我的第一个爬虫程序:利用Python抓取网页上的信息
题外话
我第一次听说Python是在大二的时候,那个时候C语言都没有学好,于是就没有心思学其他的编程语言。现在,我的毕业设计要用到爬虫技术,在网上搜索了一下,Python语言在爬虫技术这方面获得一致好评。
所以从昨天开始就在网上查找各种Python爬虫小程序的源码,可是一天过去了,不仅没有写出一个简单的爬虫程序,反而对Python要引入的各种包和语法越来越迷糊了。去菜鸟教程一看,Python语言相对来讲还是蛮复杂的(虽然它的语法很简单,但是对于初学者,很多封装在一个包里的东西都非常陌生),我恶补了一下Python的语法,然后又开始在网上搜寻各种教程,总之把别人写的爬虫入门级程序都敲了一遍,可是还是无一奏效,有各种各样的错误。
可是,今天发现一篇博客,博主很细心的讲了最简单的爬虫有哪些步骤,用到哪些包,包括源码都一句一句进行了分析,于是我的第一个爬虫程序就成功了。下面分享一下这位博主的博客,并写下自己的感受。
博客地址:Python入门(一):爬虫基本结构&简单实例。
我的实践
下面这张图片就是我按照那位博主的代码,得到的结果。虽然过程中出了一点语法错误(完全是我自己的失误),但结果还是成功的获得了网页上的数据,还进行了筛选,并答应了出来。当然打出来的数据有很多,我只截了一小部分。大家看到的最后一个>>>后面的语句for循环语句块,就是将要进行迭代并打印迭代器的内容,这里就不放图了。
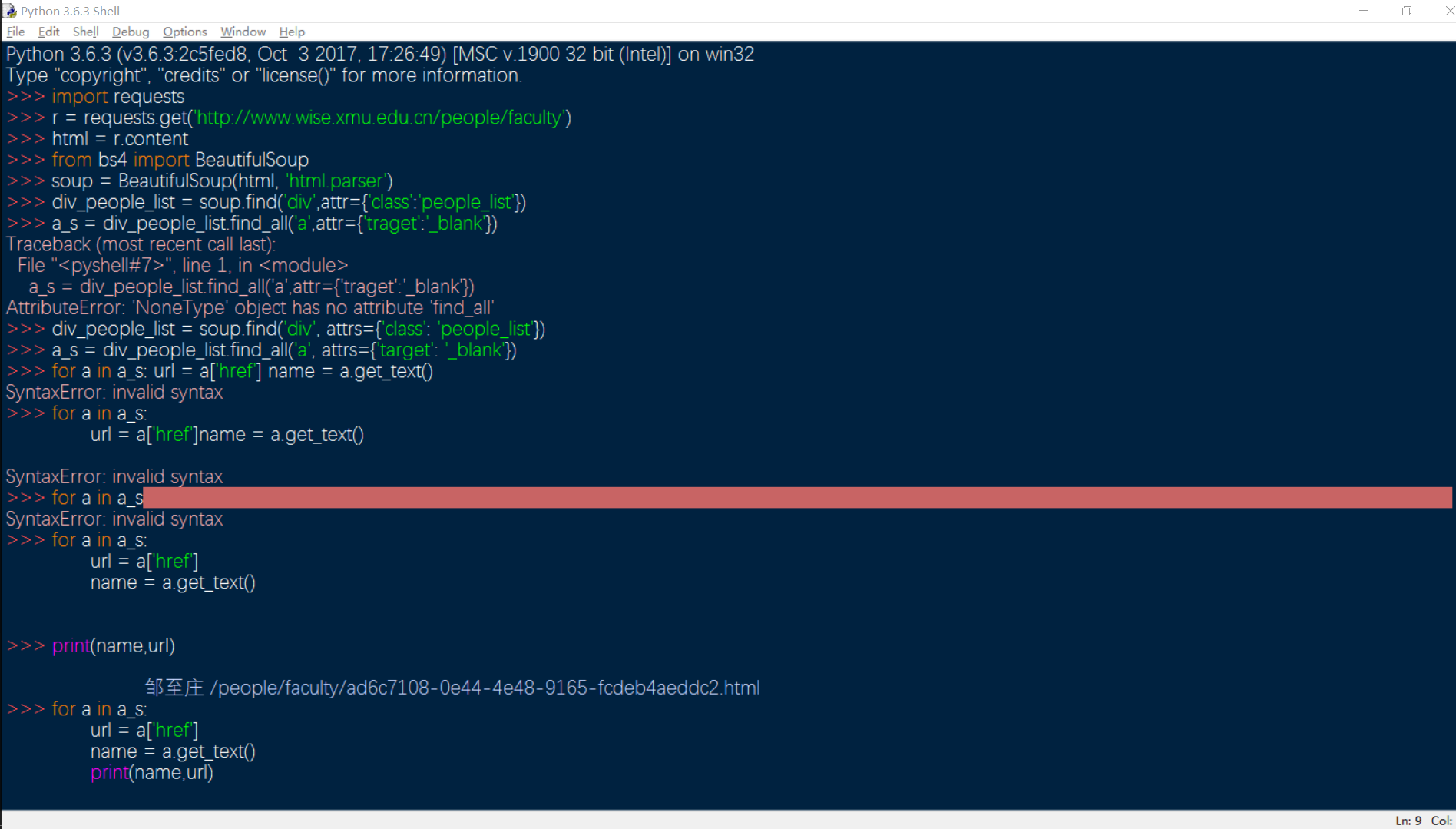
最后的结果就是,所有人的数据都打印出来了。
我的感受就是:Python能做很多事情,搜索引擎就是很大程度上利用了爬虫程序。
我的第一个爬虫程序:利用Python抓取网页上的信息的更多相关文章
- Python 抓取网页并提取信息(程序详解)
最近因项目需要用到python处理网页,因此学习相关知识.下面程序使用python抓取网页并提取信息,具体内容如下: #---------------------------------------- ...
