynamicField,name为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。
配置中文分词器
网上下载好相应版本的IKAnalyzer,拷贝IKAnalyzer的文件到Web容器下,以tomcat为例,Solr目录中将IKAnalyzer2012FF_u1.jar拷贝到 Tomcat的webapps/solr/WEB-INF/lib 下。在Tomcat的webapps/solr/WEB-INF/下创建classes目录,将IKAnalyzer.cfg.xml、stopword.dic ext.dic 复制到 Tomcat的webapps/solr/WEB-INF/classes,stopword.dic 和ext.dic必须保存成无BOM的utf-8类型(一般默认就这样)。
IKAnalyzer.cfg.xml修改字典引用
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
修改Solr的schema.xml文件,添加FieldType:
<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false"class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true"class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
solr配置文件中有的域我们才能进行update提交数据,不然插不进数据也便无法为这类数据建立索引。根据需求配置自定义域,这样我们才能够插入字段product_name。
<!--IKAnalyzer Field-->
<field name="product_name" type="text_ik" indexed="true" stored="true" />
未配置product_name前插入数据:
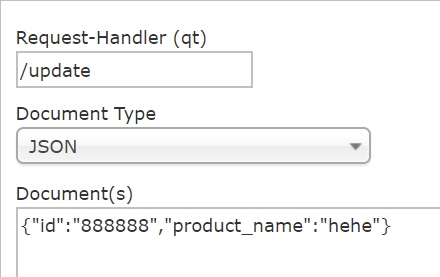
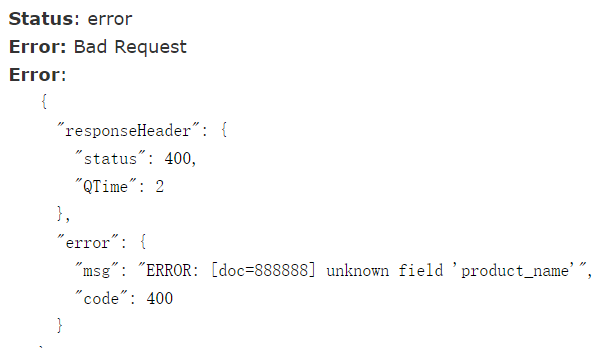
配置域后,就能插product_name了:

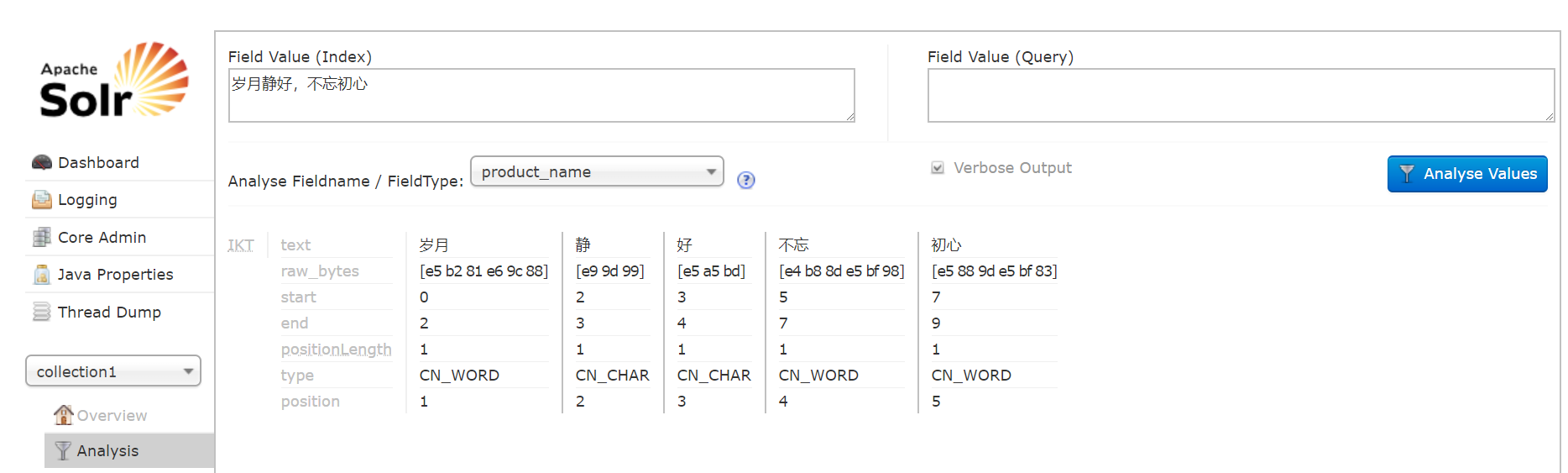
接下来测试中文分词(),可流畅分词,如果有需要,可以在ext.dic设置自定义词汇。
Solr索引配置的更多相关文章
- 使用Solr索引MySQL数据
环境搭建 1.到apache下载solr,地址:http://mirrors.hust.edu.cn/apache/lucene/solr/ 2.解压到某个目录 3.cd into D:\Solr\s ...
