Mahout 系列之----共轭梯度
无预处理共轭梯度
要求解线性方程组 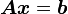 ,稳定双共轭梯度法从初始解
,稳定双共轭梯度法从初始解
 开始按以下步骤迭代:
开始按以下步骤迭代:

- 任意选择向量
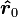 使得
使得
 ,例如,
,例如,

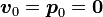
- 对
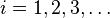



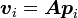





- 若
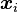 足够精确则退出
足够精确则退出 
预处理共轭梯度
预处理通常被用来加速迭代方法的收敛。要使用预处理子  来求解线性方程组
来求解线性方程组
,预处理稳定双共轭梯度法从初始解
开始按以下步骤迭代:
- 任意选择向量 使得
,例如, - 对
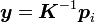
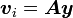


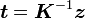

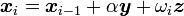
- 若 足够精确则退出
这个形式等价于将无预处理的稳定双共轭梯度法应用于显式预处理后的方程组
 ,
,
其中 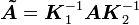 ,
,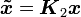 ,
,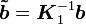 。换句话说,左预处理和右预处理都可以通过这个形式实施。
。换句话说,左预处理和右预处理都可以通过这个形式实施。
Mahout 分布式共轭梯度实现:
package org.apache.mahout.math.solver;
import org.apache.mahout.math.CardinalityException;
import org.apache.mahout.math.DenseVector;
import org.apache.mahout.math.Vector;
import org.apache.mahout.math.VectorIterable;
import org.apache.mahout.math.function.Functions;
import org.apache.mahout.math.function.PlusMult;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* <p>Implementation of a conjugate gradient iterative solver for linear systems. Implements both
* standard conjugate gradient and pre-conditioned conjugate gradient.
*
* <p>Conjugate gradient requires the matrix A in the linear system Ax = b to be symmetric and positive
* definite. For convenience, this implementation allows the input matrix to be be non-symmetric, in
* which case the system A'Ax = b is solved. Because this requires only one pass through the matrix A, it
* is faster than explictly computing A'A, then passing the results to the solver.
*
* <p>For inputs that may be ill conditioned (often the case for highly sparse input), this solver
* also accepts a parameter, lambda, which adds a scaled identity to the matrix A, solving the system
* (A + lambda*I)x = b. This obviously changes the solution, but it will guarantee solvability. The
* ridge regression approach to linear regression is a common use of this feature.
*
* <p>If only an approximate solution is required, the maximum number of iterations or the error threshold
* may be specified to end the algorithm early at the expense of accuracy. When the matrix A is ill conditioned,
* it may sometimes be necessary to increase the maximum number of iterations above the default of A.numCols()
* due to numerical issues.
*
* <p>By default the solver will run a.numCols() iterations or until the residual falls below 1E-9.
*
* <p>For more information on the conjugate gradient algorithm, see Golub & van Loan, "Matrix Computations",
* sections 10.2 and 10.3 or the <a href="http://en.wikipedia.org/wiki/Conjugate_gradient">conjugate gradient
* wikipedia article</a>.
*/
public class ConjugateGradientSolver {
public static final double DEFAULT_MAX_ERROR = 1.0e-9;
private static final Logger log = LoggerFactory.getLogger(ConjugateGradientSolver.class);
private static final PlusMult PLUS_MULT = new PlusMult(1.0);
private int iterations;
private double residualNormSquared;
public ConjugateGradientSolver() {
this.iterations = 0;
this.residualNormSquared = Double.NaN;
}
/**
* Solves the system Ax = b with default termination criteria. A must be symmetric, square, and positive definite.
* Only the squareness of a is checked, since testing for symmetry and positive definiteness are too expensive. If
* an invalid matrix is specified, then the algorithm may not yield a valid result.
