[django]django查询最佳实战
from django.db.models import Max, Min, Sum, Avg, Count, Q, F
Django中的F和Q函数
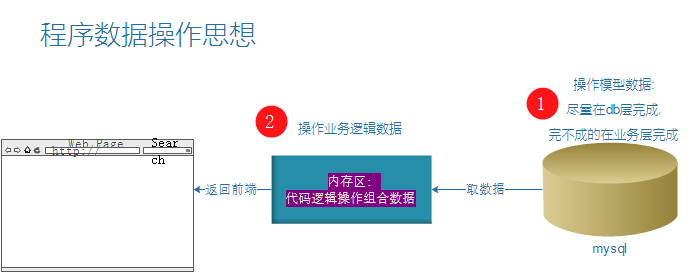
一、F介绍
作用:操作数据表中的某列值,F()允许Django在未实际链接数据的情况下具有对数据库字段的值的引用,不用获取对象放在内存中再对字段进行操作,直接执行原生产sql语句操作。
通常情况下我们在更新数据时需要先从数据库里将原数据取出后方在内存里,然后编辑某些属性,最后提交。例如:(先在业务逻辑层完成计算, 后再db层完成一次性更新)
obj = Order.objects.get(orderid='12')
obj.amount += 1
obj.order.save()
上述方法生成的sql语句为:
UPDATE `core_order` SET ..., `amount` = 22 WHERE `core_order`.`orderid` = '12' # ...表示Order中的其他值,在这里会重新赋一遍值; 22表示为计算后的结果
但是我们本意想生成的sql语句为:(业务逻辑层不做处理, 直接在sql层完成运算.)
UPDATE `core_order` SET ..., `amount` = `amount` + 1 WHERE `core_order`.`orderid` = '12'
此时F的使用场景就在于此:
from django.db.models import F
from core.models import Order
obj = Order.objects.get(orderid='12')
obj.amount = F('amount') + 1
obj.save()
#生成的sql语句为:
UPDATE `core_order` SET ..., `amount` = `core_order`.`amount` + 1 WHERE `core_order`.`orderid` = '12' # 和预计的一样
当Django程序中出现F()时,Django会使用SQL语句的方式取代标准的Python操作。
上述代码中不管 order.amount 的值是什么,Python都不曾获取过其值,python做的唯一的事情就是通过Django的F()函数创建了一条SQL语句然后执行而已。

需要注意的是在使用上述方法更新过数据之后需要重新加载数据来使数据库中的值与程序中的值对应:
order= Order.objects.get(pk=order.pk)
或者使用更加简单的方法:
order.refresh_from_db()
参考博客:http://www.tuicool.com/articles/u6FBRz
官方地址:https://docs.djangoproject.com/en/1.11/ref/models/expressions/
二、Q介绍
Q支持and和or. 一般用他的or功能
作用:对对象进行复杂查询,并支持&(and),|(or),~(not)操作符。
基本使用:
from django.db.models import Q
search_obj=Asset.objects.filter(Q(hostname__icontains=keyword)|Q(ip=keyword))
如果查询使用中带有关键字查询,Q对象一定要放在前面
Asset.objects.get(
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)),
question__startswith='Who')
#查询评论数大于50或者阅读数大于50的书,并且价格小于100
models.Book.objects.filter(Q(Q(comment_num__gt=50)|Q(read_num__gt=50))&Q(price__lt=100))
错误使用方法
models.Book.objects.filter(price__lt=100,Q(comment_num__gt=10)|Q(read_num__lt=100))
#这是错误的写法,price__lt=100必须放在条件的最后面
参考:
博客:http://www.cnblogs.com/linjiqin/p/3817814.html
官网地址:https://docs.djangoproject.com/en/1.11/topics/db/queries/#complex-lookups-with-q
django中聚合aggregate和annotate GROUP BY的使用方法
什么叫聚合? (聚合函数可以单独使用,不一定要和分组组合用)
- 查询学生总人数
select count(name) from students;
常见的聚合函数有AVG / COUNT / MAX / MIN /SUM 等。除了 COUNT 以外,聚合函数都会忽略空值。
from django.db.models import Max, Min, Sum, Avg, Count, Q, F
什么叫分组?(聚合函数通常会和分组组合用)
- 以每个班级分组(以班级为维度), 统计每个班级的人数
select count(name) from students group by class;
aggregate和annotate的区别:
- aggregate(聚合函数)
Book.objects.all().aggregate(Avg('price'))
- annotate = aggregate + GROUP BY # category annotate 类别标注
MessageTab.objects.values_list('msg_status').annotate(Count('id'))
SELECT `message_tab`.`msg_status`, COUNT(`message_tab`.`id`) AS `id__count` FROM `message_tab` GROUP BY `message_tab`.`msg_status` ORDER BY NULL;
1. 通过annotate之前values_list的来进行group by. 本例中通过msg_status来groupby.
