InnoDB页压缩技术
Ⅰ、想起一个报错
1.1 创建表报错
(root@localhost) [(none)]> create tablespace ger_space add datafile 'ger_space.ibd' file_block_size=8192;
Query OK, 0 rows affected (0.02 sec)
(root@localhost) [(none)]> create database test;
Query OK, 1 row affected (0.01 sec)
(root@localhost) [(none)]> create table test_ger(a int) tablespace=ger_space;
(root@localhost) [(none)]> use test;
Database changed
(root@localhost) [test]> create table test_ger(a int) tablespace=ger_space;
ERROR 1478 (HY000): InnoDB: Tablespace `ger_space` uses block size 8192 and cannot contain a table with physical page size 16384
2.1 解决
(root@localhost) [test]> create table test_ger(a int) tablespace=ger_space row_format=compressed, key_block_size=8;
Query OK, 0 rows affected (0.14 sec)
amazing!!!(~﹃~)~zZ
这里用到一个压缩page的技术,本章我们讨论一下InnoDB的页压缩
Ⅱ、传统压缩方式(from 5.5)
2.1 原理——伙伴算法
- 磁盘中存放压缩页(row_format=compressed),假设key_block_size=8K,Buffer Pool的页大小是16K
- 向Free List中申请空闲的页,如果没有空闲页,则向LRU List申请页,如果LRU满了,则找LRU中最后的一个页,如果最后的页是脏页,则做flush操作,最后得到一个空白的页(16K)
- 该16k的空白页,就给8K的压缩页使用,这样就多出一个8K的空间 ,该空间会移到8K的Free List中去
- 如果有一个4K的压缩页,就把8K的Free list中的空白页给他用,然后多余的4K的空间移到4K的Free List中去
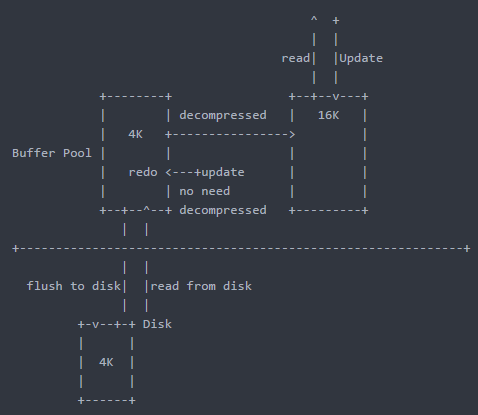
注意点:
- 这种压缩是基于页的,每个表的页大小可以不同,压缩算法是L777
- 当用户获取数据时,如果压缩的页没有在Innodb_Buffer_Pool缓冲池里,那么会从磁盘加载进去,并且会在Innodb_Buffer_Pool缓冲池里开辟一个新的未压缩的16KB的数据页来解压缩,为了减少磁盘I/O以及对页的解压操作(更快地查询),在缓冲池里同时存在着被压缩的和未压缩的页
- 为了给其他需要的数据页腾出空间,缓冲池里会把未压缩的数据页踢出去,而保留压缩的页在内存中,如果未压缩的页在一段时间内没有被访问,那么会直接刷入磁盘中,因此缓冲池中可能有压缩和未压缩的页,也可能只有压缩页
- 压缩页保留的原因是为了在更新数据的时候,将redo添加到压缩页的空闲部分,如果要刷回磁盘,可以直接将该压缩页刷回去,如果该页被写满,则做一次reorganize操作(在此之前也要做解压),真的写满了才做分裂
缺点:
- 压缩页占用了Buffer Pool的空间,对于热点数据来说,相当于内存小了,可能造成性能下降(热点空间变小)
- 所以在开启了压缩后,Buffer Pool的空间要相应增大
- 如果启用压缩后节省的磁盘IO能够抵消掉Buffer Pool空间变小所带来的性能下降,那整体性能还是会上涨,所以Buffer Pool要尽可能大
2.2 玩两手
直接创建
(root@localhost) [test]> create table comps_test(a int) row_format=compressed, key_block_size=4;
Query OK, 0 rows affected (0.04 sec)
对已存在的表启用压缩,并且页大小为4k,
alter table xxxxx
engine=innodb
row_format=compressed,key_block_size=4
可以设置为1 2 4 8 16
操作须知:
指定row_format=compressed,则可忽略key_block_size的值,这时使用默认innodb页的一半,即8kb
指定key_block_size的值,则可忽略row_format=compressed,会自动启用压缩
0代表默认压缩页的值,Innodb页的一半
key_block_size的值只能小于等于innodb page size,若指定了一个大于innodb page size的值,mysql会忽略这个值然后产生一个警告,这时key_block_size的值是Innodb页的一半
若设置了innodb_strict_mode=ON,那么指定一个不合法的key_block_size的值是返回报错
tips:
虽然SQL语法中写的是row_format=compressed,但是压缩是针对页的,而不是记录,即读页的时候解压,写页的时候压缩,并不会在读取或写入单个记录(row)时就进行解压或压缩操作
2.3 细说key_block_size
- key_block_size的可选项是1k,2k,4k,8k,16k(是页大小,不是比例)
- 不是将原来innodb_page_size页大小的数据压缩成key_block_size的页大小,因为有些数据可能不能压缩,或者压缩不到那么小
- 压缩是将原来的页的数据通过压缩算法压缩到一定的大小,然后用key_block_size大小的页去存放