- solr多核配置
假设已经配置好了一个单core的solr服务器. solr.xml配置文件 单核和多核主要在solr.xml配置不同.在solr/example中已经有一个名称为multicore的文件夹里面给我们配 ...
- 将数据库表导入到solr索引
将数据库表导入到solr索引 编辑solrcofnig.xml添加处理器 <requestHandler name="/dataimport" class="org ...
- 使用solrj操作solr索引库
(solrj)初次使用solr的开发人员总是很郁闷,不知道如何去操作solr索引库,以为只能用<五分钟solr4.5教程(搭建.运行)>中讲到的用xml文件的形式提交数据到索引库,其实没有 ...
- 使用solrj操作solr索引库,solr是lucene服务器
客户端开发 Solrj 客户端开发 Solrj Solr是搭建好的lucene服务器 当然不可能完全满足一般的业务需求 可能 要针对各种的架构和业务调整 这里就需要用到Solrj了 Solrj是Sol ...
- 将数据库的数据导入solr索引库中
在solr与tomcat整合文章中,我用的索引库是mycore,现在就以这个为例. 首先要准备jar包:solr-dataimporthandler-4.8.1.jar.solr-dataimport ...
- 如何在分布式环境中同步solr索引库和缓存信息
天气依旧很好,主要是凉快.老习惯,我在北京向各位问好. 搜索无处不在,相信各位每天都免不了与它的亲密接触,那么我想你确实有必要来了解一下它们,就上周在公司实现的一个小需求来给各位分享一下:如何在分布式 ...
- Solr(六)Solr索引数据存放到HDFS下
Solr索引数据存放到HDFS下 一 新建solr core hdfs 方法:http://www.cnblogs.com/Matchman/p/7287385.html 二 修改solrconfig ...
- Solr 06 - Solr中配置使用IK分词器 (配置schema.xml)
目录 1 配置中文分词器 1.1 准备IK中文分词器 1.2 配置schema.xml文件 1.3 重启Tomcat并测试 2 配置业务域 2.1 准备商品数据 2.2 配置商品业务域 2.3 配置s ...
随机推荐
- http协议下载文件
通过在 URL 上调用 openConnection 方法创建连接对象.(HttpURLConnection conn = (HttpURLConnection)new URL("网址&qu ...
- [LeetCode] 278. First Bad Version_Easy tag: Binary Search
You are a product manager and currently leading a team to develop a new product. Unfortunately, the ...
- [Java] Create File with java.io.File class
Create a file with some content in some specific location. The reference is here. /** * Write fileCo ...
- js模拟栈---汉诺塔
var Stack = (function(){ var items = new WeakMap(); //先入后出,后入先出 class Stack{ constructor(){ items.se ...
- CentOS6.5安装Elasticsearch5.3.0
1. 首页到官方网站下载最新安装包 https://www.elastic.co/downloads/elasticsearch elasticsearch-5.3.0.tar.gz 2. 将软件包上 ...
- leetcode473 Matchsticks to Square
一开始想求所有结果为target的组合来着,但是所选元素不能重叠.用这个递归思想很简单,分成四个桶,每次把元素放在任意一个桶里面,最后如果四个桶相等就可以放进去,有一个地方可以剪枝,假如任意一个桶的元 ...
- 第一次使用theos自己遇到的坑
这里自己遇到的一些问题,总结一下: 第一个问题建立好theos工程后make出现 xcrun: error: SDK "iphoneos" cannot be located xc ...
- 办法总比困难多--JMeter压测小记
标签: JMeter, 代理接口 前段时间溢+支付接口慢,有商户直接反映掉单严重.这时,我接到了压测溢+支付接口的任务.JMeter我并不熟悉,公司也没有搞自动化测试的QA,一开始team里的一个同学 ...
- jQuery-导航下拉菜单-实用简单
/*CSS代碼*/ /*導航*/ .nav{background: url("../img/menu_bar.gif") repeat-x;} .nav ul li{display ...
- python多版本控制
1安装git # yum install git -y 2.安装python依赖 # yum -y install gcc make patch gdbm-devel openssl-devel sq ...