2. MessageTab.objects.values_list('msg_status').annotate(Count('id')).values('id'), 最后一个values显示id列.
注: aggregate返回结果是个字典,是queryset的终止语句。而annotate返回的是一个queryset,可以链式调用(我发现aggregate方法不能调用query)
MessageTab.objects.values('msg_status').annotate(Avg("src_svc_id")).values('src_svc_id').query
Django ORM常用操作介绍(新手必看)
基础操作
| orm | sql | 作用 |
|---|---|---|
| User.objects.all() | select * from User | 获取所有数据 |
| User.objects.filter(name='毛台') | select * from User where name = '毛台' | 匹配 |
| User.objects.exclude(name='毛台') | select * from User where name != '毛台' | 不匹配 |
| User.objects.get(id=123) | select * from User where id = 724 | 获取单条数据(有且仅有一条,id唯一) |
常用操作
__gt __get __lt
__in
__isnull
__contains
__icontains
__range
__startswith __endswith
__istartswith __iendswith
.count()
.order("-d", "name")
(Q()|Q())&Q()
# 获取总数,对应SQL:select count(1) from User
User.objects.count()
# 获取总数,对应SQL:select count(1) from User where name = '毛台'
User.objects.filter(name='毛台').count()
# 大于,>,对应SQL:select * from User where id > 724
User.objects.filter(id__gt=724)
# 大于等于,>=,对应SQL:select * from User where id >= 724
User.objects.filter(id__gte=724)
# 小于,<,对应SQL:select * from User where id < 724
User.objects.filter(id__lt=724)
# 小于等于,<=,对应SQL:select * from User where id <= 724
User.objects.filter(id__lte=724)
# 同时大于和小于, 1 < id < 10,对应SQL:select * from User where id > 1 and id < 10
User.objects.filter(id__gt=1, id__lt=10)
# 包含,in,对应SQL:select * from User where id in (11,22,33)
User.objects.filter(id__in=[11, 22, 33])
# 不包含,not in,对应SQL:select * from User where id not in (11,22,33)
User.objects.exclude(id__in=[11, 22, 33])
# 为空:isnull=True,对应SQL:select * from User where pub_date is null
User.objects.filter(pub_date__isnull=True)
# 不为空:isnull=False,对应SQL:select * from User where pub_date is not null
User.objects.filter(pub_date__isnull=True)
# 匹配,like,大小写敏感,对应SQL:select * from User where name like '%sre%',SQL中大小写不敏感
User.objects.filter(name__contains="sre")
# 匹配,like,大小写不敏感,对应SQL:select * from User where name like '%sre%',SQL中大小写不敏感
User.objects.filter(name__icontains="sre")
# 不匹配,大小写敏感,对应SQL:select * from User where name not like '%sre%',SQL中大小写不敏感
User.objects.exclude(name__contains="sre")
# 不匹配,大小写不敏感,对应SQL:select * from User where name not like '%sre%',SQL中大小写不敏感
User.objects.exclude(name__icontains="sre")