- 比如原来的innodb_page_size大小是16K,现在的key_block_size设置为8K,某表的数据大小是24k,原先使用2个16k的页存放,压缩后数据从24k变为18k,由于现在的key_block_size=8k,所以需要3个8K的页存放压缩后的18k数据,多余的空间可以留给下次插入或者更新
- 压缩比和设置的key_block_size没有关系,压缩比看数据本身和算法,key_block_size仅仅是设置存放压缩数据的页大小
tips:
不解压也能插入数据,通过在剩余空间直接存放redo log,然后页空间存放满后,再解压,利用redo log更新完成后,最后再压缩存放(此时就没有redo log 了)以此来减少解压和压缩的次数
2.4 重点须知
并不是key_block_size越小,压缩比越高,只是页的大小发生了修改
压缩过程,16k的页压8k,先判断能不能压,可以就存为8k,压完大于8k,比如12k,这时候就会存为两个8k
16k压到8k成功率在80%~90%,但是再压就不能保证了
2.5 查看缓冲池中的压缩页
(root@localhost) [(none)]> SELECT
-> table_name,
-> space,
-> page_number,
-> index_name,
-> compressed,
-> compressed_size
-> FROM
-> information_schema.innodb_buffer_page_lru
-> WHERE
-> compressed = 'yes'
-> LIMIT 5;
+------------+-------+-------------+------------+------------+-----------------+
| table_name | space | page_number | index_name | compressed | compressed_size |
+------------+-------+-------------+------------+------------+-----------------+
| NULL | 168 | 502 | NULL | YES | 4096 |
| NULL | 168 | 505 | NULL | YES | 4096 |
| NULL | 168 | 508 | NULL | YES | 4096 |
| NULL | 168 | 510 | NULL | YES | 4096 |
| NULL | 168 | 513 | NULL | YES | 4096 |
+------------+-------+-------------+------------+------------+-----------------+
5 rows in set (0.00 sec)
(root@localhost) [(none)]> SELECT
-> table_id, name, space, row_format, zip_page_size
-> FROM
-> information_schema.INNODB_SYS_TABLES
-> WHERE
-> space = 168;
+----------+----------------+-------+------------+---------------+
| table_id | name | space | row_format | zip_page_size |
+----------+----------------+-------+------------+---------------+
| 173 | sbtest/sbtest1 | 168 | Compressed | 4096 |
+----------+----------------+-------+------------+---------------+
1 row in set (0.00 sec)
(root@localhost) [(none)]> show create table sbtest.sbtest1\G
*************************** 1. row ***************************
Table: sbtest1
Create Table: CREATE TABLE `sbtest1` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`k` int(10) unsigned NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`)
) ENGINE=InnoDB AUTO_INCREMENT=10000001 DEFAULT CHARSET=latin1 MAX_ROWS=1000000 ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=4
1 row in set (0.00 sec)
一路摸下来,果然是个压缩表
再看下压缩页在bp中的存储
(root@localhost) [(none)]> show engine innodb status\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992
Dictionary memory allocated 127372
Buffer pool size 8191
Free buffers 7759
Database pages 632
Old database pages 253
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 597, created 35, written 42
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 632, unzip_LRU len: 4 压缩页在bp中的长度是4
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
...
