Hadoop 2.7.3 完全分布式维护-动态增加datanode篇
原有环境
http://www.cnblogs.com/ilifeilong/p/7406944.html
| IP | host | JDK | linux | hadop | role |
| 172.16.101.55 | sht-sgmhadoopnn-01 | 1.8.0_111 | CentOS release 6.5 | hadoop-2.7.3 | NameNode,SecondaryNameNode,ResourceManager |
| 172.16.101.58 | sht-sgmhadoopdn-01 | 1.8.0_111 | CentOS release 6.5 | hadoop-2.7.3 | DataNode,NodeManager |
| 172.16.101.59 | sht-sgmhadoopdn-02 | 1.8.0_111 | CentOS release 6.5 | hadoop-2.7.3 | DataNode,NodeManager |
| 172.16.101.60 | sht-sgmhadoopdn-03 | 1.8.0_111 | CentOS release 6.5 | hadoop-2.7.3 | DataNode,NodeManager |
| 172.16.101.66 | sht-sgmhadoopdn-04 | 1.8.0_111 | CentOS release 6.5 | hadoop-2.7.3 | DataNode,NodeManager |
现计划向集群新增一台datanode,如表格所示
1. 配置系统环境
主机名,ssh互信,环境变量等
2. 修改namenode节点的slave文件,增加新节点信息
$ cat slaves
sht-sgmhadoopdn-
sht-sgmhadoopdn-
sht-sgmhadoopdn-
sht-sgmhadoopdn-
3. 在namenode节点上,将hadoop-2.7.3复制到新节点上,并在新节点上删除data和logs目录中的文件
$ hostname
sht-sgmhadoopnn-
$ rsync -az --progress /usr/local/hadoop-2.7./* hduser@sht-sgmhadoopdn-04:/usr/local/hadoop-2.7.3/ $ hostname
sht-sgmhadoopdn-04
$ rm -rf /usr/local/hadoop-2.7.3/logs/*
$ rm -rf /usr/local/hadoop-2.7.3/data/*
4. 启动新datanode的datanode进程
$ hadoop-daemon.sh start datanode
starting datanode, logging to /usr/local/hadoop-2.7./logs/hadoop-hduser-datanode-sht-sgmhadoopdn-.out
$ jps
Jps
DataNode
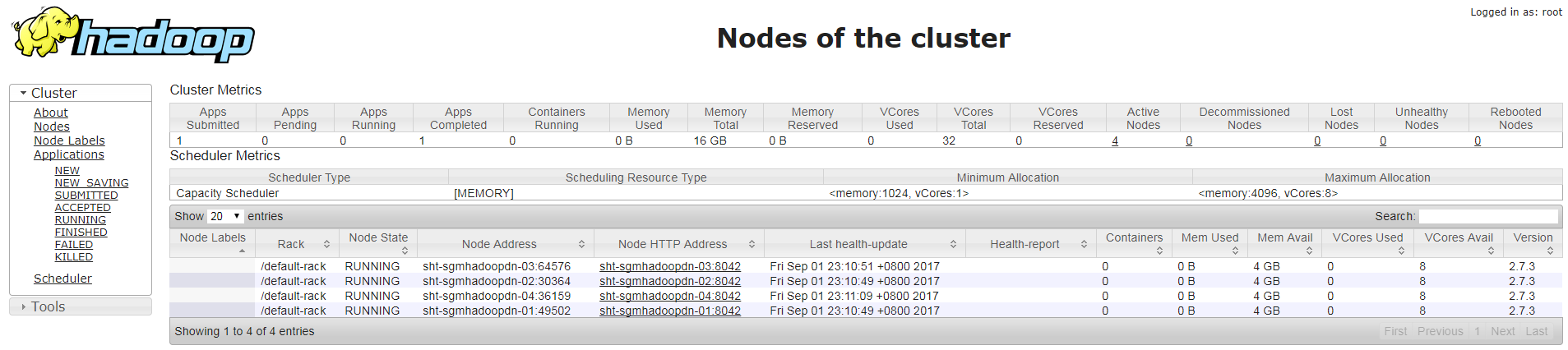
5. 在namenode查看当前集群情况,确认信节点已经正常加入
5.1 以命令行方式
$ hdfs dfsadmin -report
Configured Capacity: (282.49 GB)
Present Capacity: (77.98 GB)
DFS Remaining: (77.38 GB)
DFS Used: (618.02 MB)
DFS Used%: 0.77%
Under replicated blocks:
Blocks with corrupt replicas:
Missing blocks:
Missing blocks (with replication factor ): -------------------------------------------------
Live datanodes (): Name: 172.16.101.66: (sht-sgmhadoopdn-)
Hostname: sht-sgmhadoopdn-
Decommission Status : Normal
Configured Capacity: (70.62 GB)
DFS Used: ( KB)
Non DFS Used: (33.13 GB)
DFS Remaining: (37.49 GB)
DFS Used%: 0.00%
DFS Remaining%: 53.09%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Fri Sep :: CST Name: 172.16.101.60: (sht-sgmhadoopdn-)
Hostname: sht-sgmhadoopdn-
Decommission Status : Normal
Configured Capacity: (70.62 GB)
DFS Used: ( MB)
Non DFS Used: (57.48 GB)
DFS Remaining: (12.95 GB)
DFS Used%: 0.28%
DFS Remaining%: 18.33%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Fri Sep :: CST Name: 172.16.101.59: (sht-sgmhadoopdn-)
Hostname: sht-sgmhadoopdn-
Decommission Status : Normal
Configured Capacity: (70.62 GB)
DFS Used: ( MB)
Non DFS Used: (57.80 GB)
DFS Remaining: (12.63 GB)
DFS Used%: 0.28%
DFS Remaining%: 17.88%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Fri Sep :: CST Name: 172.16.101.58: (sht-sgmhadoopdn-)
Hostname: sht-sgmhadoopdn-
Decommission Status : Normal
Configured Capacity: (70.62 GB)
DFS Used: ( MB)
Non DFS Used: (56.11 GB)
DFS Remaining: (14.31 GB)
DFS Used%: 0.28%
DFS Remaining%: 20.26%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Fri Sep :: CST
5.2 以web方式

6. 在namenoe上设置 hdfs 的负载均衡
$ hdfs dfsadmin -setBalancerBandwidth
Balancer bandwidth is set to
$ start-balancer.sh -threshold
starting balancer, logging to /usr/local/hadoop-2.7./logs/hadoop-hduser-balancer-sht-sgmhadoopnn-.out
7. 查看hdfs负载信息(有时候节点数据量较小,看出来数据量变化,可以上传大文件测试)

8. 启动新节点的nodemanager进程
$ yarn-daemon.sh start nodemanager
starting nodemanager, logging to /usr/local/hadoop-2.7./logs/yarn-hduser-nodemanager-sht-sgmhadoopdn-.out
$ jps
NodeManager
Jps
DataNode
Hadoop 2.7.3 完全分布式维护-动态增加datanode篇的更多相关文章
- Hadoop 2.7.3 完全分布式维护-简单测试篇
1. 测试MapReduce Job 1.1 上传文件到hdfs文件系统 $ jps Jps SecondaryNameNode JobHistoryServer NameNode ResourceM ...
