Spark RPC框架源码分析(一)简述
Spark RPC系列:
一. Spark rpc框架概述
Spark是最近几年已经算是最为成功的大数据计算框架,那么这次我们就来介绍它内部的一个小点,Spark RPC框架。
在介绍之前,我们需要先说明什么是RPC,引用百度百科:
RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。
Spark RPC可以说是Spark分布式集群的基础,若是将Spark类比为一个人的话,Spark RPC无疑就是它的血液部分。而在Spark1.6之前,它的RPC部分还是用akka实现的,但之后底层就换成了netty来实现。为什么要这样做呢?因为啊,这样将Spark和Akka耦合在了一起,如果你系统本身就有使用到Akka,然后又想使用Spark的话,那两个Akka框架版本不一致可怎么办呀,这无疑是很让人头痛的。Spark团队正是考虑到了这一点,所以将Akka替换成了netty。
这次我们就来看看Spark是如何让它的血液流动起来的吧。有一位大神将Spark RPC中的RPC部分剥离出来,弄成一个新的可运行的 RPC 项目,这个项目本身就可以当作一个简易的Akka来使用,地址在这Spark RPC。
虽然名字不一样,但这个项目的类和内容基本和Spark Core中RPC部分的代码和结构基本是一样的,这样我们就可以通过这个来学习Spark RPC框架。
PS:所用spark版本:spark2.1.0
二.Spark RPC中的 Hello world
我们程序员学东西最喜欢从一个Hello world开始,那么接下来我们就来演示如何下载并运行最简单的Hello World例子吧。
首先,我使用的编译器是IDEA,通过idea将github上的代码clone下来。
可以看到项目目录下有两个模块,
- kraps-rpc
- kraps-rpc-example
kraps-rpc存放的是Spark RPC的源代码,而我们要做的即是运行 kraps-rpc-example中的示例代码。
启动PRC的话首先需要启动Server端,开启监听服务,然后才能通过Client进行访问。这里在HelloworldServer.scala中都已经帮我们写好,不过在main方法中需要修改一下内容,就是将host改为本机地址。
def main(args: Array[String]): Unit = {
// val host = args(0)
val host = "localhost"
val config = RpcEnvServerConfig(new RpcConf(), "hello-server", host, 52345)
val rpcEnv: RpcEnv = NettyRpcEnvFactory.create(config)
val helloEndpoint: RpcEndpoint = new HelloEndpoint(rpcEnv)
rpcEnv.setupEndpoint("hello-service", helloEndpoint)
rpcEnv.awaitTermination()
}
然后我们只需要右键该文件然后执行即可。
接下来我们就需要启动Client端代码,我们先到HelloworldClient文件中,这里面提供了同步和异步两个方法可以运行。代码同样都已经写好,通过修改注释即可使用不同的方法运行。同样是右键点击该文件执行。
def main(args: Array[String]): Unit = {
//异步方法
//asyncCall()
//同步方法
syncCall()
}
异步方法中,ask会返回一个Future(注意这里的Future是scala中的Future,和java的是不一样的)。并且在Future运行结果出来前,我们可以去做其他事情(异步的优势所在)。scala中的Future和Java的Future有些不同,不过这可以先不去管,先当作Java里面的Future即可。
def asyncCall() = {
val rpcConf = new RpcConf()
val config = RpcEnvClientConfig(rpcConf, "hello-client")
val rpcEnv: RpcEnv = NettyRpcEnvFactory.create(config)
val endPointRef: RpcEndpointRef = rpcEnv.setupEndpointRef(RpcAddress("localhost", 52345), "hello-service")
val future: Future[String] = endPointRef.ask[String](SayHi("neo"))
future.onComplete {
case scala.util.Success(value) => println(s"Got the result = $value")
case scala.util.Failure(e) => println(s"Got error: $e")
}
Await.result(future, Duration.apply("3s"))
//在future结果运行出来前,会先打印这条语句。
println("print me at first!")