2.6 查看压缩比
查看压缩比,看information_schema.innodb_cmp表
这个表里面的数据是累加的,是全局信息,没法对应到某一张表,查它之前先查另一张表来清空此表
select * from information_schema.innodb_cmp_reset;
把innodb_cmp表中的数据复制过来,并清空innodb_cmp,此处不展示结果
玩起来了
(root@localhost) [emp]> create table emp_comp like emp;
Query OK, 0 rows affected (0.26 sec)
(root@localhost) [emp]> alter table emp_comp row_format=compressed,key_block_size=4;
Query OK, 0 rows affected (0.23 sec)
Records: 0 Duplicates: 0 Warnings: 0
(root@localhost) [emp]> show create table emp_comp\G
*************************** 1. row ***************************
Table: emp_comp
Create Table: CREATE TABLE `emp_comp` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` enum('M','F') NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`),
KEY `ix_firstname` (`first_name`),
KEY `ix_3` (`emp_no`,`first_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=4
1 row in set (0.04 sec)
(root@localhost) [emp]> insert into emp_comp select * from emp;
Query OK, 300024 rows affected (23.13 sec)
Records: 300024 Duplicates: 0 Warnings: 0
看压缩比咯
(root@localhost) [emp]> select * from information_schema.innodb_cmp;
+-----------+--------------+-----------------+---------------+----------------+-----------------+
| page_size | compress_ops | compress_ops_ok | compress_time | uncompress_ops | uncompress_time |
+-----------+--------------+-----------------+---------------+----------------+-----------------+
| 1024 | 0 | 0 | 0 | 0 | 0 |
| 2048 | 0 | 0 | 0 | 0 | 0 |
| 4096 | 34296 | 27184 | 9 | 7743 | 0 |
| 8192 | 0 | 0 | 0 | 0 | 0 |
| 16384 | 0 | 0 | 0 | 0 | 0 |
+-----------+--------------+-----------------+---------------+----------------+-----------------+
5 rows in set (0.69 sec)
(root@localhost) [emp]> select 27184/34296; # compress_ops_ok/compress_ops
+-------------+
| 27184/34296 |
+-------------+
| 0.7926 |
+-------------+
1 row in set (0.11 sec)
压缩比为79.26%
看下物理存储
[root@VM_0_5_centos emp]# ll -h *.ibd
-rw-r----- 1 mysql mysql 40M Feb 27 19:01 emp.ibd
-rw-r----- 1 mysql mysql 20M Feb 27 19:36 emp_comp.ibd
能看出来表空间小了很多,但是不是79.26%,这里有时间需要理解一下
打开一个参数,可以看到每个表的压缩情况,此参数默认不开,会影响性能
(root@localhost) [emp]> set global innodb_cmp_per_index_enabled=1;
Query OK, 0 rows affected (0.09 sec)
重复上面的测试,这次压到2k,过程省略只看结果
(root@localhost) [emp]> select * from information_schema.innodb_cmp;
+-----------+--------------+-----------------+---------------+----------------+-----------------+
| page_size | compress_ops | compress_ops_ok | compress_time | uncompress_ops | uncompress_time |
+-----------+--------------+-----------------+---------------+----------------+-----------------+
| 1024 | 0 | 0 | 0 | 0 | 0 |
| 2048 | 68793 | 52455 | 12 | 18353 | 1 |
| 4096 | 0 | 0 | 0 | 0 | 0 |
| 8192 | 0 | 0 | 0 | 0 | 0 |
| 16384 | 0 | 0 | 0 | 0 | 0 |
+-----------+--------------+-----------------+---------------+----------------+-----------------+
5 rows in set (0.00 sec)
(root@localhost) [emp]> select * from information_schema.innodb_cmp_per_index;
+---------------+------------+--------------+--------------+-----------------+---------------+----------------+-----------------+
| database_name | table_name | index_name | compress_ops | compress_ops_ok | compress_time | uncompress_ops | uncompress_time |
+---------------+------------+--------------+--------------+-----------------+---------------+----------------+-----------------+
| emp | emp_comp | PRIMARY | 34676 | 23729 | 4 | 11053 | 0 |
| emp | emp_comp | ix_firstname | 20958 | 18349 | 5 | 4384 | 0 |
| emp | emp_comp | ix_3 | 13159 | 10377 | 2 | 2916 | 0 |
+---------------+------------+--------------+--------------+-----------------+---------------+----------------+-----------------+
3 rows in set (0.00 sec)
(root@localhost) [emp]> select 52455/68793;
+-------------+
| 52455/68793 |
+-------------+
| 0.7625 |
+-------------+
1 row in set (0.06 sec)
(root@localhost) [emp]> select (23729+18349+10377)/(34676+20958+13159);
+-----------------------------------------+
| (23729+18349+10377)/(34676+20958+13159) |
+-----------------------------------------+
| 0.7625 |
+-----------------------------------------+
1 row in set (0.00 sec)
可以直接看到emp.emp_comp这个表的压缩比(innodb索引即数据)
当只有一个表的时候innodb_cmp等于innodb_cmp_per_index
2.6 压缩后的存储和性能
一个问题,压缩时将key_block_size设置为innodb_page_size有没有意义
答:有意义,key_block_size的设置不影响压缩本身(只和数据本身及压缩算法有关),只是确定压缩后的数据存放的页大小,varchar、text等数据类型这么压效果还是很明显的
压缩后的存储和性能呢?