# 范围,between and,对应SQL:select * from User where id between 3 and 8
User.objects.filter(id__range=[3, 8])
# 以什么开头,大小写敏感,对应SQL:select * from User where name like 'sh%',SQL中大小写不敏感
User.objects.filter(name__startswith='sre')
# 以什么开头,大小写不敏感,对应SQL:select * from User where name like 'sh%',SQL中大小写不敏感
User.objects.filter(name__istartswith='sre')
# 以什么结尾,大小写敏感,对应SQL:select * from User where name like '%sre',SQL中大小写不敏感
User.objects.filter(name__endswith='sre')
# 以什么结尾,大小写不敏感,对应SQL:select * from User where name like '%sre',SQL中大小写不敏感
User.objects.filter(name__iendswith='sre')
# 排序,order by,正序,对应SQL:select * from User where name = '毛台' order by id
User.objects.filter(name='毛台').order_by('id')
# 多级排序,order by,先按name进行正序排列,如果name一致则再按照id倒叙排列
User.objects.filter(name='毛台').order_by('name','-id')
# 排序,order by,倒序,对应SQL:select * from User where name = '毛台' order by id desc
User.objects.filter(name='毛台').order_by('-id')
进阶操作
# limit,对应SQL:select * from User limit 3;
User.objects.all()[:3]
# limit,取第三条以后的数据,没有对应的SQL,类似的如:select * from User limit 3,10000000,从第3条开始取数据,取10000000条(10000000大于表中数据条数)
User.objects.all()[3:]
# offset,取出结果的第10-20条数据(不包含10,包含20),也没有对应SQL,参考上边的SQL写法
User.objects.all()[10:20]
# 分组,group by,对应SQL:select username,count(1) from User group by username;
from django.db.models import Count
User.objects.values_list('username').annotate(Count('id'))
# 去重distinct,对应SQL:select distinct(username) from User
User.objects.values('username').distinct().count()
# filter多列、查询多列,对应SQL:select username,fullname from accounts_user
User.objects.values_list('username', 'fullname')
# filter单列、查询单列,正常values_list给出的结果是个列表,里边里边的每条数据对应一个元组,当只查询一列时,可以使用flat标签去掉元组,将每条数据的结果以字符串的形式存储在列表中,从而避免解析元组的麻烦
User.objects.values_list('username', flat=True)
# int字段取最大值、最小值、综合、平均数
from django.db.models import Sum,Count,Max,Min,Avg
User.objects.aggregate(Count(‘id’))
User.objects.aggregate(Sum(‘age’))
时间字段
# 匹配日期,date
User.objects.filter(create_time__date=datetime.date(2018, 8, 1))
User.objects.filter(create_time__date__gt=datetime.date(2018, 8, 2))
# 匹配年,year
User.objects.filter(create_time__year=2018)
User.objects.filter(create_time__year__gte=2018)
# 匹配月,month
User.objects.filter(create_time__month__gt=7)