Thread.sleep(7)
}
而同步方法是直接将结果返回,并且会阻塞,这个时间内你无法做其他事情,只能等待,直到结果返回。
def syncCall() = {
val rpcConf = new RpcConf()
val config = RpcEnvClientConfig(rpcConf, "hello-client")
val rpcEnv: RpcEnv = NettyRpcEnvFactory.create(config)
val endPointRef: RpcEndpointRef = rpcEnv.setupEndpointRef(RpcAddress("localhost", 52345), "hello-service")
val result = endPointRef.askWithRetry[String](SayBye("neo"))
println(result)
}
很简单是吧,运行过例子后,我们就可以来了解一些Spark RPC运行过程中至关重要的两个编程模型,以及在这其中使用到的一些主要的类。
三.Spark RPC中的两个编程模型以及各个类
Spark RPC是使用了Actor模型和Reactor模型的混合模式,我们结合两种模型分别说明Spark RPC中各个类的作用:
首先我们先来看Spark RPC的类图。
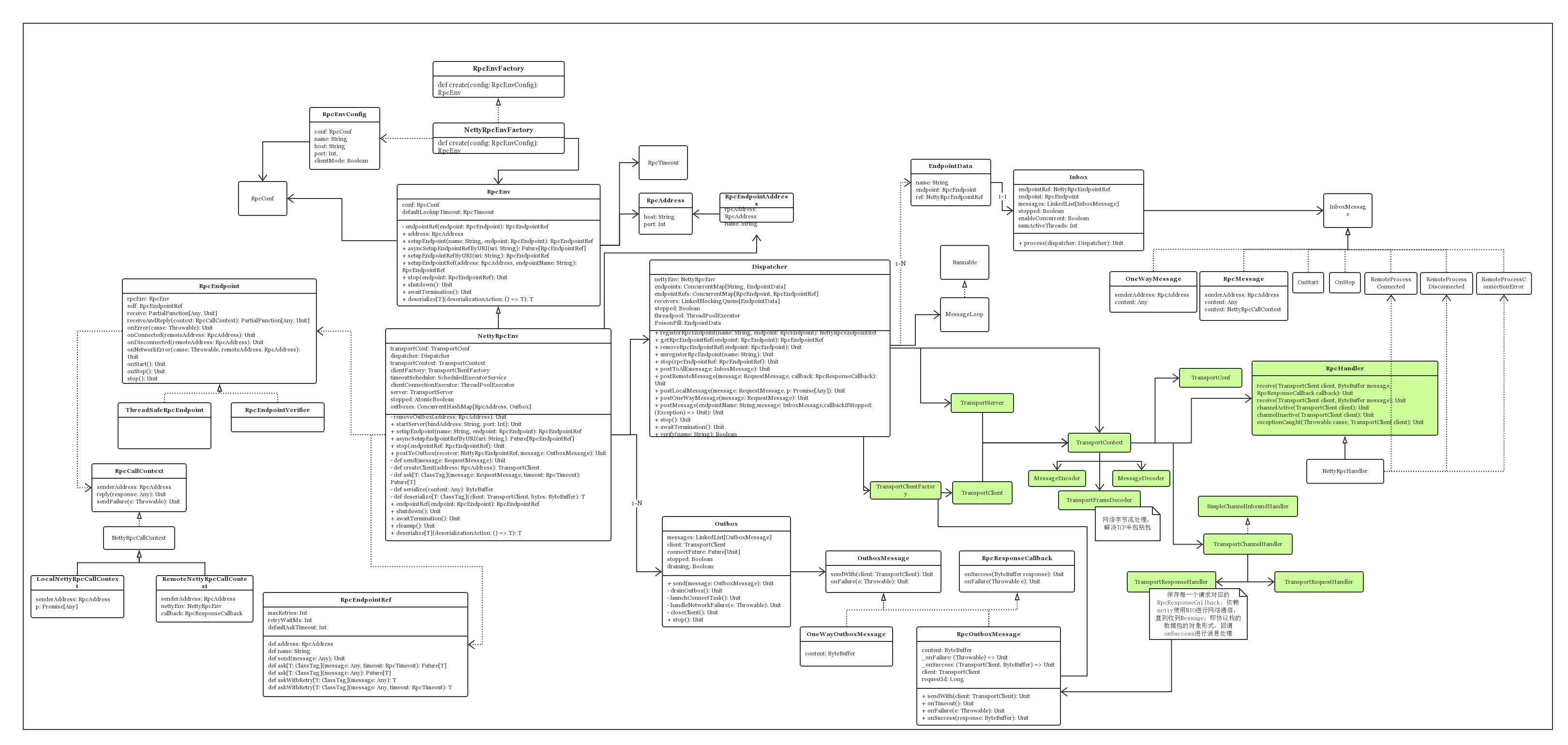
是不是感觉很乱?没事,我们来逐步剖析各个类。
为了更加清楚了说明各个类的关系,我们要先知道两个模型,分别是Actor模型和Reactor模型,我们将从这两个模型的角度来拆解各个类的关系。
Actor模型
其实之前也有写过一篇介绍Actor模型的文章,感兴趣的同学可以点击这里查看Actor模型浅析。
其实Actor主要就是这副图的内容:
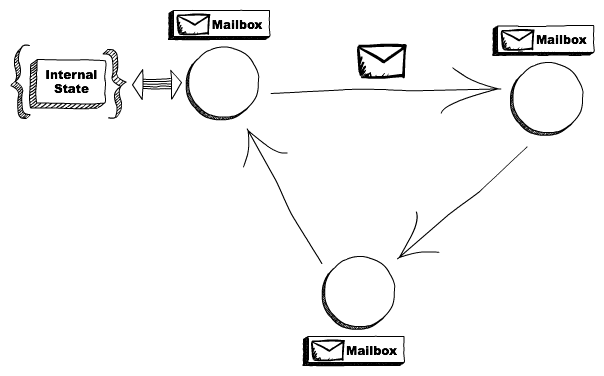
在Spark RPC中有几个类分别与Actor模型中的各个角色对应,对应如下,左边的是Spark RPC中的类,右边的是Actor模型中的角色:
