python爬虫入门---第二篇:获取2019年中国大学排名
我们需要爬取的网站:最好大学网
我们需要爬取的内容即为该网页中的表格部分:
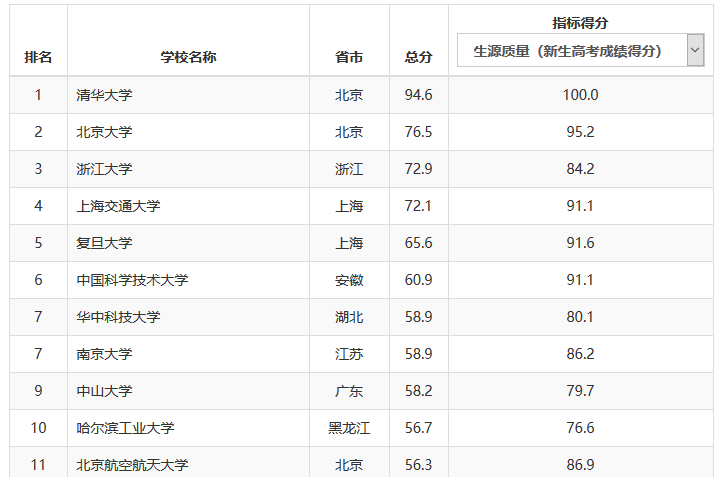
该部分的html关键代码为:
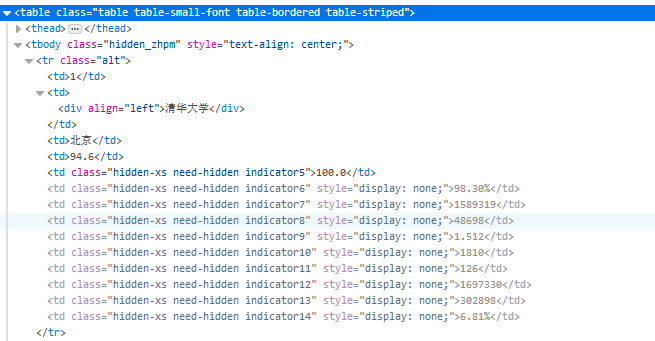
其中整个表的标签为<tbody>标签,每行的标签为<tr>标签,每行中的每个单元格的标签为<td>标签,而我们所需的内容即为每个单元格中的内容。
因此编写程序的大概思路就是先找到整个表格的<tbody>标签,再遍历<tbody>标签下的所有<tr>标签,最后遍历<tr>标签下的所有<td>标签,
我们用二维列表来存储所有的数据,其中二维列表中的每个列表用于存储一行中的每个单元格数据,即<tr>标签下的所有<td>标签中的所有字符串。
代码如下;
import requests
from bs4 import BeautifulSoup
import bs4 def get_html_text(url):
'''返回网页的HTML代码'''
try:
res = requests.get(url, timeout = 6)
res.raise_for_status()
res.encoding = res.apparent_encoding
return res.text
except:
return '' def fill_ulist(ulist, html):
'''将我们所需的数据写入一个列表ulist''' #解析HTML代码,并获得解析后的对象soup
soup = BeautifulSoup(html, 'html.parser')
#遍历得到第一个<tbody>标签
tbody = soup.tbody
#遍历<tbody>标签的孩子,即<tbody>下的所有<tr>标签及字符串
for tr in tbody.children:
#排除字符串
if isinstance(tr, bs4.element.Tag):
#使用find_all()函数找到tr标签中的所有<td>标签
u = tr.find_all('td')
#将<td>标签中的字符串内容写入列表ulist
ulist.append([u[0].string, u[1].string, u[2].string, u[3].string]) def display_urank(ulist):
'''格式化输出大学排名'''
tplt = "{:^5}\t{:{ocp}^12}\t{:{ocp}^5}\t{:^5}"
#方便中文对其显示,使用中文字宽作为站字符,chr(12288)为中文空格符
print(tplt.format("排名", "大学名称", "省市", "总分", ocp = chr(12288)))
for u in ulist:
print(tplt.format(u[0], u[1], u[2], u[3], ocp = chr(12288))) def write_in_file(ulist, file_path):
'''将大学排名写入文件'''
tplt = "{:^5}\t{:{ocp}^12}\t{:{ocp}^5}\t{:^5}\n"
with open(file_path, 'w') as file_object:
file_object.write('软科中国最好大学排名2019版:\n\n')
file_object.write(tplt.format("排名", "大学名称", "省市", "总分", ocp = chr(12288)))
for u in ulist:
file_object.write(tplt.format(u[0], u[1], u[2], u[3], ocp = chr(12288))) def main():
'''主函数'''
ulist = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
file_path = 'university rankings.txt'
html = get_html_text(url)
fill_ulist(ulist, html)
display_urank(ulist)
write_in_file(ulist, file_path) main()
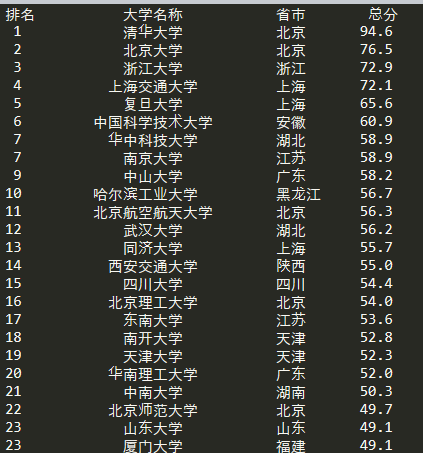
打印显示:
python爬虫入门---第二篇:获取2019年中国大学排名的更多相关文章
- Python爬虫入门案例:获取百词斩已学单词列表
