Pandas 基础(4) - 读/写 Excel 和 CSV 文件
这一节将分别介绍读/写 Excel 和 CSV 文件的各种方式:
- 读入 CSV 文件
首先是准备一个 csv 文件, 这里我用的是 stock_data.csv, 文件我已上传, 大家可以直接下载下来使用. 正如前面讲过的, csv 文件可以放在 jupyter notebook 同目录下, 这样直接写文件名就可以了, 但是如果没有放在同目录下, 就需要写绝对路径, 否则读取不到.
import pandas as pd
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv')
df
输入输出的效果, 截图如下: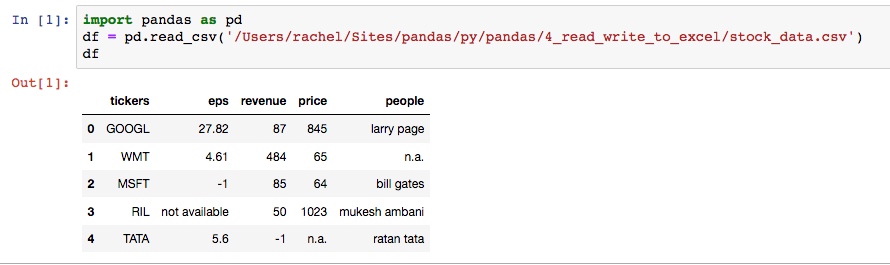
上面就是引入 csv 文件最基本最常规的情况, 下面介绍一些特殊情况:
- 当原 csv 文件有个文件头(如下图):

大家可以自行修改一下 csv 文件, 然后在 jupyter 里运行一下看看得到什么结果, 这里就不截图了, 总之, 显然我们并不想要那多出来的一行, 可以这样做:
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv', header = 1)
这里设置了第二个参数 header=1, 意思就是我们要引入的从第一行开始以下的内容(把文件看作是从第0行开始的)
另外, 还可以这么写:
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv', skiprows=1)
也就是把第二个参数改为 skiprows=1, 意思就是要忽略的行数.
两种方式都能得到相同的结果.
- 如果 csv 文件本身没有表头, 也就是所有的列名都不存在, 但是我们在引入的时候, 我们了解每一列都是什么值, 也就是说我们要如何在引入文件的时候自定义列名:
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv', names=['stickers', 'eps', 'revenue', 'price', 'people'])
- 读取指定的几行数据
现在我们把 csv 文件再还原到初始状态, 看下,如果我们只想读取其中的3条数据, 只要加上参数 nrows=3 即可:
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv', nrows=3)
- 整理数据, 统一空值和不合理的值
现在来具体看下表格中的数据, 会发现有些数据是没有的, 从 csv 文件中导入过来的数据看起来也有点乱, 有的写的是 'n.a.', 有的又是 'not available', 对于这些空数据, 在 Pandas 中可以统一为 'NaN'.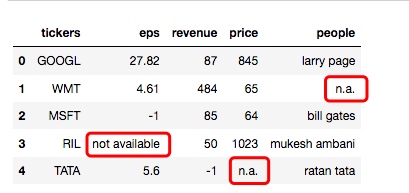
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv', na_values=['not available', 'n.a.'])
这里第二个参数的意思就是, 在读取文件的时候, 凡是遇到 'not available', 'n.a.' 都统一设为空值 'NaN'.
除了空值以外, 还有可能遇到不合理的值, 比如在 'revenue'(收入)列的最后一行, 值是 '-1', 这显然是不合常理的, 有可能是笔误或者什么, 总之, 我们并不知道这个值是什么, 所以也应该处理为空值'NaN'. 那么, 我们能直接在第二个参数的中括号里直接再加上 '-1' 吗? 理论上是可以实现效果的, 但是我们发现在 'eps' 列也有一个 '-1'的值, 而这个值是合理的, 因此如果我们简单粗暴地把 '-1'设为'NaN', 就会影响到这个值, 所以, 我们需要这样做:
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv', na_values={
'eps':['not available', 'n.a.'],
'revenue': ['not available', 'n.a.', -1],
'price': ['not available', 'n.a.'],
'people': ['not available', 'n.a.']
