python爬虫入门---第二篇:获取2019年中国大学排名
我们需要爬取的网站:最好大学网
我们需要爬取的内容即为该网页中的表格部分:
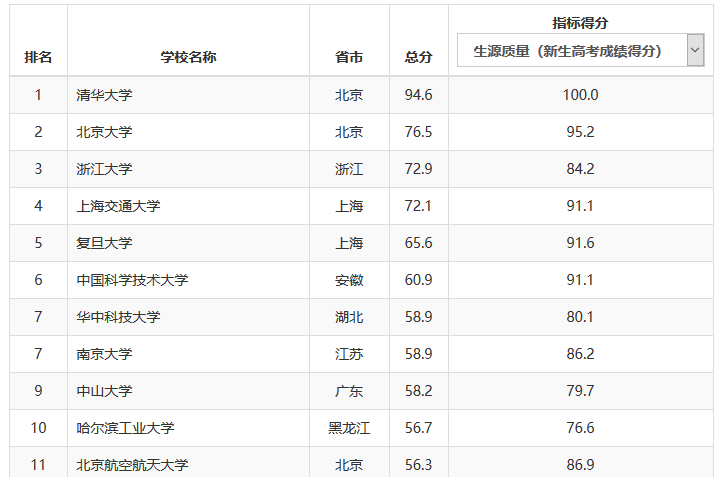
该部分的html关键代码为:
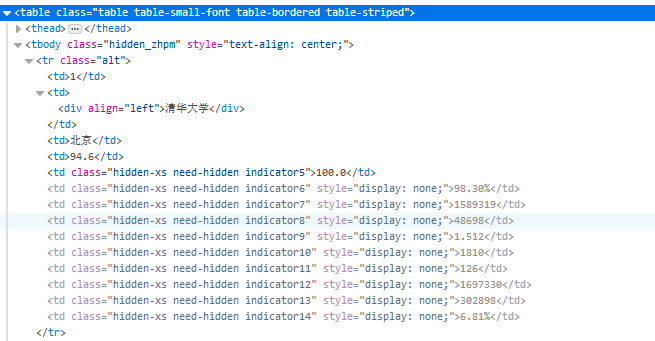
其中整个表的标签为<tbody>标签,每行的标签为<tr>标签,每行中的每个单元格的标签为<td>标签,而我们所需的内容即为每个单元格中的内容。
因此编写程序的大概思路就是先找到整个表格的<tbody>标签,再遍历<tbody>标签下的所有<tr>标签,最后遍历<tr>标签下的所有<td>标签,
我们用二维列表来存储所有的数据,其中二维列表中的每个列表用于存储一行中的每个单元格数据,即<tr>标签下的所有<td>标签中的所有字符串。
代码如下;
import requests
from bs4 import BeautifulSoup
import bs4 def get_html_text(url):
'''返回网页的HTML代码'''
try:
res = requests.get(url, timeout = 6)
res.raise_for_status()
res.encoding = res.apparent_encoding
return res.text
except:
return '' def fill_ulist(ulist, html):
'''将我们所需的数据写入一个列表ulist''' #解析HTML代码,并获得解析后的对象soup
soup = BeautifulSoup(html, 'html.parser')
#遍历得到第一个<tbody>标签
tbody = soup.tbody
#遍历<tbody>标签的孩子,即<tbody>下的所有<tr>标签及字符串
for tr in tbody.children:
#排除字符串
if isinstance(tr, bs4.element.Tag):
#使用find_all()函数找到tr标签中的所有<td>标签
u = tr.find_all('td')
#将<td>标签中的字符串内容写入列表ulist
ulist.append([u[0].string, u[1].string, u[2].string, u[3].string]) def display_urank(ulist):
'''格式化输出大学排名'''
tplt = "{:^5}\t{:{ocp}^12}\t{:{ocp}^5}\t{:^5}"
#方便中文对其显示,使用中文字宽作为站字符,chr(12288)为中文空格符
print(tplt.format("排名", "大学名称", "省市", "总分", ocp = chr(12288)))
for u in ulist:
print(tplt.format(u[0], u[1], u[2], u[3], ocp = chr(12288))) def write_in_file(ulist, file_path):
'''将大学排名写入文件'''
tplt = "{:^5}\t{:{ocp}^12}\t{:{ocp}^5}\t{:^5}\n"
with open(file_path, 'w') as file_object:
file_object.write('软科中国最好大学排名2019版:\n\n')
file_object.write(tplt.format("排名", "大学名称", "省市", "总分", ocp = chr(12288)))
for u in ulist:
file_object.write(tplt.format(u[0], u[1], u[2], u[3], ocp = chr(12288))) def main():
'''主函数'''
ulist = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
file_path = 'university rankings.txt'
html = get_html_text(url)
fill_ulist(ulist, html)
display_urank(ulist)
write_in_file(ulist, file_path) main()
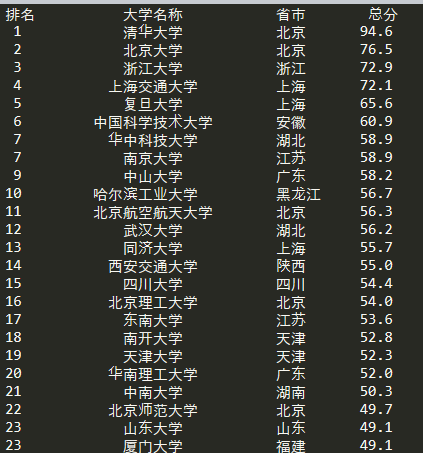
打印显示:
python爬虫入门---第二篇:获取2019年中国大学排名的更多相关文章
- Python爬虫入门案例:获取百词斩已学单词列表
