对word2vec的理解及资料整理
对word2vec的理解及资料整理
无他,在网上看到好多对word2vec的介绍,当然也有写的比较认真的,但是自己学习过程中还是看了好多才明白,这里按照自己整理梳理一下资料,形成提纲以便学习。
介绍较好的文章:
https://www.cnblogs.com/iloveai/p/word2vec.html
http://www.dataguru.cn/article-13488-1.html
http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
http://www.cnblogs.com/pinard/p/7160330.html
http://www.cnblogs.com/pinard/p/7243513.html
https://www.cnblogs.com/pinard/p/7249903.html
一、什么是Word2Vec?
简单地说就是讲单词word转换成向量vector来表示,通过词向量来表征语义信息。
在常见的自然语言处理系统中,单词的编码是任意的,因此无法向系统提供各个符号之间可能存在关系的有用信息,还会带来数据稀疏问题。使用向量对词进行表示可以克服其中的一些障碍。
2013年,Google团队发表了word2vec工具。
Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息,即通过一个嵌入空间(低维)使得语义上相似的单词在该空间内距离很近。
Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。
二、整体思路
先从宏观上介绍Word2Vec产生的整体思路。然后介绍Word2Vec使用的Skip-Gram模型,最后介绍为提高训练效率采用的两种优化方法:负采样(negative sampling)和层序softmax(hierarchical softmax)。
为解决传统的词表示是one-hot向量无法表征语义信息、数据稀疏、维度灾难等问题。出现了词的分布式表示(Distributional Representation),用一个连续的稠密向量去刻画一个word的特征。word2vec作为词分布式表示的一种,将词语表示为低维的向量实现词嵌入,在一个嵌入空间中进行表达。word2vec算法的背后是一个浅层神经网络。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型。很多人以为word2vec指的是一个算法或模型,这也是一种谬误。为了提高训练效率,word2vec使用了负采样(negative sampling)和层序softmax(hierarchical softmax)两种优化方法。
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,Skip-Gram是给定input word来预测上下文。而CBOW( Continuous Bagof-Words)是给定上下文,来预测input word。这两个模型均是用来进行预测的,直接目的并不是词向量。只是在训练这两个模型的过程中便会产生的参数矩阵——隐层的权重矩阵,便是Word2Vec中实际上就是我们试图去学习的“word vectors”
三、NLP中词的两种表示方法
1.利用one-hot向量表示词:
这种方法把每个词表示为一个很长的向量。词向量维度大小为整个词汇表的大小,对于每个具体的词汇表中的词,将对应的位置为1,其余位置为0,这个向量就代表了当前的词。
如:
“可爱”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 ...]
“面包”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 ...]
缺点:
- one-hot向量的维度等于词典的大小。这在动辄上万甚至百万词典的实际应用中,面临着巨大的维度灾难问题(the curse of dimensionality)
- 任意两个词之间都是孤立的,无法表示语义层面上词汇之间的相关信息,而这一点是致命的。