RpcEndpoint => Actor
RpcEndpointRef => ActorRef
RpcEnv => ActorSystem
我们逐个来看:
RpcEnv --RPC Environment
RPC Environment 是 RpcEndpoint 的运行环境。它管理 RpcEndpoint 的整个生命周期:
- 通过名字或 URI 注册 RpcEndpoint。
- 对到底的消息进行路由,决定分发给哪个 RpcEndpoint。
- 停止 RpcEndpoint。
RPC Environment在akka已经被移除的2.0后面版本中,RPC Environment的实现类是NettyRpcEnv。通常是由NettyRpcEnvFactory.create创建。
RpcEndpoint
RpcEndpoint能通过callbacks接收消息。通常需要我们自己写一个类继承RpcEndpoint。编写自己的接收信息和返回信息规则。
RpcEndpoint的生命周期被RPC Environment管理。其生命周期包括,onStart,receive和onStop。
它是作为服务端,比如上面例子中的HelloworldServer就是一个RpcEndpoint。
RpcEndpointRef
RpcEndpointRef是RpcEndpoint在RPC Environment中的一个引用。
它包含一个地址(即Spark URL)和名字。RpcEndpointRef作为客户端向服务端发送请求并接收返回信息,通常可以选择使用同步或异步的方式进行发送。
Reactor模型
Spark RPC采用Actor模型和Reactor模型混合的结构,上面已经介绍了Actor,那么现在我们就来介绍Reactor模型,同样,我们可以从一张图来看Reactor的架构。
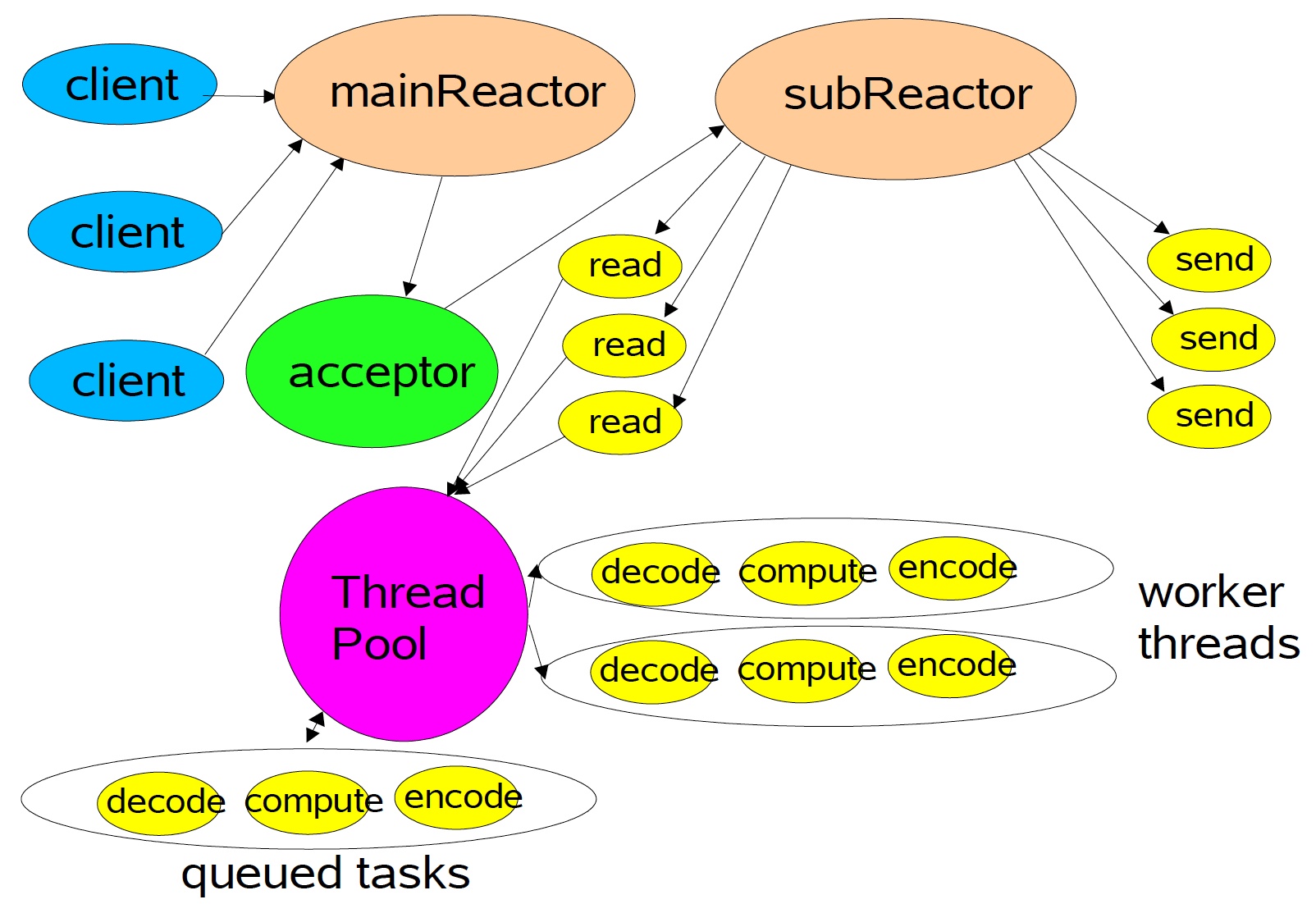
使用Reactor模型,由底层netty创建的EventLoop做I/O多路复用,这里使用Multiple Reactors这种形式,如上图所示,从netty的角度而言,Main Reactor和Sub Reactor对应BossGroup和WorkerGroup的概念,前者负责监听TCP连接、建立和断开,后者负责真正的I/O读写。