})
这里就是通过 dictionary 的数据形式, 具体明确每一列处理空值的方式.
以上就是读取 CSV 文件的方法和常见问题, 下面看下如何输出 CSV 文件.
- 输出 CSV 文件
只需要简单执行下面这行命令, 就可以生成一个 new.csv 文件, 至于这个文件生成在哪里, 还是去终端看下, 你此时的 jupyter notebook 运行在哪里:
df.to_csv('new.csv')
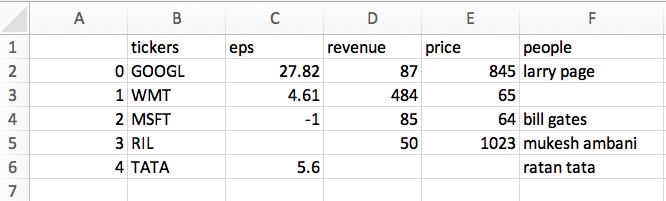
空值部分全部为空白. 但是多了一列序号索引, 如果想去掉:
df.to_csv('new.csv', index=False)
- 输出指定的列
如果你只想要把前两列的内容保存成 csv 文件输出.
首先查看一下所有的列名:
df.columns
输出:
Index(['tickers', 'eps', 'revenue', 'price', 'people'], dtype='object')
只输出 'tickers' 和 'eps' 列:
df.to_csv('new.csv', columns=['tickers', 'eps'])
这时再查看一下 new.csv 文件, 发现里面真的只有两列.
- 不输出表头, 即列名
设置第二个参数 header = False 即可:
df.to_csv('new.csv', header = False)
- 读取 EXCEL 文件
首先是准备一个 excel 文件, 这里我用的是 stock_data.csv, 文件我已上传, 大家可以直接下载下来使用.
import pandas as pd
df = pd.read_excel('stock_data.xlsx', 'Sheet1')
df
输出:
- 整理数据
从上图, 我们可以看到有一些 n.a. 和 not available 的数据, 我们可以做更有针对性的调整:
def convert_people_cell(cell):
if cell == 'n.a.':
return 'Sam Walton'
return cell
def convert_eps_cell(cell):
if cell == 'not available':
return None
return cell
df = pd.read_excel('stock_data.xlsx', 'Sheet1', converters={
'people': convert_people_cell
})
- 保存成 excel 文件输出
- 自定义输出
df.to_excel('new.xlsx', sheet_name='stocks', index=False, startrow=1, startcol=2)
参数说明:
sheet_name='stocks': 设置 sheet 名称
index=False: 去掉序号索引
startrow=1: 从第二行开始表格
startcol=2: 从第三列开始表格
输出: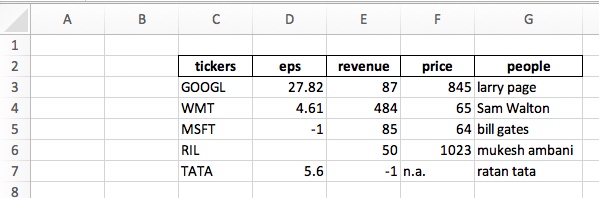
- 把两个 dataframe 输出到一个 excel 表的两个 sheet
df_stocks = pd.DataFrame({
'tickers': ['GOOGL', 'WMT', 'MSFT'],
'price': [845, 65, 64 ],
'pe': [30.37, 14.26, 30.97],
'eps': [27.82, 4.61, 2.12]
})
df_weather = pd.DataFrame({
'day': ['1/1/2017','1/2/2017','1/3/2017'],
'temperature': [32,35,28],
'event': ['Rain', 'Sunny', 'Snow']
})
with pd.ExcelWriter('stocks_weather.xlsx') as writer:
df_stocks.to_excel(writer, sheet_name="stocks")
df_weather.to_excel(writer, sheet_name="weather")
更多关于 Pandas 读取/输出文件的属性, 可以参考官网:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html
Pandas 基础(4) - 读/写 Excel 和 CSV 文件的更多相关文章
- openpyxl -用于读/写Excel 2010 XLSX/XLSM文件的python库
openpyxl -用于读/写Excel 2010 XLSX/XLSM文件的python库¶ https://www.osgeo.cn/openpyxl/index.html
- 用C#写的读写CSV文件
用C#写的读取CSV文件的源代码 CSV文件的格子中包含逗号,引号,换行等,都能轻松读取,而且可以把数据转化成DATATABLE格式 using System; using System.Text; ...