- 数据稀疏问题
2.分布式表示(distributed representation)和词嵌入(Word Embedding)
- 分布式表示(distributed representation):
观其伴,知其意。(Firth, J. R. 1957.11)
词的分布式表示基于这样一个“分布假说”:上下文相似的词,其语义也相似。
这一设想由Harris在1954年提出。Firth在1957年对分布假说进行了进一步阐述和明确:词的语义由其上下文决定。
可以直接刻画词与词之间的相似度,还可以建立一个从向量到概率的平滑函数模型,使得相似的词向量可以映射到相近的概率空间上。
有一种简单地方法,通过构建co-occurrence共现矩阵来定义word representation。基于Distributional Hypothesis构造一个word-context的矩阵,通过统计一个事先指定大小的窗口内的word共现次数,不仅可以刻画word的语义信息,还在一定程度上反应了word的语法结构信息。如在一篇文档中可能有如下矩阵:
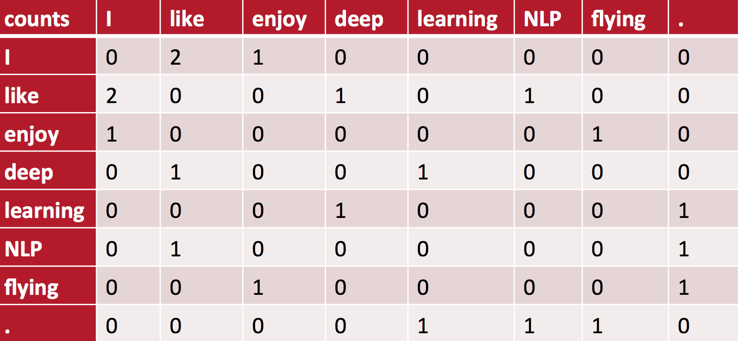
矩阵里的元素是列向量所代表的word出现在行向量所代表的word的上下文里的次数。(注意,我们并没有对句首或句尾的词做任何特殊的处理:比如增加一个S或E的标记Token作为句首或句尾的padding。
co-occurrence矩阵定义的词向量在一定程度上缓解了one-hot向量相似度为0的问题,但得到的词向量的维度等于词典的大小,没有解决数据稀疏性和维度灾难的问题。为了解决这些问题可以利用奇异值分解(SVD)进行降维,除此之外,还可以在对原始矩阵X的处理上,还有很多简单但很好用的Hacks。比如对原始矩阵中高频词的降频处理;带权重的统计窗口(距离越近的词对词义的贡献越大);用Pearson相关性系数替代简单的词频统计等。
概括起来,词的分布式表示主要可以分为三类:基于矩阵的分布表示、基于聚类的分布表示和基于神经网络的分布表示。
word2vec工具采用的便是基于神经网络的分布方法。它直接从原始的语料库中学习到低维词向量的表达。与直接从co-occurrence矩阵里提取词向量的SVD算法不同,word2vec模型背后的基本思想是对出现在上下文环境里的词进行预测(事实上,后面会看到,这种对上下文环境的预测本质上也是一种对co-occurrence统计特征的学习)。
- 词嵌入(Word Embedding):
Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。
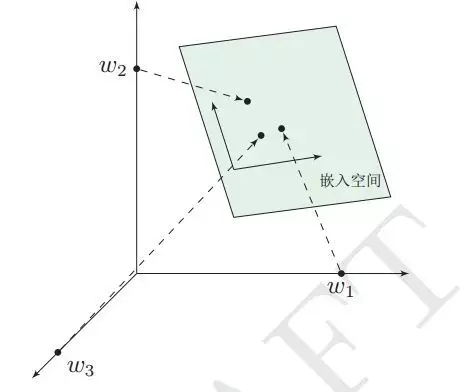
用词向量的方式表征词的语义信息,在这个嵌入空间中,语义上相似的单词距离较近。
- Word embedding的训练方法大致可以分为两类【参考】:
(1)无监督或弱监督的预训练 优点:不需要大量的人工标记样本就可以得到质量还不错的embedding向量 缺点:准确率有待提高 解决办法:得到预训练的embedding向量后,用少量人工标注的样本再去优化整个模型 典型代表:word2vec和auto-encoder (这里解释一下AutoEncoder,AutoEncoder也可以用于训练词向量,先将one hot映射成一个hidden state,再映射回原来的维度,令输入等于输出,取中间的hidden vector作为词向量,在不损耗原表达能力的前提下压缩向量维度,得到一个压缩的向量表达形式。)
(2)端对端(end to end)的有监督训练。 优点:学习到的embedding向量也往往更加准确 缺点:模型在结构上往往更加复杂 应用:通过一个embedding层和若干个卷积层连接而成的深度神经网络以实现对句子的情感分类,可以学习到语义更丰富的词向量表达。
word2vec不关心后续的应用场景,其学习到的是就是根据共现信息得到的单词的表达,用n-gram信息来监督,在不同的子task间都会有一定效果。而end2end训练的embedding其和具体子task的学习目标紧密相关,直接迁移到另一个子task的能力非常弱。
