彪悍开源的分析数据库-ClickHouse
https://zhuanlan.zhihu.com/p/22165241
今天介绍一个来自俄罗斯的凶猛彪悍的分析数据库:ClickHouse,它是今年6月开源,俄语社区为主,好酒不怕巷子深。
本文内容较长,分为三个部分:走马观花,死而后生,遥指杏花村;第一章,走马观花,初步了解一下基本特性;第二章,死而后生,介绍ClickHouse的技术架构演化的今生前世;第三章,遥指杏花村,介绍一些参考资料,包括一些俄文资料。
第一章,走马观花
俄罗斯的‘百度’叫做Yandex,覆盖了俄语搜索超过68%的市场,有俄语的地方就有Yandex;有中文的地方,就有百度么?好像不一定 :) 。
Yandex在2016年6月15日开源了一个数据分析的数据库,名字叫做ClickHouse,这对保守俄罗斯人来说是个特大事。更让人惊讶的是,这个列式存储数据库的跑分要超过很多流行的商业MPP数据库软件,例如Vertica。如果你没有听过Vertica,那你一定听过 Michael Stonebraker,2014年图灵奖的获得者,PostgreSQL和Ingres发明者(Sybase和SQL Server都是继承 Ingres而来的), Paradigm4和SciDB的创办者。Michael Stonebraker于2005年创办Vertica公司,后来该公司被HP收购,HP Vertica成为MPP列式存储商业数据库的高性能代表,Facebook就购买了Vertica数据用于用户行为分析。
简单的说,ClickHouse作为分析型数据库,有三大特点:一是跑分快, 二是功能多 ,三是文艺范
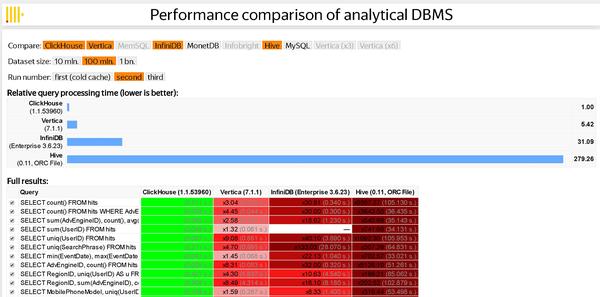
1. 跑分快: ClickHouse跑分是Vertica的5倍快:
ClickHouse性能超过了市面上大部分的列式存储数据库,相比传统的数据ClickHouse要快100-1000X,ClickHouse还是有非常大的优势:
100Million 数据集:
ClickHouse比Vertica约快5倍,比Hive快279倍,比My SQL快801倍
1Billion 数据集:
ClickHouse比Vertica约快5倍,MySQL和Hive已经无法完成任务了
2. 功能多:ClickHouse支持数据统计分析各种场景
- 支持类SQL查询,
- 支持繁多库函数(例如IP转化,URL分析等,预估计算/HyperLoglog等)
- 支持数组(Array)和嵌套数据结构(Nested Data Structure)
- 支持数据库异地复制部署
3.文艺范:目前ClickHouse的限制很多,生来就是为小资服务的
- 目前只支持Ubuntu系统
- 不提供设计和架构文档,设计很神秘的样子,只有开源的C++源码
- 不理睬Hadoop生态,走自己的路
谁在用ClickHouse?
由于项目今年6月才开源,因此外部商业应用并不多件,但是开发社区的讨论还是保持热度(主要用俄语)
Yandex有十几个项目在用使用ClickHouse,它们包括:Yandex数据分析,电子邮件,广告数据分析,用户行为分析等等
2012年,欧洲核子研究中心使用ClickHouse保存粒子对撞机产生的大量实验数据,每年的数据存储量都是PB级别,并支持统计分析查询
ClickHouse最大应用:
最大的应用来自于Yandex的统计分析服务Yandex.Metrica,类似于谷歌Analytics(GA),或友盟统计,小米统计,帮助网站或移动应用进行数据分析和精细化运营工具,据称Yandex.Metrica为世界上第二大的网站分析平台。ClickHouse在这个应用中,部署了近四百台机器,每天支持200亿的事件和历史总记录超过13万亿条记录,这些记录都存有原始数据(非聚合数据),随时可以使用SQL查询和分析,生成用户报告。
ClickHouse就是快:比Veritca快约5倍
下面是100M数据集的跑分结果:ClickHouse 比Vertia快约5倍,比Hive快279倍,比My SQL 快801倍;虽然对不同的SQL查询,结果不完全一样,但是基本趋势是一致的。ClickHouse跑分有多块? 举个例子:ClickHouse 1秒,Vertica 5.42秒,Hive 279秒;
ClickHouse是什么,适合什么场景?