而图中的ThreadPool就是的Dispatcher中的线程池,它来解耦开来耗时的业务逻辑和I/O操作,这样就可以更scalabe,只需要少数的线程就可以处理成千上万的连接,这种思想是标准的分治策略,offload非I/O操作到另外的线程池。
Dispatcher
Dispatcher的主要作用是保存注册的RpcEndpoint、分发相应的Message到RpcEndPoint中进行处理。Dispatcher即是上图中ThreadPool的角色。它同时也维系一个threadpool,用来处理每次接受到的InboxMessage。而这里处理InboxMessage是通过inbox实现的。
Inbox
Inbox其实属于Actor模型,是Actor中的信箱,不过它和Dispatcher联系紧密所以放这边。
InboxMessage有多个实现它的类,比如OneWayMessage,RpcMessage,等等。Dispatcher会将接收到的InboxMessage分发到对应RpcEndpoint的Inbox中,然后Inbox便会处理这个InboxMessage。
OK,这次就先介绍到这里,下次我们从代码的角度来看Spark RPC的运行机制
如果觉得对你有帮助,不妨关注一波吧~~
参考资料:https://zhuanlan.zhihu.com/p/28893155
推荐阅读:
从分治算法到 MapReduce
Actor并发编程模型浅析
大数据存储的进化史 --从 RAID 到 Hadoop Hdfs
一个故事告诉你什么才是好的程序员
Spark RPC框架源码分析(一)简述的更多相关文章
- Spark RPC框架源码分析(二)RPC运行时序
前情提要: Spark RPC框架源码分析(一)简述 一. Spark RPC概述 上一篇我们已经说明了Spark RPC框架的一个简单例子,Spark RPC相关的两个编程模型,Actor模型和Re ...