- 常用的word embedding分为dense(稠密)和sparse(稀疏)两种形式:
常见的sparse就比如 co-occurence(共现) 或者one-hot的形式;对sparse embedding进行一些降维运算比如SVD、PCA就可以得到dense。
下面将介绍由神经网络分布式表示和word2vec。
3.神经网络分布式表示和word2vec
注意:
- 无论是one-hot向量表示,还是分布式表示,其实都是词向量(word vector)。
- 词的神经网络分布式表示是词分布式表示方法的一种
- 神经网络语言模型是自然语言处理常用的模型,并不是只能用来训练词向量。而神经网络模型也有很多种, CBOW模型和Skip-gram模型只是其中两种。
- 神经网络语言模型并不直接用来表示词向量,词向量是模型在训练过程中得到到参数矩阵,因此词向量可以认为是神经网络训练语言模型的副产品。
(1) 基于神经网络的分布表示:
核心依然是上下文的表示以及上下文与目标词之间的关系的建模。2001年, Bengio 等人正式提出神经网络语言模型( Neural Network Language Model ,NNLM),从而奠定了包括word2vec在内后续研究word representation learning的基础。 NNLM模型的基本思想可以概括如下:
- 假定词表中的每一个word都对应着一个连续的特征向量;
- 假定一个连续平滑的概率模型,输入一段词向量的序列,可以输出这段序列的联合概率;
- 同时学习词向量的权重和概率模型里的参数。
通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
优点:
- 分布式表示具有非常强大的表征能力,比如n维向量每维k个值,可以表征k的n次方个概念。
- 解决了维度灾难问题,向量的维度由词汇表的大小降低到一个较小的空间维度下。
- 解决了数据稀疏问题,值得大小不再只是0和1构成,采用了一个紧凑平滑的向量空间来表示
---------
(2) word2vec
word2vec是谷歌提出的一种word embedding的NLP具体手段,它可以将所有的词向量化,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。word2vec主要包含两个模型跳字模型(skip-gram)和连续词袋模型(continuous bag of words,简称CBOW)。以及两种高效的训练方法负采样(negative sampling),层序softmax(hierarchical softmax)。
Skip-Gram模型:给定输入词来预测上下文,
CBOW模型:给定上下文来预测输入词

- Skip-Gram和CBOW模型的产生【参考】:
NNLM模型只能处理定长的序列。在03年的论文里,Bengio等人将模型能够一次处理的序列长度N提高到了5,虽然相比bigram和trigram已经是很大的提升,但依然缺少灵活性。
因此,Mikolov等人在2010年提出了一种RNNLM模型,用递归神经网络代替原始模型里的前向反馈神经网络,并将embedding层与RNN里的隐藏层合并,从而解决了变长序列的问题。
NNLM和NNLM的训练都太慢了。Mikolov注意到,原始的NNLM模型的训练其实可以拆分成两个步骤:用一个简单模型训练出连续的词向量;基于词向量的表达,训练一个连续的Ngram神经网络模型。 而NNLM模型的计算瓶颈主要是在第二步。如果我们只是想得到word的连续特征向量,是不是可以对第二步里的神经网络模型进行简化呢?
Mikolov在2013年对原始的NNLM模型做如下改造:(1)移除前向反馈神经网络中非线性的hidden layer,直接将中间层的embedding layer与输出层的softmax layer连接;(2)忽略上下文环境的序列信息:输入的所有词向量均汇总到同一个embedding layer;(3)将future words纳入上下文环境。得到CBoW模型,
反过来,也可以得到Skip-gram模型,Skip-gram模型的本质是计算输入word的input vector与目标word的output vector之间的余弦相似度,并进行softmax归一化。我们要学习的模型参数正是这两类词向量.