github放图好麻烦,大概弄个差不多的图将就下
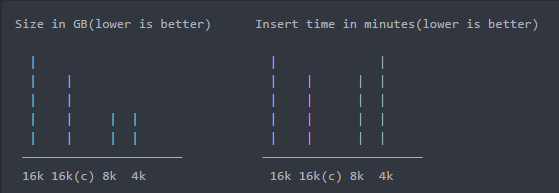
结论:
- inodb_page_size=16k的数据设置key_block_size=16是可以压缩的,且效果比较明显
- 并不是key_block_size设置的越小,压缩率就越高,上图中8K和4K的压缩率几乎一样
- 在启用压缩后,16K和8K的插入性能要好于原来未压缩的插入性能,所以启用了压缩,性能不一定会变差
- 在I/O Bound(IO密集型)的业务场景下,减少I/O操作的次数对性能提升比较明显
- key_block_size的设置的值(经验值)通常为innodb_page_size的1/2
Ⅲ、transparent page compression(from 5.7)
3.1 先玩
(root@localhost) [test]> create table trans_test1(a int) compression='zlib';
Query OK, 0 rows affected, 1 warning (0.04 sec)
(root@localhost) [test]> create table trans_test2(a int) compression='lz4';
Query OK, 0 rows affected, 1 warning (0.06 sec)
(root@localhost) [test]> alter table trans_test1 compression='lz4';
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
alter table会很快,因为它不会真的改,只是下次压缩的时候才会用,不会重新压,如果非要马上生效则需要optimize
(root@localhost) [test]> optimize table trans_test1;
+------------------+----------+----------+-------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+------------------+----------+----------+-------------------------------------------------------------------+
| test.trans_test1 | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| test.trans_test1 | optimize | status | OK |
+------------------+----------+----------+-------------------------------------------------------------------+
2 rows in set, 1 warning (0.23 sec)
(root@localhost) [test]> show warnings;
+---------+------+---------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+---------------------------------------------------------------------------------------------+
| Warning | 138 | Punch hole is not supported by the file system. Compression disabled for 'test/trans_test1' |
+---------+------+---------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
错误日志中有下面这段:
2017-04-22T19:20:14.168298+8:00 0 [Note] InnoDB: PUNCH HOLE support not available
换言之,5.7现在还不能用这个功能,二进制包编译的时候没把PUNCH HOLE编译进去
怎么解决?
自己编译源码,带上PUNCH HOLE,或者用percona
MySQL8.0的时候就完美availabe,可以去看看,亲测
create table a ( a int ) compression='lz4';
Query OK, 0 rows affected (0.03 sec)
tips:
5.7.19二进制包已经把做进去了,超赞
经测试,貌似ext3不支持punch hole
lz4和zlib什么区别?