到底什么是ClickHouse数据库,场景应用是什么,参考下面说明:

ClickHouse的不完美:
不支持Transaction:想快就别想Transaction
聚合结果必须小于一台机器的内存大小:不是大问题
缺少完整的Update/Delete操作
支持有限操作系统
开源社区刚刚启动,主要是俄语为主
ClickHouse和一些技术的比较
1.商业OLAP数据库
例如:HP Vertica, Actian the Vector,
区别:ClickHouse是开源而且免费的
2.云解决方案
例如:亚马逊RedShift和谷歌的BigQuery
区别:ClickHouse可以使用自己机器部署,无需为云付费
3.Hadoop生态软件
例如:Cloudera Impala, Spark SQL, Facebook Presto , Apache Drill
区别:
-ClickHouse支持实时的高并发系统
-ClckHouse不依赖于Hadoop生态软件和基础
-ClickHouse支持分布式机房的部署
4.开源OLAP数据库
例如:InfiniDB, MonetDB, LucidDB
区别:这些项目的应用的规模较小,并没有应用在大型的互联网服务当中,相比之下,ClickHouse的成熟度和稳定性远远超过这些软件。
5.开源分析,非关系型数据库
例如:Druid , Apache Kylin
区别:ClickHouse可以支持从原始数据的直接查询,ClickHouse支持类SQL语言,提供了传统关系型数据的便利。
第二章,死而后生
ClickHouse设计之初就是为Yandex.Metrika而生,先一起看看Yandex.Metrika数据分析系统的演化过程吧,ClickHouse是第四代的解决方案,经过三次死亡后的产物,涅槃重生的巨兽!
第一阶段:MyISAM (LSM-Tree) (2008-2011)
Yandex.Metrika产品成立于2008年,最开始使用了MyISAM作为存储引擎。熟悉MySQL的同学都知道,这是MySQL的重要存储引擎之一(另外一个是InnoDB)。MyISAM中的实现也是使用LSM-Tree的设计,基本思路就是将对数据的更改hold在内存中,达到指定的threadhold后将该批更改批量写入到磁盘,在批量写入的过程中跟已经存在的数据做rolling merge。
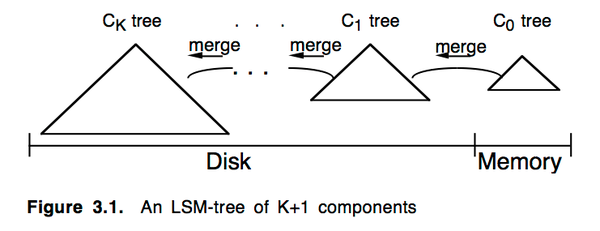
使用MyISAM的方法,刚开始数据量不大,访问请求也不大的时候,这个方法非常有效,特别是对于一些固定的报告生成,效率非常高,系统能够保持很好的系统写能力。
数据格式也是传统的索引结构:一个数据文件+一个索引结构; 索引结构是一个B-Tree结构,叶子节点保持着数据文件的OffSet; 通过Index文件找到数据范围,然后进行数据文件读取;早期的实现是将Index文件装在内存中,数据文件在磁盘当中,或则SSD等。当时7200RPM的硬盘,每秒进行100-200次随机读;SSD硬盘可以支持30000次随机读/每秒。
除了考察MyISAM之外,InnoDB也被考察过。MyISAM的索引和数据是分开的,并且索引是有压缩的,这种方式可以提高内存的使用率。加载更多索引到内存中,而Innodb是索引和数据是紧密捆绑的,没有使用压缩的情况下,InnoDb的大小会比MyISAM体积大很多。当然,InnoDB支持的Transaction也是非常诱人的。

阶段二: Metrage (从2010-现在)
为了解决MyISAM的一些问题,Yandex决定开发Metrage,核心想法来源于统计分析数据的一些特点,统计分析数据的每行数据量都不大,因此可以将多行数据聚合在一起作为处理单位,加快操作速度和系统的吞吐能力。
它有几个特点:
数据通过小批量Batch存储
支持高强度的写操作(数千行写入/每秒)
读数据量非常小
读数据操作中Primary Key 的数量有限(<1百万)
每一行的数据量很小
整个结构类似于MyISAM的索引,但是数据块中也聚合了一些小粒度的数据,索引放在内存中,数据被整理成块放在磁盘中,并且进行压缩。
该数据结构的优点:
- 数据被压缩成块。 由于存储有序,压缩足够强大,其中使用了快速压缩算法(在2010年使用QuickLZ ,自2011年使用LZ4 )。