直接对词典里的V个词计算相似度并归一化,显然是一件极其耗时的impossible mission。为此,Mikolov引入了两种优化算法:层次Softmax(Hierarchical Softmax)和负采样(Negative Sampling)
比较常见的组合为 skip-gram+负采样方法。本文后面要讲的也是Skip-Gram模型和两种优化算法。
四、Skip-Gram 模型 【参考】
Word2Vec模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。Word2Vec的整个建模过程实际上与自编码器(auto-encoder)的思想很相似,即先基于训练数据构建一个神经网络,当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵——后面我们将会看到这些权重在Word2Vec中实际上就是我们试图去学习的“word vectors”。基于训练数据建模的过程,我们给它一个名字叫“Fake Task”,意味着建模并不是我们最终的目的。
The Fake Task
训练模型的真正目的是获得模型基于训练数据学得的隐层权重。为了得到这些权重,我们首先要构建一个完整的神经网络作为我们的“Fake Task”,后面再返回来看通过“Fake Task”我们如何间接地得到这些词向量。
接下来我们来看看如何训练我们的神经网络。假如我们有一个句子“The dog barked at the mailman”。
- 首先我们选句子中间的一个词作为我们的输入词,例如我们选取“dog”作为input word;
- 有了input word以后,我们再定义一个叫做skip_window的参数,它代表着我们从当前input word的一侧(左边或右边)选取词的数量。如果我们设置skip_window=2,那么我们最终获得窗口中的词(包括input word在内)就是['The', 'dog','barked', 'at']。skip_window=2代表着选取左input word左侧2个词和右侧2个词进入我们的窗口,所以整个窗口大小span=2x2=4。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word,当skip_window=2,num_skips=2时,我们将会得到两组 (input word, output word) 形式的训练数据,即 ('dog', 'barked'),('dog', 'the')。
- 神经网络基于这些训练数据将会输出一个概率分布,这个概率代表着我们的词典中的每个词是output word的可能性。这句话有点绕,我们来看个栗子。第二步中我们在设置skip_window和num_skips=2的情况下获得了两组训练数据。假如我们先拿一组数据 ('dog', 'barked') 来训练神经网络,那么模型通过学习这个训练样本,会告诉我们词汇表中每个单词是“barked”的概率大小。
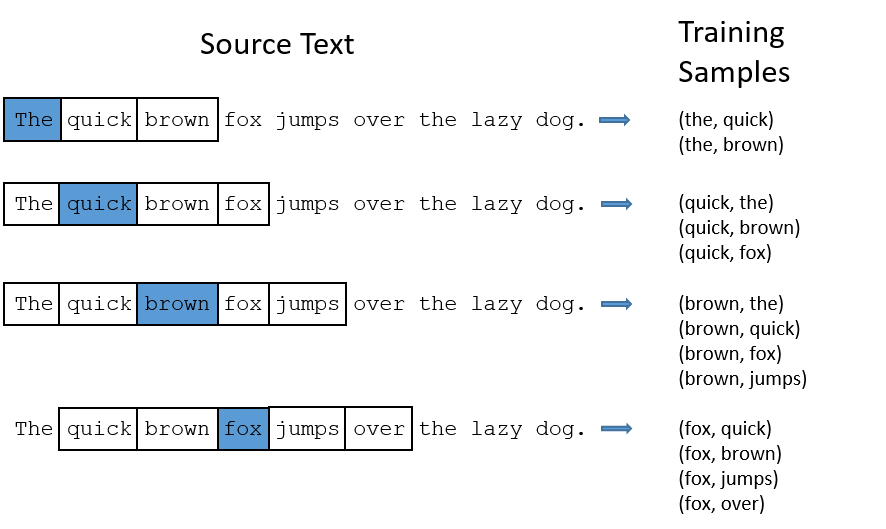
模型的输出概率代表着到我们词典中每个词有多大可能性跟input word同时出现。举个栗子,如果我们向神经网络模型中输入一个单词“Soviet“,那么最终模型的输出概率中,像“Union”, ”Russia“这种相关词的概率将远高于像”watermelon“,”kangaroo“非相关词的概率。因为”Union“,”Russia“在文本中更大可能在”Soviet“的窗口中出现。我们将通过给神经网络输入文本中成对的单词来训练它完成上面所说的概率计算。下面的图中给出了一些我们的训练样本的例子。我们选定句子“The quick brown fox jumps over lazy dog”,设定我们的窗口大小为2(window_size=2),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表input word,方框内代表位于窗口内的单词。
The quick brown fox jumps over the lazy dog