- 网络爬虫-使用Python抓取网页数据
搬自大神boyXiong的干货! 闲来无事,看看了Python,发现这东西挺爽的,废话少说,就是干 准备搭建环境 因为是MAC电脑,所以自动安装了Python 2.7的版本 添加一个 库 Beauti ...
- 利用Crowbar抓取网页异步加载的内容 [Python俱乐部]
利用Crowbar抓取网页异步加载的内容 [Python俱乐部] 利用Crowbar抓取网页异步加载的内容 在做 Web 信息提取.数据挖掘的过程中,一个关键步骤就是网页源代码的获取.但是出于各种原因 ...
- python抓取网页例子
python抓取网页例子 最近在学习python,刚刚完成了一个网页抓取的例子,通过python抓取全世界所有的学校以及学院的数据,并存为xml文件.数据源是人人网. 因为刚学习python,写的代码 ...
- 用python抓取智联招聘信息并存入excel
用python抓取智联招聘信息并存入excel tags:python 智联招聘导出excel 引言:前一阵子是人们俗称的金三银四,跳槽的小朋友很多,我觉得每个人都应该给自己做一下规划,根据自己的进步 ...
- 使用python抓取58手机维修信息
之前在ququ的博客上看到说 python 中的BeautifulSoup 挺好玩的,今天下午果断下载下来,看了下api,挺好用的,完了2把,不错. 晚上写了一个使用python抓取58手机维修信息的 ...
- 【爬虫】利用Scrapy抓取京东商品、豆瓣电影、技术问题
1.scrapy基本了解 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取(更确切来说,网络抓 ...
- [转载]爬虫的自我解剖(抓取网页HtmlUnit)
网络爬虫第一个要面临的问题,就是如何抓取网页,抓取其实很容易,没你想的那么复杂,一个开源HtmlUnit包,4行代码就OK啦,例子如下: 1 2 3 4 final WebClient webClie ...
- 爬虫的自我解剖(抓取网页HtmlUnit)
网络爬虫第一个要面临的问题,就是如何抓取网页,抓取其实很容易,没你想的那么复杂,一个开源`HtmlUnit`包,4行代码就OK啦,例子如下: final WebClient webClient=new ...
随机推荐
- MySQL查询命令_SELECT 子查询
首先创建一个table mysql> create table Total (id int AUTO_INCREMENT PRIMARY KEY,name char(20),stu_num in ...
- bool的值分别为0,1;那哪个代表true哪个代表false?
0为false,1为true. bool表示布尔型变量,也就是逻辑型变量的定义符,以英国数学家.布尔代数的奠基人乔治·布尔(George Boole)命名. 布尔型变量bool的取值只有false和t ...
- Bugku-CTF之看看源代码吧
Day13 看看源代码吧 http://123.206.87.240:8002/web4/ 本题要点:url解码 首先看到文本框,我们还是要习惯性输入一下
- koa2 中 cookie 存在的中文问题
koa2 中的 cookie 没办法直接设置中文,会报错 ‘ argument value is invalid ’ 解决办法: 先将它转成 ‘ base64 ’ 编码来存储 new Buffer( ...
- iOS开发 -------- AFNetworking实现简单的断点下载
一 实现如下效果 二 实现代码 // // ViewController.m // AFNetworking实现断点下载 // // Created by lovestarfish on 15/1 ...
- newcoder Tachibana Kanade Loves Probability(小数点后第k位)题解
题意:题目链接立华奏在学习初中数学的时候遇到了这样一道大水题: “设箱子内有 n 个球,其中给 m 个球打上标记,设一次摸球摸到每一个球的概率均等,求一次摸球摸到打标记的球的概率” “emmm...语 ...
- 【HNOI 2018】道路
Problem Description \(W\) 国的交通呈一棵树的形状.\(W\) 国一共有\(n - 1\)个城市和\(n\)个乡村,其中城市从\(1\)到\(n - 1\) 编号,乡村从\(1 ...
- robot framework学习五——AutoltLibrary库
安装中遇到的问题: 安装好了AutoItLibrary,但是导入到RIDE后,仍然红色显示 搜索了下解决办法,说要安装下autoit-v3-setup.exe https://www.autoitsc ...
- idea提示不区分大小写,解决方法
- 下载并配置jdk
①下载jdk安装到本机,这里是jdk8下载地址,请根据自己机子的环境进行下载 https://www.oracle.com/technetwork/java/javase/downloads/jdk8 ...