- 采用稀疏索引: 稀疏索引 - 主键值排序后放置于若干个组中,可以节省大量索引空间。 这个索引始终放在内存中。
Metrage在数据量最大的时候,39*2台服务器中存储了大约3万亿行数据,每天机器处理大约为1千亿的数据。
这个系统有个缺点,数据查询只能进行基于固定的查询模式(否则性能将受到很大影响),因此在设计数据Schema的时候,需要考虑数据查询的性能问题,缺少足够的灵活型。因此这个项目使用了5年后,统计分析的数据都开始迁移到其他的平台系统中了(那时候LevelDB,还没有出现,否则可以使用LevelDB作为Mertage的核心模块)。
阶段三 OLAPServer (2009-2013)
随着Yandex.Metrike的数据量越来越大,数据查询的速度越来越慢,查询相应事件长,系统的CPU和IO资源占用大,因此公司内部尝试了不同的解决方案,其中一个原型方案是OLAPServer。 设计思路就是根据“星型结构”设计一些维度和事实列,通过预先部分聚合数据加快访问的速度,这一套技术用于支持各种报告的生成。
基本的场景如下:
支持一个Fact表,包括维度列(Dimension)和指标列(Metrics),维度有上百个
读取大量行的数据,但是一次查询往往只关注某些列
写多读少的场景,报表查询请求量并不大
大部分简单查询不超过50毫秒响应时间
列的值数据量非常小,通常为整数或者不超过60字节的URL
它需要高带宽,同时处理单个请求(高达十亿每秒的行的单个服务器上)
查询结果的数据量非常小,通常是数据聚合的结果
无需支持事务,数据更新极少,通知只有添加操作
这些场景下,使用列式数据库是非常有效的,从两个方面可以理解
1. 磁盘I/O的优化
- 作为列式存储,查询只需要访问所关心的列数据
- 列数据放在一起,数据格式类似,非常容易压缩,因此减少I/O数据量
- 输入输出的减少,内存可以腾出更多地方作为Cache
2. CPU
由于数量行数特别大,数据的解压缩和计算将耗费非常多的CPU资源,为了提高CPU的效率,行业中通常是将数据转换成Vector的计算。例如行业比较流行的VectorWise方法。
下面是VectorWise的高层架构示意图,其基本想法就是将压缩的列数据整理成现代CPU容易处理的Vector模式,利用现代CPU的多线程,SIMD(Single Instruction,Multiple Data),每次处理都是一批Vector数据,极大的提高了处理效率。
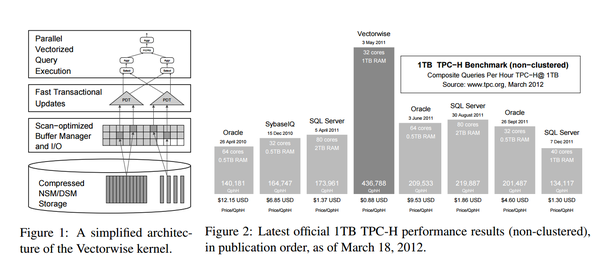
市场有非常多的的列式分析型数据库,例如HP Vertica, ParAccel Actian the Matrix, Google PowerDrill , Amazon的RedShift , MetaMarkets Druid等等,这些产品有很多不同的优化实践,有些是专于数据压缩,有些是专于数据聚合,有些是专于扩展性等。
OLAPServer在具体实现过程中,实际上采用的是比较保守的方法,实现的功能也比较有限,但是完全满足当时分析报表的支持。例如,OLAPServer数据类型只支持1-8字节的数据类型,查询只支持固定的模式:
Select keys ,aggregate(columns) from table where condition1 and condition2 .... Group bykeys order by columns 。
尽管功能有限,OLAPServer还是满足了当时的分析报表功能,并且性能非常出色。由于设计之处的限制比较多,因此后期的改进过程中成本非常高,例如为了增加更长URL的数据类型,系统改动非常大。在2013年,OLAPServer存储了7280亿行数据,目前这些数据都迁移到ClickHouse了。
第四阶段 ClickHouse(2011-现在)
使用OLAPServer,我们能够可以实时看到一些预先聚合的数据,但是对于一些聚合前的详细数据是无法查询的,随着业务的深入发展,精细化运营对于统计服务提出了更高的要求,后期有大量需求是关于直接查询聚合前的数据。
总体来说,虽然数据聚合带来一些好处,但是也存在以下一些问题。
对于基数大的列,聚合的意义不大,例如URL等
过多的维度组合会导致组合爆炸
用户常常只关心聚合后的数据中的非常一一小部分数据,因此大量聚合预计算是得不偿失的。
聚合后的数据,数据修改会非常困难,很难保证存储的逻辑完整性