我们的模型将会从每对单词出现的次数中习得统计结果。例如,我们的神经网络可能会得到更多类似(“Soviet“,”Union“)这样的训练样本对,而对于(”Soviet“,”Sasquatch“)这样的组合却看到的很少。因此,当我们的模型完成训练后,给定一个单词”Soviet“作为输入,输出的结果中”Union“或者”Russia“要比”Sasquatch“被赋予更高的概率。
- 注意:构建的神经网络Fake Task作用是根据input word预测output word。只是在该神经网络构建过程中会产生隐层权重,该隐层权重即是我们要找的词向量。
模型细节
Skip-Gram模型使用一个浅层的神经网络,用一个只具有一个隐藏层的神经网络来学习词嵌入。网络首先会随机地初始化它的权重,然后使用单词来预测它的语境,在最小化它所犯错误的训练过程中去迭代调整这些权重。在一个比较成功的训练过程之后,能够通过网络权重矩阵和单词的 one-hot 向量的乘积来得到每一个单词的词向量。
我们如何来表示这些单词呢?首先,我们都知道神经网络只能接受数值输入,我们不可能把一个单词字符串作为输入,因此我们得想个办法来表示这些单词。最常用的办法就是基于训练文档来构建我们自己的词汇表(vocabulary)再对单词进行one-hot编码。
假设从我们的训练文档中抽取出10000个唯一不重复的单词组成词汇表。我们对这10000个单词进行one-hot编码,得到的每个单词都是一个10000维的向量,向量每个维度的值只有0或者1,假如单词ants在词汇表中的出现位置为第3个,那么ants的向量就是一个第三维度取值为1,其他维都为0的10000维的向量(ants=[0, 0, 1, 0, ..., 0])
还是上面的例子,“The dog barked at the mailman”,那么我们基于这个句子,可以构建一个大小为5的词汇表(忽略大小写和标点符号):("the", "dog", "barked", "at", "mailman"),我们对这个词汇表的单词进行编号0-4。那么”dog“就可以被表示为一个5维向量[0, 1, 0, 0, 0]。
模型的输入如果为一个10000维的向量,那么输出也是一个10000维度(词汇表的大小)的向量,它包含了10000个概率,每一个概率代表着当前词是输入样本中output word的概率大小。
下图是我们神经网络的结构:
隐层没有使用任何激活函数,但是输出层使用了sotfmax。
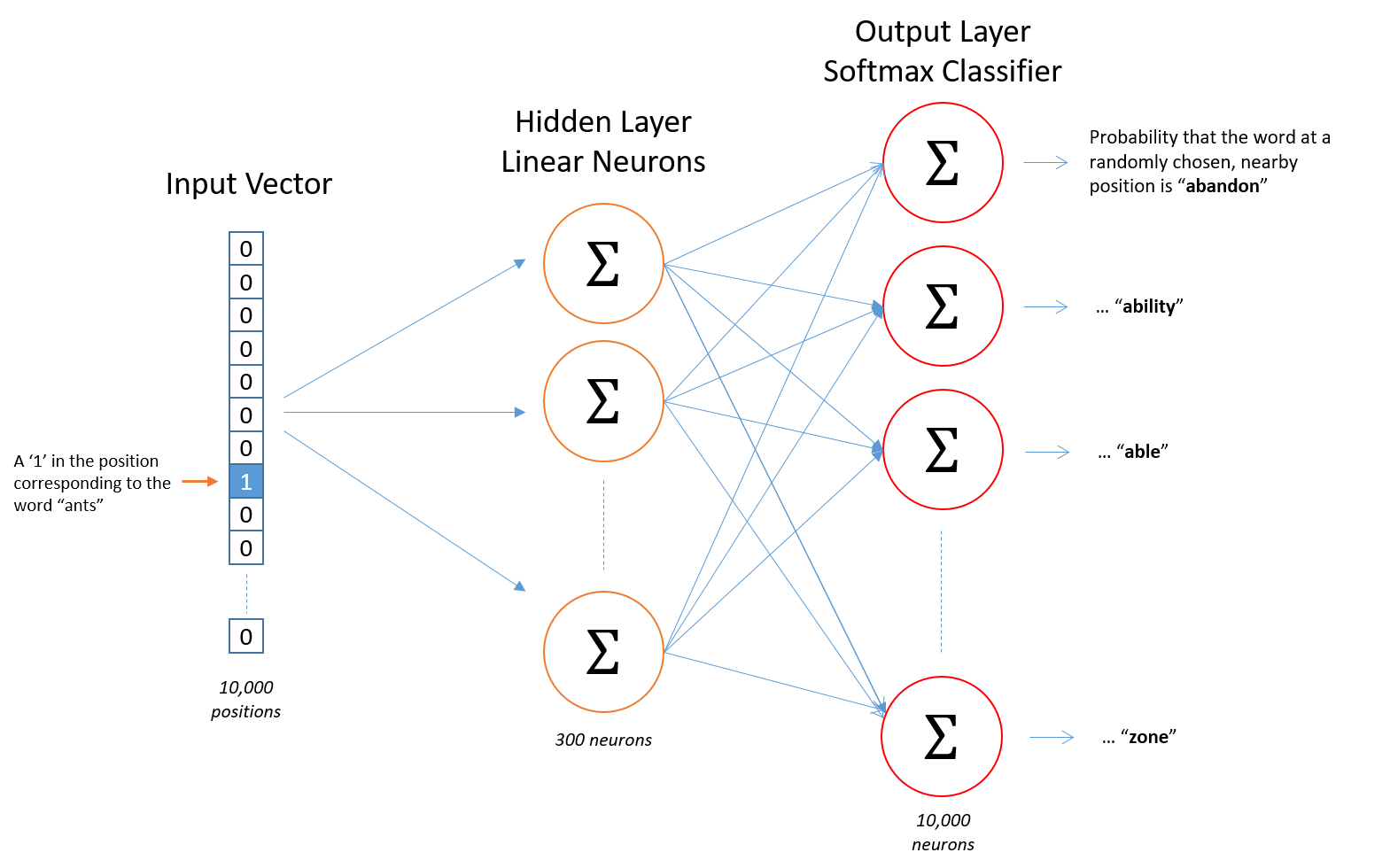
我们基于成对的单词来对神经网络进行训练,训练样本是 ( input word, output word ) 这样的单词对,input word和output word都是one-hot编码的向量。最终模型的输出是一个概率分布。
隐层
说完单词的编码和训练样本的选取,我们来看下我们的隐层。如果我们现在想用300个特征来表示一个单词(即每个词可以被表示为300维的向量)。那么隐层的权重矩阵应该为10000行,300列(隐层有300个结点)。
Google在最新发布的基于Google news数据集训练的模型中使用的就是300个特征的词向量。词向量的维度是一个可以调节的超参数(在Python的gensim包中封装的Word2Vec接口默认的词向量大小为100, window_size为5)。
看下面的图片,左右两张图分别从不同角度代表了输入层-隐层的权重矩阵。左图中每一列代表一个10000维的词向量和隐层单个神经元连接的权重向量。从右边的图来看,每一行实际上代表了每个单词的词向量。
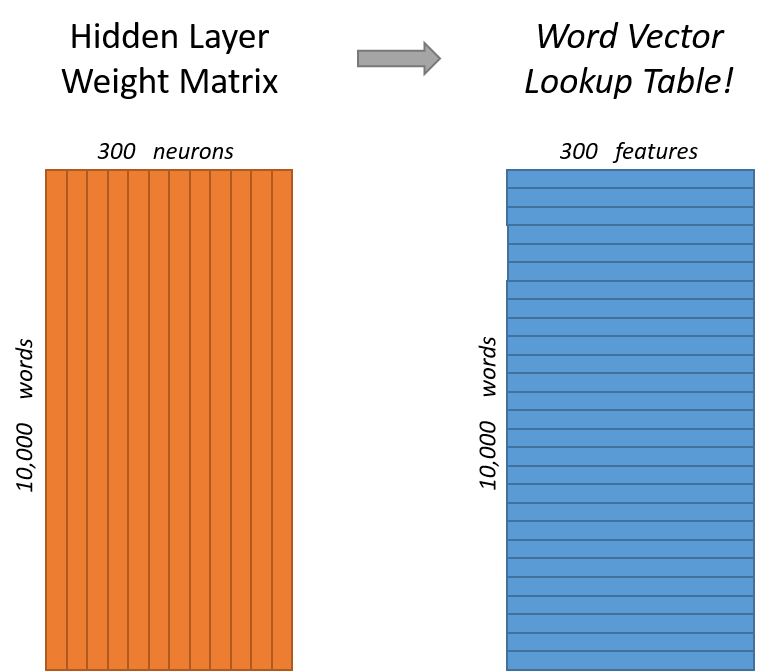
所以我们最终的目标就是学习这个隐层的权重矩阵。
我们现在回来接着通过模型的定义来训练我们的这个模型。
上面我们提到,input word和output word都会被我们进行one-hot编码。仔细想一下,我们的输入被one-hot编码以后大多数维度上都是0(实际上仅有一个位置为1),所以这个向量相当稀疏,那么会造成什么结果呢。如果我们将一个1 x 10000的向量和10000 x 300的矩阵相乘,它会消耗相当大的计算资源,为了高效计算,它仅仅会选择矩阵中对应的向量中维度值为1的索引行(这句话很绕),看图就明白。