User.objects.filter(create_time__month__gte=7)
# 匹配日,day
User.objects.filter(create_time__day=8)
User.objects.filter(create_time__day__gte=8)
# 匹配周,week_day
User.objects.filter(create_time__week_day=2)
User.objects.filter(create_time__week_day__gte=2)
# 匹配时,hour
User.objects.filter(create_time__hour=9)
User.objects.filter(create_time__hour__gte=9)
# 匹配分,minute
User.objects.filter(create_time__minute=15)
User.objects.filter(create_time__minute_gt=15)
# 匹配秒,second
User.objects.filter(create_time__second=15)
User.objects.filter(create_time__second__gte=15)
# 按天统计归档
today = datetime.date.today()
select = {'day': connection.ops.date_trunc_sql('day', 'create_time')}
deploy_date_count = Task.objects.filter(
create_time__range=(today - datetime.timedelta(days=7), today)
).extra(select=select).values('day').annotate(number=Count('id'))
Q的使用
例如下边的语句
from django.db.models import Q
User.objects.filter(
Q(role__startswith='sre_'),
Q(name='公众号') | Q(name='毛台')
)
转换成SQL语句如下:
select * from User where role like 'sre_%' and (name='公众号' or name='毛台')
sql去重复操作详解SQL中distinct的用法
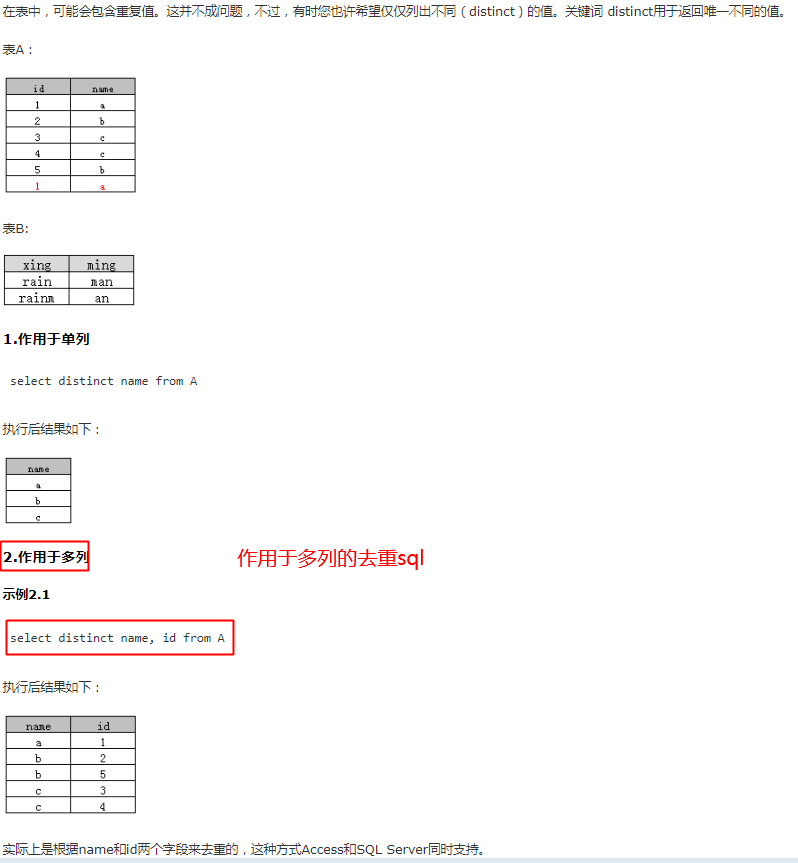
对应到orm
Blog.objects.values('title', 'subtitle').distinct().query
anonate例子
In [26]: print(Book.objects.annotate(price_diff=Max('price', output_field=FloatField())
...: - Avg('price')).query)
SELECT `app02_book`.`id`, `app02_book`.`name`, `app02_book`.`pages`, `app02_book`.`price`, `app02_book`.`rating`, `app02_book`.`publisher_id`, `app02_book`.`pubdate`, (MAX(`app02_book`.`price`) - AVG(`app02_book`.`price`)) AS `price_diff` FROM `app02_book` GROUP BY `app02_book`.`id` ORDER BY NULL
concat

django-聚合、分组、F查询和Q查询、总结
聚合查询
from django.db.models import Max,Avg,F,Q,Min,Count,Sum
models.Book.objects.all().aggregate(Avg("price"),Max("price"),Min("price"),Sum("price"))
分组查询
queryset extra实现字段别名和queryset的合并

[django]django查询最佳实战的更多相关文章
- django orm查询和后端缓存的使用
django orm 查询 1 字段后(db_column='age') (null=True)#表示数据库里面的该字段数据可以为空 (blank=True)#表示前端表单提交的时候可以为空 (db_ ...
- Django 1.6 最佳实践: 如何设置django项目的设置(settings.py)和部署文件(requirements.txt)
Django 1.6 最佳实践: 如何设置django项目的设置(settings.py)和部署文件(requirements.txt) 作者: Desmond Chen,发布日期: 2014-05- ...
- Django ORM 查询管理器
Django ORM 查询管理器 ORM 查询管理器 对于 ORM 定义: 对象关系映射, Object Relational Mapping, ORM, 是一种程序设计技术,用于实现面向对象编程语言 ...