如果不预先聚合数据,如何保证响应时间是一个大挑战。这意味着,数据库需要支持秒级处理数十亿的行。
近年来,市面上也出现很多列式存储的开源DBMS,包括Cloudera Impala, Spark SQL, Presto, Apache Drill,这些系统虽然都能完成查询的功能,但是速度却无法满足数据统计分析的需求,即使聚合后的性能能够满足,但也缺少灵活度。
因此,Yandex开发了自己的列式分析数据库 ClickHouse,初期主要是满足Yandex.Metrike的统计分析需求,主角要上场了。
ClickHouse实际上来源于内部的几个项目的整合,项目起源起源于2011年左,
到2013年的时候,ClickHouse的性能就和Vertica大致相同;2015年12月,ClickHouse的数量已经达到11万亿行,数据表有200多列,主集群的服务器数量也从初期的60台到394台;
整个系统的部署是支持水平扩展的,并且支持多机房部署和备份。虽然它是能够在大型集群操作,它可以被安装在同一服务器上,甚至在虚拟机上。
在最新的性能评测中,ClickHouse比Vertica快约5倍。现在Yandex公司内部有十几个应用系统在使用ClickHouse,场景包括数据存储,查询分析,报表制作等。
ClickHouse的蓝图
关于ClickHouse的下一步发展,公司并没有给出太多规划,因为多数信息还是属于不公开状态,但是从一些公开的信息,我们可以了解到,ClickHouse会向两个方向发展。
1 云计算数据库:
Yandex希望通过ClickHouse促进公司云计算数据库的发展,包括用户可以通过云服务的方式,使用ClickHouse,开源是走向市场的第一步。
2. 加强SQL兼容性。
为了支持更多的企业用户,目前的查询虽然采用非常近似的SQL语言,但是还有很多地方需要改进,包括和一些商业软件(例如Tableau,Pentaho)的集成无缝使用。
第三部分:遥指杏花村
这一部分包括了一些ClickHouse的一些基本信息,帮助大家进入ClickHouse的世界。为了深度了解ClickHouse社区,不仅仅需要FQ,也需要谷歌或者必应的翻译器,俄文翻译的效果不错。
1主页: https://clickhouse.yandex
2.代码: GitHub - yandex/ClickHouse: ClickHouse is a free analytic DBMS for big data.
3参考文章:
Yandex.Metrike的架构演化:
Эволюция структур данных в Яндекс.Метрике / Блог компании Яндекс / Хабрахабр(俄文)很棒的文章
MPP数据库基础架构:
http://vldb.org/pvldb/vol5/p1790_andrewlamb_vldb2012.pdf
http://www.cs.yale.edu/homes/dna/talks/Column_Store_Tutorial_VLDB09.pdf
4关于Yandex的
Yandex的(纳斯达克股票代码:YNDX)是互联网公司在俄罗斯主导,经营该国最流行的搜索引擎和访问量最大的网站。Yandex的还经营在乌克兰,哈萨克斯坦,白俄罗斯和土耳其。Yandex的的使命是回答任何互联网用户的任何问题(Answer any question Internet users may have)。
最近在学习一些ClickHouse的源代码,还没有理清楚头绪,下次搞清楚逻辑后再和大家介绍一下,这里先纸上谈兵,点到为止了。
---------------------完------------------------------
彪悍开源的分析数据库-ClickHouse的更多相关文章
- 俄罗斯最新开源的牛掰数据库ClickHouse
ClickHouse是俄罗斯最近刚刚开源的用于数据库管理系统能够实时生成分析数据报告,性能非常强悍! 使用SQL查询. 他拥有切割你的数据更多的新方法 ClickHouse的性能超过同类市场上目前用于 ...
- [转载]12款免费与开源的NoSQL数据库介绍
Naresh Kumar是位软件工程师与热情的博主,对于编程与新事物拥有极大的兴趣,非常乐于与其他开发者和程序员分享技术上的研究成果.近日,Naresh撰文谈到了12款知名的免费.开源NoSQL数据库 ...