lz4更快,zlib压缩比更高
通常选择lz4,更快,也能压到一半,够用了,hadoop平台很多数据库默认就用lz4
看表空间的文件系统相关内容:
(root@localhost) [(none)]> SELECT
-> space, page_size, fs_block_size, file_size, allocated_size
-> FROM
-> information_schema.INNODB_SYS_TABLESPACES
-> LIMIT 5;
+-------+-----------+---------------+-----------+----------------+
| space | page_size | fs_block_size | file_size | allocated_size |
+-------+-----------+---------------+-----------+----------------+
| 2 | 16384 | 4096 | 98304 | 102400 |
| 3 | 16384 | 4096 | 98304 | 102400 |
| 4 | 16384 | 4096 | 9437184 | 9453568 |
| 5 | 16384 | 4096 | 114688 | 118784 |
| 6 | 16384 | 4096 | 147456 | 151552 |
+-------+-----------+---------------+-----------+----------------+
5 rows in set (0.00 sec)
表空间id page大小 文件系统块大小 文件大小 文件实际分配大小
3.2 再看原理(Hole Punch Size)
细心的朋友会发现,以上整个过程并未指定页大小
这里是是使用了文件系统(filesystem)层中稀疏文件的特性,来达到压缩的目的(文件系统空洞)
1、文件的大小与占用空间:
[root@VM_0_5_centos ~]# dd of=spare-file bs=1k seek=5120 count=0 #创建数据全为0的临时文件
0+0 records in
0+0 records out
0 bytes (0 B) copied, 4.1441e-05 s, 0.0 kB/s
[root@VM_0_5_centos ~]# ls -lh spare-file
-rw-r--r-- 1 root root 5.0M Feb 28 10:53 spare-file #文件大小5M
[root@VM_0_5_centos ~]# du --block-size=1 spare-file
0 spare-file #文件占用空间0M
文件中数据连续为0的部分不占用磁盘空间
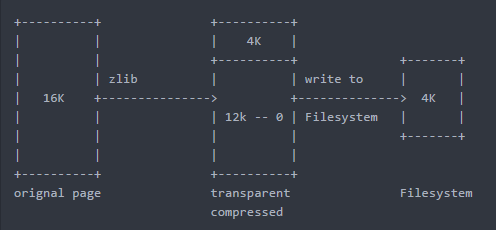
2、文件系统的空洞特性 :
- 一个16k的页,前面数据占了4k,后面填0,被填充的12K的空间,可以提供给后序的插入,更新等使用
- 从innodb的角度看还是16K的页大小,只是文件系统知道该页只需要4K就能够存储(对innodb是透明的)
- SpaceID和PageNumber的读取方式没有改变(细节由文件系统屏蔽)
fopen(f,o_direct|o_punch_hole)
fwrite(f,page) 这时候这个page在磁盘上就是4k的大小
3、TPC过程如下:
对一个页写入磁盘之前先在内存进行压缩,压缩完,前面一部分是压缩的数据,后面填0,再调用fwrite,如果开了punch hole,这时候在磁盘上就实现了压缩
压缩大小是根据文件系统的块大小进行对齐,默认4k,所以16k只能压缩成4,8,16,如果压缩完是6k,那就占用8k
4、新老压缩算法对比:
TPC是调用文件系统层的punch hole,只是写入之前先压缩填0,简洁高效;老的压缩需要指定key_block_size,老算法数据在bp中会占两个空间,一种是压缩的版本,一种是非压缩的版本,更新一个page,两种page都要更新,需要额外开销,较复杂,所以性能时好时坏
TPC的情况下disk每个页大小16k,实际上可能只有4k,8k或者12k,管理依然根据16k来管理
TPC的情况下,在bp里面一个disk page对应一个16k的page,因为在第一次读取的时候从磁盘上读(space,page_no),读完解压,解压完肯定是16k的,在bp里面就只占用一个空间
3.3 性能相关问题
官方测试:
122G,ssd跑ext4
老算法压缩后,storage减小40%,QPS下降20%,还能接受,1w3降到1w出头,最重要的还是sql的性能
新算法,storge减小40%不到,QPS涨到了1w8,提升了30%,读一个块的大小,变小,节省了io操作的时间,cpu的时间在第一次读取的时候做一次解压,写入的时候做一次压缩,并不是每写一条记录压缩解压。
装载测试:
老算法导入速度慢了50%,新算法和不压缩差不多
InnoDB页压缩技术的更多相关文章
- InnoDB透明页压缩与稀疏文件
此文已由作者王慎为授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. MySQL 5.7中包括了很多让人耳目一新的新特性,其中就包括了InnoDB Transparent Pag ...
- 手游包压缩技术引领手游行业实现app页游化
近些年,掌上游戏时代已经成为全民风尚,但身为游戏开发商考虑过手游安装包大小与用户转化率之间的关系吗? 随着手机游戏市场发展愈发壮大,行业发展愈加成熟,手游厂商愈来愈多,手游产业也进入了优胜劣汰的环节, ...