- 使用OLEDB读取excel和csv文件
这是我第一次在博客上写东西,简单的为大家分享一个oledb读取文件的功能吧,这两天在做一个文件导入数据库的小demo,就想着导入前先在页面上展示一下,之前调用Microsoft.Office.Inte ...
- 用PHP读取Excel、CSV文件
PHP读取excel.csv文件的库有很多,但用的比较多的有: PHPOffice/PHPExcel.PHPOffice/PhpSpreadsheet,现在PHPExcel已经不再维护了,最新的一次提 ...
- excel打开csv文件乱码解决办法
参考链接: https://jingyan.baidu.com/article/4dc408484776fbc8d846f168.html 问题:用 Excel 打开 csv 文件,确认有乱码的问题. ...
- Excel打开csv文件乱码问题的解决办法
excel打开csv 出现乱码怎么解决 https://jingyan.baidu.com/article/ac6a9a5e4c681b2b653eacf1.html CSV是逗号分隔值的英文缩写,通 ...
- 如何用Excel打开CSV文件
如何用Excel打开CSV文件? CSV文件一般是MS-SQL 导出查询数据的一种格式.格式结构是 用逗号分隔数据,如果直接用Excel打开那么数据不会自动分列.需要进行一定的设置.下面是设置过程. ...
- 使用OLEDB方式 读取excel和csv文件
/// <summary> /// 使用OLEDB读取excel和csv文件 /// </summary> /// <param name="path" ...
- 深入理解pandas读取excel,txt,csv文件等命令
pandas读取文件官方提供的文档 在使用pandas读取文件之前,必备的内容,必然属于官方文档,官方文档查阅地址 http://pandas.pydata.org/pandas-docs/versi ...
随机推荐
- C语言面试笔记(8/26)
在32位的机器环境下,char.short.int.float.double这样的内置数据类型sizeof值的大小分别为1,2,4,4,8: C++标模板库(standard Template Lib ...
- Consul部署架构
Consul 使用 Raft 算法来保证一致性, 比复杂的 Paxos 算法更直接,用于实现分布式系统的服务发现与配置. 应用Consul提供的服务需要建立Consul集群.在Consul方案中,每个 ...
- 理解linux 密码存储
1. 传统上,linux把加密(哈希)的密码保存在/etc/passwd文件中,passwd文件的格式如下: smithj:x:561:561:Joe Smith:/home/smithj:/bin/ ...
- SparkSQL与Hive on Spark的比较
简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapReduce在同一个层级,即主要解决分布式计算框架的问题 ...
- Linux Shell编程中的几个特殊符号命令 & 、&& 、 ||
https://blog.csdn.net/hack8/article/details/39672145 Linux Shell编程中的几个特殊符号命令 & .&& . || ...
- NodeJS笔记(二)- 修改模块默认保存路径
参考:nodejs prefix(全局)和cache(缓存)windows下设置 假设nodejs根目录为“D:\nodejs” 如下所示,新建“node_cache”文件夹用来存放全局缓存 该路径下 ...
- SVProgressHUD提示框IOS
SVProgressHUD--比MBProgressHUD更好用的 iOS进度提示组件 项目里用到SVProgressHud,感觉背景颜色太丑,因为很久很久以前改过,就想在这个项目里也改下,但是时间过 ...
- Mac 报错:-bash: telnet: command not found
解决方法 /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/i ...
- java框架之SpringBoot(2)-配置
规范 SpringBoot 使用一个全局的配置文件,配置文件名固定为 application.properties 或 application.yml .比如我们要配置程序启动使用的端口号,如下: s ...
- js之prototype 原型对象
原型对象prototype可以这么理解,是该类的实例对象的模板,每个实例对象都是先复制一份该类的prototype,通过这个可以让类的实例拥有相同的功能 String.prototype.say= ...