- RocksDB介绍:一个比LevelDB更彪悍的引擎
关于LevelDB的资料网上还是比较丰富的,如果你尚未听说过LevelDB,那请稍微预习一下,因为RocksDB实际上是在LevelDB之上做的改进.本文主要侧重在架构上对RocksDB对LevelD ...
- 12款免费与开源的NoSQL数据库
Naresh Kumar是位软件工程师与热情的博主,对于编程与新事物拥有极大的兴趣,非常乐于与其他开发者和程序员分享技术上的研究成果.近日,Naresh撰文谈到了12款知名的免费.开源NoSQL数据库 ...
- HubbleDotNet开源全文搜索数据库项目--技术详解
HubbleDotNet 简介 HubbleDotNet 和 Lucene.net 性能对比测试 HubbleDotNet 和 Lucene.Net 匹配相关度的比较 HubbleDotNet 软件架 ...
- 开源代码分析之Android/iOS Hybrid JSBridge框架
Hybrid开发是现在的主流形式,对于业务快速迭代的公司尤其重要.曾将在鞋厂接触了很多关于Hybrid的理念,在这里分享一些Hybrid框架思想. Hybrid框架包括Native与H5的通信,Web ...
- Java数据库——使用元数据分析数据库
在JDBC中提供了DatabaseMetaData和ResultSetMetaData接口来分析数据库的元数据. DatabaseMetaData 使用DatabaseMetaData取得数据库的元信 ...
- SSDB是一个开源的高性能数据库服务器
SSDB是一个开源的高性能数据库服务器, 使用Google LevelDB作为存储引擎, 支持T级别的数据, 同时支持类似Redis中的zset和hash等数据结构, 在同时需求高性能和大数据的条件下 ...
- 列式数据库~clickhouse 场景以及安装
一 简介:列式数据库clickhouse的安装与基本操作二 基本介绍:ClickHouse来自俄罗斯,是一款列式数据库三 适用场景: 简单类型的大数据统计四 限制 1 不支持更新操作,不支持事 ...
随机推荐
- Android初级教程理论知识(第二章布局&读写文件)
常见布局 相对布局 RelativeLayout 组件默认左对齐.顶部对齐 设置组件在指定组件的右边 android:layout_toRightOf="@id/tv1" 设置在指 ...
- Linux 共享内存 详解
一.什么是共享内存区 共享内存区是最快的可用IPC形式.它允许多个不相关的进程去访问同一部分逻辑内存.如果需要在两个运行中的进程之间传输数据,共享内存将是一种效率极高的解决方案.一旦这样的内存区映射到 ...
- Leetcode_9_Palindrome Number
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/41598031 Palindrome Number Dete ...
- unity 实现流光效果
1.通过一些简单效果可以让我们更好的去理解shader,具体都在代码注释中: Shader "Unlit/MoveLightImage" { Properties { //主纹理 ...
- 使用spine骨骼动画制作的libgdx游戏
(官网:www.libgdx.cn) Super Spineboy是一个使用Spine和libgdx开发的跨平台游戏(Windows,Mac,Linux),Spine是一个2D游戏动画工具.Super ...
- Oracle中job的实例
一.Oracle定时器(Job)各时间段写法汇总 对于DBA来说,数据库Job再熟悉不过了,因为经常要数据库定时的自动执行一些脚本,或做数据库备份,或做数据的提炼,或做数据库的性能优化,包括重建索引等 ...
- (NO.00001)iOS游戏SpeedBoy Lite成形记(十一)
之前的10篇内容主要实现了选手从起点移动至终点的动作,比较随机的模拟了选手的速度变化,另外完成了选手到达终点时该做的事情. 接下来的几篇中我们进一步完善SpeedBoy Lite项目,使它真正成为一个 ...
- Leetcode_165_Compare Version Numbers
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/42342251 Compare two version nu ...
- 开源图像检索工具:Caliph&Emir使用方法
Caliph&Emir是基于MPEG7的软件.它是用Java编写的开源软件.采用了lucene完成索引和检索功能.是研究MPEG7标准,图像检索等等方面不可多得的好工具. 在此介绍一下它们的基 ...
- -lt -gt -ge -le -eq的意义
脚本如下:#!/bin/bashx=0while [ $x -lt 10 ]doecho $xx=`echo "$x+1" | bc`done 请问这里的-lt是什么意思,请大家指 ...