*
* @param a The linear operator A.
* @param b The vector b.
* @return The result x of solving the system.
* @throws IllegalArgumentException if a is not square or if the size of b is not equal to the number of columns of a.
*
*/
public Vector solve(VectorIterable a, Vector b) {
return solve(a, b, null, b.size(), DEFAULT_MAX_ERROR);
}
/**
* Solves the system Ax = b with default termination criteria using the specified preconditioner. A must be
* symmetric, square, and positive definite. Only the squareness of a is checked, since testing for symmetry
* and positive definiteness are too expensive. If an invalid matrix is specified, then the algorithm may not
* yield a valid result.
*
* @param a The linear operator A.
* @param b The vector b.
* @param precond A preconditioner to use on A during the solution process.
* @return The result x of solving the system.
* @throws IllegalArgumentException if a is not square or if the size of b is not equal to the number of columns of a.
*
*/
public Vector solve(VectorIterable a, Vector b, Preconditioner precond) {
return solve(a, b, precond, b.size(), DEFAULT_MAX_ERROR);
}
/**
* Solves the system Ax = b, where A is a linear operator and b is a vector. Uses the specified preconditioner
* to improve numeric stability and possibly speed convergence. This version of solve() allows control over the
* termination and iteration parameters.
*
* @param a The matrix A.
* @param b The vector b.
* @param preconditioner The preconditioner to apply.
* @param maxIterations The maximum number of iterations to run.
* @param maxError The maximum amount of residual error to tolerate. The algorithm will run until the residual falls
* below this value or until maxIterations are completed.
* @return The result x of solving the system.
* @throws IllegalArgumentException if the matrix is not square, if the size of b is not equal to the number of
* columns of A, if maxError is less than zero, or if maxIterations is not positive.
*/
// 共轭梯度实现的主题部分。很明显该方法是既可以用预处理的方式,也可以不用预处理的方式。Mahout中提供了单机模式的雅克比预处理,但是没有提供分布式处理的雅克比预处理,这个需要自己写。很简单,只要将对角线元素去倒数,组成一个对角阵即可。
public Vector solve(VectorIterable a,
Vector b,
Preconditioner preconditioner,
int maxIterations,
double maxError) {
if (a.numRows() != a.numCols()) {
throw new IllegalArgumentException("Matrix must be square, symmetric and positive definite.");
}
if (a.numCols() != b.size()) {
throw new CardinalityException(a.numCols(), b.size());
}
if (maxIterations <= 0) {
throw new IllegalArgumentException("Max iterations must be positive.");
}
if (maxError < 0.0) {
throw new IllegalArgumentException("Max error must be non-negative.");
}
Vector x = new DenseVector(b.size());
iterations = 0;
Vector residual = b.minus(a.times(x));
residualNormSquared = residual.dot(residual);
log.info("Conjugate gradient initial residual norm = {}", Math.sqrt(residualNormSquared));
double previousConditionedNormSqr = 0.0;
Vector updateDirection = null;
while (Math.sqrt(residualNormSquared) > maxError && iterations < maxIterations) {
Vector conditionedResidual;
double conditionedNormSqr;
if (preconditioner == null) {
conditionedResidual = residual;
conditionedNormSqr = residualNormSquared;
} else {
conditionedResidual = preconditioner.precondition(residual);
conditionedNormSqr = residual.dot(conditionedResidual);
}
++iterations;
if (iterations == 1) {
updateDirection = new DenseVector(conditionedResidual);
} else {
double beta = conditionedNormSqr / previousConditionedNormSqr;
// updateDirection = residual + beta * updateDirection
updateDirection.assign(Functions.MULT, beta);
updateDirection.assign(conditionedResidual, Functions.PLUS);
}