- Django 数据库查询集合(双下划线连表操作)
Django是一款优秀的web框架,有着自己的ORM数据库模型.在项目中一直使用django数据库,写一篇文章专门记录一下数据库操作.略写django工程创建过程,详写查询过程.可以和sqlalche ...
- django数据查询之聚合查询和分组查询
<1> aggregate(*args,**kwargs): 通过对QuerySet进行计算,返回一个聚合值的字典.aggregate()中每一个参数都指定一个包含在字典中的返回值.即在查 ...
- django聚合查询
聚合¶ Django 数据库抽象API 描述了使用Django 查询来增删查改单个对象的方法.然而,有时候你需要获取的值需要根据一组对象聚合后才能得到.这份指南描述通过Django 查询来生成和返回聚 ...
- Django(ORM查询联系题)
day70 练习题:http://www.cnblogs.com/liwenzhou/articles/8337352.html import os import sys if __name__ == ...
- Django(ORM查询2)
day70 ORM训练专题 :http://www.cnblogs.com/liwenzhou/articles/8337352.html 内容回顾 1. ORM 1. ORM ...
- Django(ORM查询1)
day69 参考:http://www.cnblogs.com/liwenzhou/p/8660826.html 在Python脚本中调用Django环境 orm1.py import os if _ ...
随机推荐
- 【laravel5.6】 laravel 执行 php artisan route:cache 报错 Unable to prepare route [/] for serialization. Uses Closure.
laravel 在部署的时候.需要优化路由加载,执行命令 php artisan route:cache 报错了.如下 这个异常的错误信息,提示的已经非常明确了:大概意思就是说在闭包里边,是不能够进行 ...
- eclipse搭建j2ee
Tomcat环境变量设置,分别添加3个系统变量 CATALINA_BASE E:/tomcat7 CATALINA_HOME E:/tomcat7 CATALINA_TMPDIR Etomcat7/t ...
- 电子产品使用感受之--Windows 10 小米笔记本Air HDMI转VGA无信号问题
最近一直通过HDMI转VGA线缆链接我的戴尔P2314H显示器,前天睡觉前,看到电脑上英伟达显卡推了驱动更新,顺手更新了一下,就去睡觉了,转天晚上再用,HDMI接口就没有信号了,上网查了一些信息,获知 ...
- python中的过滤fliter
movie_people = ['sb_alex', 'sb_wupeiqi', 'hello'] def filter_test(array): ret = [] for p in array: i ...
- [No000014C]让大脑高效运转的24个技巧
内容来译自David Rock “Your Brain at Work” and Nir Eyal, NirAndFar.com. Nir Eyal 是<上瘾>这本书的作者. 如何抓住转瞬 ...
- [No0000E2]Vmware虚拟机安装 苹果系统 mac OS 10.12
1.下载并安装Vmware:实验版本号:VMware-workstation-full-12.5.5-5234757:(忽略网上说的这个版本不行.可以装C盘,不过转C盘后后面都要用管理员权限运行其他软 ...
- ASP.NET MVC 母版页
为什么使用母版页?为了整个站点样式统一,任何WEB应用程序都应该使用母版页.MVC框架中,有新的方式为母版页传递数据. 一个WEB应用程序可以包含多个母版页,母版页用于定义页面布局,它与普 ...
- Xml文件删除节点总是留有空标签
---恢复内容开始--- 在删除Xml文件时,删除成功后还有标签,让我百思不得其解,因为xml文档中留着这空标签会对后续的操作带来很多麻烦,会取出空值,人后导致程序中止. 导致这种情况的原因是删除xm ...
- php之print_r
stdClass类是PHP的一个内部保留类,初始时没有成员变量也没有成员方法,所有的魔术方法都被 设置为null,可以使用其传递变量参数,但是没有可以调用的方法.stdClass类可以被继承. 只是这 ...
- Signing for "XXXX" requires a development team.
[iOS]Signing for requires a development team. Select a development team in the project editor. Code ...