- Spark RPC框架源码分析(三)Spark心跳机制分析
一.Spark心跳概述 前面两节中介绍了Spark RPC的基本知识,以及深入剖析了Spark RPC中一些源码的实现流程. 具体可以看这里: Spark RPC框架源码分析(二)运行时序 Spark ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
- Spark Scheduler模块源码分析之TaskScheduler和SchedulerBackend
本文是Scheduler模块源码分析的第二篇,第一篇Spark Scheduler模块源码分析之DAGScheduler主要分析了DAGScheduler.本文接下来结合Spark-1.6.0的源码继 ...
- 介绍开源的.net通信框架NetworkComms框架 源码分析
原文网址: http://www.cnblogs.com/csdev Networkcomms 是一款C# 语言编写的TCP/UDP通信框架 作者是英国人 以前是收费的 售价249英镑 我曾经花了 ...
- Android Small插件化框架源码分析
Android Small插件化框架源码分析 目录 概述 Small如何使用 插件加载流程 待改进的地方 一.概述 Small是一个写得非常简洁的插件化框架,工程源码位置:https://github ...
- YII框架源码分析(百度PHP大牛创作-原版-无广告无水印)
YII 框架源码分析 百度联盟事业部——黄银锋 目 录 1. 引言 3 1.1.Yii 简介 3 1.2.本文内容与结构 3 2.组件化与模块化 4 2.1.框架加载和运行流程 4 ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- 【原】Spark中Master源码分析(一)
Master作为集群的Manager,对于集群的健壮运行发挥着十分重要的作用.下面,我们一起了解一下Master是听从Client(Leader)的号召,如何管理好Worker的吧. 1.家当(静态属 ...
随机推荐
- 8天入门docker系列 —— 第一天 docker出现前的困惑和简单介绍
docker出来也有很多年了,但用到的公司其实并不是很多,docker对传统开发是一个革命性的,几乎颠覆了之前我们传统的开发方法和部署模式,而大多 公司保守起见或不到万不得已基本上不会去变更现有模式. ...
- 使用Springboot + Gradle快速整合Mybatis-Plus
使用Springboot + Gradle快速整合Mybatis-Plus 作者:Stanley 罗昊 [转载请注明出处和署名,谢谢!] MyBatis-Plus(简称 MP)是一个 MyBatis ...
- 300+ Manual Testing and Selenium Interview Questions and Answers
Manual testing is a logical approach and automation testing complements it. So both are mandatory an ...
- SQL - Order By如何处理NULL
问题来了.执行SQL语句 SELECT * FROM tbl ORDER BY x, y 如果用来排序的列x.y当中有NULL值,那么它们的顺序是怎样的呢? 不同的数据库有不同的答案,目前的主流数据库 ...
- PowerShell禁止执行脚本解决方法
无法加载文件 C:\***.p s1,因为在此系统中禁止执行脚本.有关详细信息,请参阅 "get-help about_signing". 所在位置 行:1 字符: 18 + .\ ...
- 如何在WSL下使用VS Code
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者.本有由葡萄城技术团队翻译并整理 自微软开始宣布拥抱开源以来,我认为微软发布的最棒的两大功能是:Visual S ...
- iOS可视化动态绘制连通图(Swift版)
上篇博客<iOS可视化动态绘制八种排序过程>可视化了一下一些排序的过程,本篇博客就来聊聊图的东西.在之前的博客中详细的讲过图的相关内容,比如<图的物理存储结构与深搜.广搜>.当 ...
- Scala的类层级讲解
Scala的类层级 Scala里,每个类都继承自通用的名为Any的超类. 因为所有的类都是Any的子类,所以定义在Any中的方法就是"共同的"方法:它们可以被任何对象调用. Sca ...
- ubuntu修改键盘映射
code {margin: 0;padding: 0;font-size: 100%;word-break: normal;background: transparent;border: 0;}ol ...
- 查看网卡及对应的IP、MAC
#!/bin/bash# judge OS OS_release=`cat /etc/redhat-release | awk '{print $(NF-1)}'|cut -c 1`# To obta ...