Vector aTimesUpdate = a.times(updateDirection);
double alpha = conditionedNormSqr / updateDirection.dot(aTimesUpdate);
// x = x + alpha * updateDirection
PLUS_MULT.setMultiplicator(alpha);
x.assign(updateDirection, PLUS_MULT);
// residual = residual - alpha * A * updateDirection
PLUS_MULT.setMultiplicator(-alpha);
residual.assign(aTimesUpdate, PLUS_MULT);
previousConditionedNormSqr = conditionedNormSqr;
residualNormSquared = residual.dot(residual);
log.info("Conjugate gradient iteration {} residual norm = {}", iterations, Math.sqrt(residualNormSquared));
}
return x;
}
/**
* Returns the number of iterations run once the solver is complete.
*
* @return The number of iterations run.
*/
public int getIterations() {
return iterations;
}
/**
* Returns the norm of the residual at the completion of the solver. Usually this should be close to zero except in
* the case of a non positive definite matrix A, which results in an unsolvable system, or for ill conditioned A, in
* which case more iterations than the default may be needed.
*
* @return The norm of the residual in the solution.
*/
public double getResidualNorm() {
return Math.sqrt(residualNormSquared);
}
}
DistributedConjugateGradientSolver 是上CG的扩展,DCG和CG的区别在于,DCG矩阵和向量相乘时需要MR实现矩阵相乘。
Mahout 系列之----共轭梯度的更多相关文章
- Mahout系列之----共轭梯度预处理
对于大型矩阵,预处理是很重要的.常用的预处理方法有: (1) 雅克比预处理 (2)块状雅克比预处理 (3)半LU 分解 (4)超松弛法
- 共轭梯度算法求最小值-scipy
# coding=utf-8 #共轭梯度算法求最小值 import numpy as np from scipy import optimize def f(x, *args): u, v = x a ...
- 机器学习: 共轭梯度算法(PCG)
今天介绍数值计算和优化方法中非常有效的一种数值解法,共轭梯度法.我们知道,在解大型线性方程组的时候,很少会有一步到位的精确解析解,一般都需要通过迭代来进行逼近,而 PCG 就是这样一种迭代逼近算法. ...
- Mahout系列之----kmeans 聚类
Kmeans是最经典的聚类算法之一,它的优美简单.快速高效被广泛使用. Kmeans算法描述 输入:簇的数目k:包含n个对象的数据集D. 输出:k个簇的集合. 方法: 从D中任意选择k个对象作为初始簇 ...
- Mahout 系列之--canopy 算法
Canopy 算法,流程简单,容易实现,一下是算法 (1)设样本集合为S,确定两个阈值t1和t2,且t1>t2. (2)任取一个样本点p属于S,作为一个Canopy,记为C,从S中移除p. (3 ...
- Mahout系列之-----相似度
Mahout推荐系统中有许多相似度实现,这些组件实现了计算不能User之间或Item之间的相似度.对于数据量以及数据类型不同的数据源,需要不同的相似度计算方法来提高推荐性能,在mahout提供了大量用 ...
- Mahout系列之----距离度量
x = (x1,...,xn) 和y = (y1,...,yn) 之间的距离为 (1)欧氏距离 EuclideanDistanceMeasure (2)曼哈顿距离 ManhattanDis ...
- mahout系列----Dirichlet 分布
Dirichlet分布可以看做是分布之上的分布.如何理解这句话,我们可以先举个例子:假设我们有一个骰子,其有六面,分别为{1,2,3,4,5,6}.现在我们做了10000次投掷的实验,得到的实验结果是 ...
- mahout系列之---谱聚类
1.构造亲和矩阵W 2.构造度矩阵D 3.拉普拉斯矩阵L 4.计算L矩阵的第二小特征值(谱)对应的特征向量Fiedler 向量 5.以Fiedler向量作为kmean聚类的初始中心,用kmeans聚类 ...
随机推荐
- 在Spring Boot中使用数据库事务
我们在前面已经分别介绍了如何在Spring Boot中使用JPA(初识在Spring Boot中使用JPA)以及如何在Spring Boot中输出REST资源(在Spring Boot中输出REST资 ...
- formData的实现
参考:https://developer.mozilla.org/zh-CN/docs/Web/API/XMLHttpRequest/Using_XMLHttpRequest <!doctype ...
- Docker Volume 之权限管理(一)
摘要: Volume数据卷是Docker的一个重要概念.数据卷是可供一个或多个容器使用的特殊目录,可以为容器应用存储提供有价值的特性.然而Docker数据卷的权限管理经常是非常令人困惑的.本文将结合实 ...
- CDH集群安装&测试总结
0.绪论 之前完全没有接触过大数据相关的东西,都是书上啊,媒体上各种吹嘘啊,我对大数据,集群啊,分布式计算等等概念真是高山仰止,充满了仰望之情,觉得这些东西是这样的: 当我搭建的过程中,发现这些东西是 ...
- Android简易实战教程--第四十七话《使用OKhttp回调方式获取网络信息》
在之前的小案例中写过一篇使用HttpUrlConnection获取网络数据的例子.在OKhttp盛行的时代,当然要学会怎么使用它,本篇就对其基本使用做一个介绍,然后再使用它的接口回调的方式获取相同的数 ...
- Hive的HQL语句及数据倾斜解决方案
[版权申明:本文系作者原创,转载请注明出处] 文章出处:http://blog.csdn.net/sdksdk0/article/details/51675005 作者: 朱培 ID ...
- 细说Http协议
什么Http协议 HTTP是HyperText Transfer Protocol(超文本传输协议)的简写,它是TCP/IP协议的一个应用层协议,用于定义WEB浏览器与WEB服务器之间交换数据的过程及 ...
- 适配器模式(adapter)
适配器模式的定义: 将一个类的接口转换成客户希望的另外一个接口,适配器模式使得原本由于接口不兼容而不能在一起的那些类可以一起工作. 主要分为三类:类的适配器模式.对象的适配器模式.接口的适配器模式. ...
- SQL语句容易出现错误的地方-连载
1.语言问题 修改语言注册表\HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432\ORACLE\KEY_DevSuitHome1中的NLS_LANG修改为AMERICAN_AMER ...
- 如何将Provisioning Profile安装到开发的Mac系统上
大熊猫猪·侯佩原创或翻译作品.欢迎转载,转载请注明出处. 如果觉得写的不好请多提意见,如果觉得不错请多多支持点赞.谢谢! hopy ;) 免责申明:本博客提供的所有翻译文章原稿均来自互联网,仅供学习交 ...