百词斩是一款很不错的单词记忆APP,在学习过程中,它会记录你所学的每个单词及你答错的次数,通过此列表可以很方便地找到自己在记忆哪些单词时总是反复出错记不住.我们来用Python来爬取这些信息,同时学习 ...
- python爬虫入门---第一篇:获取某一网页所有超链接
这是一个通过使用requests和BeautifulSoup库,简单爬取网站的所有超链接的小爬虫.有任何问题欢迎留言讨论. import requests from bs4 import Beauti ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- 转 Python爬虫入门二之爬虫基础了解
静觅 » Python爬虫入门二之爬虫基础了解 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以 ...
- Python爬虫入门有哪些基础知识点
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫入门(二)之Requests库
Python爬虫入门(二)之Requests库 我是照着小白教程做的,所以该篇是更小白教程hhhhhhhh 一.Requests库的简介 Requests 唯一的一个非转基因的 Python HTTP ...
- Python开发【第二篇】:初识Python
Python开发[第二篇]:初识Python Python简介 Python前世今生 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏 ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
随机推荐
- Android-Java-静态成员变量&成员变量&局部变量(内存图&回收机制)
静态成员变量(回收机制) StaticDemo 和 MyDemo package android.java.oop13; class MyDemo { /** * 定义一个静态变量 */ public ...
- 关于UIScrollView不能响应UITouch事件的解决办法
原因是:UIView的touch事件被UIScrollView捕获了. 解决办法:让UIScrollView将事件传递过去.于是最简单的解决办法就是加一个UIScrollView的category.这 ...
- InnoDB体系架构(二)内存
InnoDB体系架构(二)内存 上篇文章 InnoDB体系架构(一)后台线程 介绍了MySQL InnoDB存储引擎后台线程:Master Thread.IO Thread.Purge Thread. ...
- 简单的异步函数async/await例子
function resolveAfter2Seconds(x){ return new Promise(resolve => { setTimeout(() => { resolve(x ...
- Android核心技术Intent和数据存储篇
女孩:上海站到了? 男孩:嗯呢?走向世界~ 女孩:Intent核心技术和数据存储技术? 男孩:对,今日就讲这个~ Intent是各个组件之间用来进行通信的,Intent的翻译为"意图&quo ...
- react小知识
概述 有句话说得很好,代码是写给人看的,顺便让机器执行而已.所以我总结了一些写react不太注意的地方,供以后开发时参考,相信对其他人也有用. 组件封装 由于组件其实就是React.createEle ...
- JS应用实例6:二级联动
本案例很常用,应用场景:注册页面填写籍贯,省市二级联动 总体思想:创建一个二维数组存入省市,获取选中的省份并比较,创建标签遍历添加 代码: <!DOCTYPE html> <html ...
- Linux - 快速进入目录的方法
cd命令技巧 直接进入用户的home目录: cd ~ 进入上一个目录: cd - 进入当前目录的上一层目录: cd .. 进入当前目录的上两层目录: cd ../.. 其他常用方法 利用tab键,自动 ...
- Spring Boot发布将jar包转为war包。
Spring Boot是支持发布jar包和war的,但它推荐的是使用jar形式发布.使用jar包比较方便,但如果是频繁修改更新的项目,需要打补丁包,那这么大的jar包上传都是问题.所以,jar包不一定 ...
- js中数字直接点方法会报错,如1.toString()
Number(11).toString() "11" var num = 111; undefined num.toString() "111" .toStri ...