百词斩是一款很不错的单词记忆APP,在学习过程中,它会记录你所学的每个单词及你答错的次数,通过此列表可以很方便地找到自己在记忆哪些单词时总是反复出错记不住.我们来用Python来爬取这些信息,同时学习 ...
- python爬虫入门---第一篇:获取某一网页所有超链接
这是一个通过使用requests和BeautifulSoup库,简单爬取网站的所有超链接的小爬虫.有任何问题欢迎留言讨论. import requests from bs4 import Beauti ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- 转 Python爬虫入门二之爬虫基础了解
静觅 » Python爬虫入门二之爬虫基础了解 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以 ...
- Python爬虫入门有哪些基础知识点
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫入门(二)之Requests库
Python爬虫入门(二)之Requests库 我是照着小白教程做的,所以该篇是更小白教程hhhhhhhh 一.Requests库的简介 Requests 唯一的一个非转基因的 Python HTTP ...
- Python开发【第二篇】:初识Python
Python开发[第二篇]:初识Python Python简介 Python前世今生 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏 ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
随机推荐
- oracle utl_http 访问https类型
https://oracle-base.com/articles/misc/utl_http-and-ssl http://blog.whitehorses.nl/2010/05/27/access- ...
- shell脚本基础教程
一.什么是shell: shell解释:引用别人的话说:“Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁.Shell 既是一种命令语言,又是一种程序设计语言.” 简而言之, ...
- Android开发 - 掌握ConstraintLayout(五)偏差(Bias)
比如实现这样一个场景: "在屏幕宽度的1/4的地方放置一个View" 使用传统布局时,实现按照屏幕的宽度(高度),或者相对两个View之间距离的一个比例来进行布局,就显得非常麻烦, ...
- 856. Score of Parentheses
Given a balanced parentheses string S, compute the score of the string based on the following rule: ...
- struts2框架学习笔记2:配置详解
核心配置文件: <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE struts PUBLIC ...
- ElasticSearch权威指南学习(分布式文档存储)
路由文档到分片 当你索引一个文档,它被存储在单独一个主分片上.Elasticsearch是如何知道文档属于哪个分片的呢?当你创建一个新文档,它是如何知道是应该存储在分片1还是分片2上的呢? 进程不能是 ...
- Spring MVC & Boot & Cloud 技术教程汇总(长期更新)
昨天我们发布了Java成神之路上的知识汇总,今天继续. Java成神之路技术整理(长期更新) 以下是Java技术栈微信公众号发布的关于 Spring/ Spring MVC/ Spring Boot/ ...
- Django项目中使用celery做异步任务
异步任务介绍 在写项目过程中经常会遇到一些耗时的任务, 比如:发送邮件.发送短信等等~.这些操作如果都同步执行耗时长对用户体验不友好,在这种情况下就可以把任务放在后台异步执行 celery就是用于处理 ...
- app测试环境搭建(python)
app测试环境的搭建大致如下几个: 1.appium安装 appium-server或者使用appium-desktop都可以,前者已经不再更新 下载地址:appium.io 2.Android SD ...
- .Net RPC框架Thrift的用法
关于Thrift 下面是来自百度百科关于Thrift的介绍: thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发.它结合了功能强大的软件堆栈和引擎,以构建在 C++, Java, Go ...