我们来看一下上图中的矩阵运算,左边分别是1 x 5和5 x 3的矩阵,结果应该是1 x 3的矩阵,按照矩阵乘法的规则,结果的第一行第一列元素为0 x 17 + 0 x 23 + 0 x 4 + 1 x 10 + 0 x 11 = 10,同理可得其余两个元素为12,19。如果10000个维度的矩阵采用这样的计算方式是十分低效的。
为了有效地进行计算,这种稀疏状态下不会进行矩阵乘法计算,可以看到矩阵的计算的结果实际上是矩阵对应的向量中值为1的索引,上面的例子中,左边向量中取值为1的对应维度为3(下标从0开始),那么计算结果就是矩阵的第3行(下标从0开始)—— [10, 12, 19],这样模型中的隐层权重矩阵便成了一个”查找表“(lookup table),进行矩阵计算时,直接去查输入向量中取值为1的维度下对应的那些权重值。隐层的输出就是每个输入单词的“嵌入词向量”。
输出层
经过神经网络隐层的计算,ants这个词会从一个1 x 10000的向量变成1 x 300的向量,再被输入到输出层。输出层是一个softmax回归分类器,它的每个结点将会输出一个0-1之间的值(概率),这些所有输出层神经元结点的概率之和为1。
下面是一个例子,训练样本为 (input word: “ants”, output word: “car”) 的计算示意图。
上图展示了输入词为ants,计算输出词为car的概率。
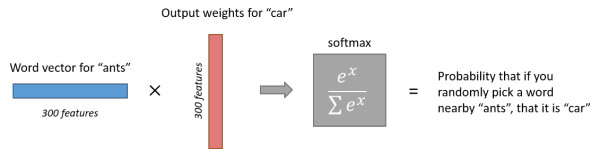
直觉上的理解
如果两个不同的单词有着非常相似的“上下文”(也就是窗口单词很相似,比如“Kitty climbed the tree”和“Cat climbed the tree”),那么通过我们的模型训练,这两个单词的嵌入向量将非常相似。
那么两个单词拥有相似的“上下文”到底是什么含义呢?比如对于同义词“intelligent”和“smart”,我们觉得这两个单词应该拥有相同的“上下文”。而例如”engine“和”transmission“这样相关的词语,可能也拥有着相似的上下文。
实际上,这种方法实际上也可以帮助你进行词干化(stemming),例如,神经网络对”ant“和”ants”两个单词会习得相似的词向量。
词干化(stemming)就是去除词缀得到词根的过程。
模型训练【参考】
将输入层到隐层的权重矩阵、隐层到输出层的举证分别写成矩阵。神经网络图就是下面的样子:
隐藏层中有N个神经元,也就是说输入词被表示为N维的一个向量。隐藏层中的权重矩阵大小为V*N,一个V维的one-hot输入词通过权重矩阵映射到了一个V维的向量,而这个向量正是所谓的word vector,对应于上图中右边的每一行。

如上图所示,网络的输入是一个单词,V维的one-hot向量,最终输出的结果也是一个V维的向量,其中的值表示对应的词作为输入词的上下文的概率,也就是说最后输出的是输入词的邻近词的概率分布。这里使用的是softmax回归,最终输出的结果所有概率之和为1。
那么如何来训练Skip-Gram模型呢?通过逐一选定句子中的单词作为输入词,将与之相邻的词提取出来,进行学习。图中的窗口大小为2,也即每次向前和向后各看2个词(如果存在的话)。
五、两种加速方法——负采样(negative sampling)和层序softmax(hierarchical softmax)
在第一部分讲解完成后,我们会发现Word2Vec模型是一个超级大的神经网络(权重矩阵规模非常大)。
举个栗子,我们拥有10000个单词的词汇表,我们如果想嵌入300维的词向量,那么我们的输入-隐层权重矩阵和隐层-输出层的权重矩阵都会有 10000 x 300 = 300万个权重,在如此庞大的神经网络中进行梯度下降是相当慢的。更糟糕的是,你需要大量的训练数据来调整这些权重并且避免过拟合。百万数量级的权重矩阵和亿万数量级的训练样本意味着训练这个模型将会是个灾难(太凶残了)。
Word2Vec 的作者在它的第二篇论文中强调了这些问题,下面是作者在第二篇论文中的三个创新:
- 将常见的单词组合(word pairs)或者词组作为单个“words”来处理。