- Hadoop 2.7.3 完全分布式维护-部署篇
测试环境如下 IP host JDK linux hadop role 172.16.101.55 sht-sgmhadoopnn-01 1.8.0_111 CentOS release ...
- Hadoop 2.6.3动态增加/删除DataNode节点
假设集群操作系统均为:CentOS 6.7 x64 Hadoop版本为:2.6.3 一.动态增加DataNode 1.准备新的DataNode节点机器,配置SSH互信,可以直接复制已有DataNode ...
- 安装部署Apache Hadoop (本地模式和伪分布式)
本节内容: Hadoop版本 安装部署Hadoop 一.Hadoop版本 1. Hadoop版本种类 目前Hadoop发行版非常多,有华为发行版.Intel发行版.Cloudera发行版(CDH)等, ...
- Hadoop、Zookeeper、Hbase分布式安装教程
参考: Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0 Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS ZooKeeper-3.3 ...
- Hadoop 在windows 上伪分布式的安装过程
第一部分:Hadoop 在windows 上伪分布式的安装过程 安装JDK 1.下载JDK http://www.oracle.com/technetwork/java/javaee/d ...
- centos中-hadoop单机安装及伪分布式运行实例
创建用户并加入授权 1,创建hadoop用户 sudo useradd -m hadoop -s /bin/bash 2,修改sudo的配置文件,位于/etc/sudoers,需要root权限才可以读 ...
- Apache Hadoop 2.9.2 完全分布式部署
Apache Hadoop 2.9.2 完全分布式部署(HDFS) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.环境准备 1>.操作平台 [root@node101.y ...
- centos6.8系统安装 Hadoop 2.7.3伪分布式集群
安装 Hadoop 2.7.3 配置ssh免密码登陆 cd ~/.ssh # 若没有该目录,请先执行一次ssh localhost ssh-keygen - ...
随机推荐
- npm介绍和使用
# npm 介绍 > 概念 : node 包管理工具 > 作用 : 通过 npm 来快速下载/安装项目中依赖的包 > 查看 版本号 : npm -v # npm 基本使用演示 ...
- 一.移动app测试与质量保证
1.典型的互联网产品的研发流程,及其核心做法.这里并不是简单的套用敏捷等流程方法,而是经过时间摸索和不断调整,找到最适合自己产品的流程做法,这是质量实践质量保证的基础. 2.系统功能测试实践.包涵需求 ...
- C# 委托例子
两个子窗口向一个主窗口发送信息 主窗口: using System; using System.Collections.Generic; using System.ComponentModel; us ...
- Appium典型问题处理
1. http://ask.testfan.cn/article/902 Appium 服务端安装-windows2. http://ask.testfan.cn/article/1078 最新版本a ...
- 【Python】【有趣的模块】【requests】【二】快速上手
[一]参数及结果 [二]响应内容 >>> r = requests.get('https://github.com/timeline.json') >>> prin ...
- 关于python的基础知识
一,编程语言的类型: 1.编译型 2.解释型 3.静态语言 4.动态语言 5.强类型定义语言 6.弱类型定义语言 编译型vs解释型 编译型: 优点:编译器一般会有预编译的过程对代码进行优化.因为编译只 ...
- SpringBoot学习路线
网上也有很多github资源,都是自己学习Spring Boot时候,自己练的代码 虽然现在最新的版本用2.1.3.RELEASE版本,以前版本的demo运行可能会遇到错误.但是有总比没有要好,不是么 ...
- Thymeleaf的基本语法总结
最近用Spring boot开发一些测试平台和工具,用到页面展示的部分, 选择的是thymeleaf模版引擎. 页面开发的7788快结束了,下面来总结下此过程中对thymeleaf的使用总结. 什么是 ...
- “ORA-06550: 第 1 行, 第 7 列”解决方法
将本机能正常运行的维修生产日志代码发布到公司内测环境里无法正常运行,报错如下: execute() - pls–QuartzJob.java–quartzjob 开始执行! java.sql.SQLE ...
- [原][osg]osgconv浅析
查看osgconv.cpp main函数在533行 osg::ArgumentParser arguments(&argc,argv); //........一堆功能不管,先看一下文件读写 F ...