- InnoDB记录压缩及使用分析
此文已由作者温正湖授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 这篇文章,源于RDS组内的一次饭后闲聊,两位小伙伴在探讨InnoDB启用压缩后的种种,比如在磁盘上是怎么存放 ...
- 基于Adobe Flash平台的3D页游技术剖析
写在前面 从黑暗之光,佛本是道,大战神的有插件3D页游.再到如今的魔龙之戒. 足以证明,3D无插件正在引领页游技术的潮流. 目前,要做到3D引擎,有以下几个选择. 说到这里,我们发现.这些都不重要. ...
- 解剖SQLSERVER 第十三篇 Integers在行压缩和页压缩里的存储格式揭秘(译)
解剖SQLSERVER 第十三篇 Integers在行压缩和页压缩里的存储格式揭秘(译) http://improve.dk/the-anatomy-of-row-amp-page-compre ...
- Bundle捆绑压缩技术
Bundle捆绑压缩技术由命名空间System.Web.Optimization中的类提供.顾名思义,这些类是用来优化Web页面性能的,它们通过压缩文件大小,捆绑文件(把多个文件合成一个下载文件)来实 ...
- Java后端实现图片压缩技术
今天来说说图片压缩技术,为什么要使用图片压缩,图片上传不就完事了吗?对的,这在几年前可以这么说,因为几年前还没有现在这么大的并发,也没有现在这么关注性能. 如今手机很多,很多人都是通过手机访问网络或者 ...
- C语言中的内存压缩技术
C语言中的内存压缩技术 前言 在整个研究生阶段我都在参与一个LTE协议栈实现的项目,在这个项目中,我们利用一个自己编写的有限状态机框架将协议栈中每一层实现为一个内核模块.我们知道,在编写内核代码时需要 ...
- 转:关于数据库压缩技术的Survey
原文来自于:http://outofmemory.cn/mysql/database-compression-tech 昨天给团队内的小伙伴做了一个关于数据库压缩技术的Survey,现将其中可以公开的 ...
随机推荐
- workbench的schema讲解一:(维度dimension设置的基本内容)
维度名字尽量用英文:因为,saiku读取schema配置文件时,用中文会出现不可预知的错误.比如,引用维度用中文,就容易出现不可预估的错误.如果要显示中文:每个对象的caption字段里键入中文,则可 ...
- 手把手教你从头开始搭建友善之臂ARM-tiny4412开发环境(史上最详细!!)
创建一个ARM目录 mkdir /disk/A9 -p 接下来你需要准备以下的东西 1.arm-linux-gcc-4.5.1 交叉编译器 2.linux-3.5-tiny4412 ...
- ruby和linux shell共同编程的示例
有了shell为毛还要ruby呢?话不能这么说,有些小功能用ruby还是很方便的,比如说字符串的反转再加1功能用shell来写就比较麻烦.str="123456",我们定义一个反转 ...
- UML用例设计
一. 用例图目的1) 界定系统范围.2) 描述参与者实现的目标和希望系统执行的一定功能.3) 描述系统功能与外部系统,人,组织交互的关系. 二. 用例分解的规则1) 用大型用例描述参与者实现的主要目标 ...
- iOS开发常用第三方库
UI 动画 网络相关 Model 其他 数据库 缓存处理 PDF 图像浏览及处理 摄像照相视频音频处理 响应式框架 消息相关 版本新API的Demo 代码安全与密码 测试及调试 AppleWatch ...
- miniui几个常用知识点汇总
1.在表格中去除系统自带的序列号,请看代码: function allAndBrief(id) { if(id==1){ grid.set({ columns: [ { type: "ind ...
- Word Break(动态规划)
Given a string s and a dictionary of words dict, determine if s can be segmented into a space-separa ...
- for循环嵌套讲解:
1.for循环嵌套讲解: class ForForDemo { public static void main(String[] args) { //大圈套小圈思想: ...
- Msys+MinGW编译VLC
说明:本文只是对官方文档进行简单的翻译总结,旨在帮助一些英文不太好的朋友.官方文档请见wiki.videolan.org/Win32CompileMSYSNew. Msys是MinGW的一个辅助工 ...
- Spring security在MS-SQL下的初始化脚本
-- create table users( -- username nvarchar(50) not null primary key, -- password nvarchar(50) not n ...