- 对高频次单词进行抽样来减少训练样本的个数。
- 对优化目标采用“negative sampling”方法,这样每个训练样本的训练只会更新一小部分的模型权重,从而降低计算负担。
下面主要介绍两种方法优化训练过程。
1.层序softmax(Hierarchical Softmax)【基于Hierarchical Softmax的模型】
层序softmax也是解决这个问题的一种方法。
大家都知道哈夫曼树是带权路径最短的树,一般神经网络语言模型在预测的时候,输出的是预测目标词的概率(每一次预测都要基于全部的数据集进行计算,很大的时间开销)。
Hierarchical Softmax是一种对输出层进行优化的策略,输出层从原始模型的利用softmax计算概率值改为了利用Huffman树计算概率值。一开始我们可以用以词表中的全部词作为叶子节点,词频作为节点的权,构建Huffman树,作为输出。从根节点出发,到达指定叶子节点的路径是的。Hierarchical Softmax正是利用这条路径来计算指定词的概率,而非用softmax来计算。
即Hierarchical Softmax:把 N 分类问题变成 log(N)次二分类
Hierarchical Softmax可以参考基于Negative Sampling的模型
2.负采样(negative sampling)【Word2Vec Tutorial Part 2 - Negative Sampling】
负采样(negative sampling)解决了这个问题,它是用来提高训练速度并且改善所得到词向量的质量的一种方法。不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。至于具体的细节我在这里就不在介绍了。关于负采样介绍参考基于Negative Sampling的模型,Word2Vec Tutorial Part 2 - Negative Sampling,一文详解 Word2vec 之 Skip-Gram 模型(训练篇)
负采样可以参考基于Negative Sampling的模型
六、Word2Vec的应用
word2vec词向量可以较好地表达不同词之间的相似和类比关系。如:v("King")−v("Man")+v("Woman")=v("Queen")
word2vec是其他自然语言处理的基础,将词用词向量表示后,可以进行其他其他任务,如推荐系统等。
七、利用TensorFlow实现Word2Vec
关于Word2Vec的详细介绍终于结束了,相信看完本文章你会理解Word2Vec的来龙去脉。下面读者可以查看下面的章节用TensorFlow来实现Word2Vec。
参考文献
CBOW模型学习https://iksinc.online/tag/continuous-bag-of-words-cbow/
- https://www.cnblogs.com/micrari/p/9115426.html
- http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
- http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/
- https://www.jianshu.com/p/a2e6a487b385
- https://www.cnblogs.com/baiting/p/5840017.html
- https://blog.csdn.net/yu5064/article/details/79601683
- https://www.cnblogs.com/iloveai/p/word2vec.html
- https://www.cnblogs.com/iloveai/p/cs224d-lecture2-note.html
对word2vec的理解及资料整理的更多相关文章
- CSS3 float深入理解浮动资料整理
CSS浮动(float,clear)通俗讲解 CSS 浮动 CSS float浮动的深入研究.详解及拓展(一) CSS float浮动的深入研究.详解及拓展(二) 1.浮动实现图文环绕(理解难点) 浮 ...
- c语言宏定义#define的理解与资料整理
1. 利用define来定义 数值宏常量 #define 宏定义是个演技非常高超的替身演员,但也会经常耍大牌的,所以我们用它要慎之又慎.它可以出现在代码的任何地方,从本行宏定义开始,以后的代码就就都认 ...
- [转]c语言宏定义#define的理解与资料整理
原文地址:http://www.cnblogs.com/haore147/p/3646934.html 1. 利用define来定义 数值宏常量 #define 宏定义是个演技非常高超的替身演员,但也 ...
- word2vec剖析,资料整理备存
声明:word2vec剖析,资料整理备存,以下资料均为转载,膜拜大神,仅作学术交流之用. word2vec是google最新发布的深度学习工具,它利用神经网络将单词映射到低维连续实数空间,又称为单词嵌 ...
- 转:基于IOS上MDM技术相关资料整理及汇总
一.MDM相关知识: MDM (Mobile Device Management ),即移动设备管理.在21世纪的今天,数据是企业宝贵的资产,安全问题更是重中之重,在移动互联网时代,员工个人的设备接入 ...
- 基于IOS上MDM技术相关资料整理及汇总
(转自:http://www.mbaike.net/special/1542.html) 一.MDM相关知识:MDM (Mobile Device Management ),即移动设备管理.在21世纪 ...
- POI3的资料整理
转自http://aman.cao.blog.163.com/blog/static/32951336201010823557408/ POI3的资料整理一.POI简介 Jakarta POI 是ap ...
- Java资料整理
Java资料整理 原创 2017年08月25日 17:20:44 14211 1.LocalThread的应用场景,数据传输适合用LocalThread么 2.linux的基本命令 软链接.更 ...
- F4NNIU 的 Docker 学习资料整理
F4NNIU 的 Docker 学习资料整理 Docker 介绍 以下来自 Wikipedia Docker是一个开放源代码软件项目,让应用程序部署在软件货柜下的工作可以自动化进行,借此在Linux操 ...
随机推荐
- centos7的ssh服务连接
---恢复内容开始--- SSH 为 Secure Shell 的缩写,由 IETF 的网络小组(Network Working Group)所制定:SSH 为建立在应用层基础上的安全协议.SSH 是 ...
- python网络编程初级
网络编程的专利权应该属于Unix,各个平台(如windows.Linux等).各门语言(C.C++.Python.Java等)所实现的符合自身特性的语法都大同小异.在我看来,懂得了Unix的socke ...
- [宏]preempt_disable
//include/linux/preempt.h #ifdef CONFIG_PREEMPT_COUNT //如果内核支持抢占 do { \ inc_preempt_count(); \ barri ...
- 修改idea打开新窗口的默认配置
使用idea开发maven项目时,发现使用新窗口创建一个项目时,例如file-settings的maven库配置都是用的用户下的maven库,如何配置一个全局的maven配置呢,操作如下: File- ...
- 【OSX】build AOSP 2.3.7时的build error解决
原始的error log: ============================================ PLATFORM_VERSION_CODENAME=REL PLATFORM_VE ...
- 获取 BaiduMapSDKDemo SHA1 签名
用 Android Studio 1.5 运行 BaiduMapsApiASDemo 时,显示 key 验证出错. 原因在于用 keytool -list -keystore debug.keysto ...
- 修改Spring Boot默认的上下文
前言 默认情况下,Spring Boot使用的服务上下文为"/",我们可以通过"http://localhost:PORT/" 直接诶访问应用: 但是在生产环境 ...
- Eureka安全认证
Eureka 服务加入安全认证只需要在之前的服务中增加三处步骤即可: 1.在Eureka Server中加入spring-boot-starter-security依赖 <dependencie ...
- MRTG在Windows平台的安装及使用
MRTG (Multi Router Traffic Grapher)是一款监控网络流量负载的免费软件,目前利用MRTG已经开发出了各式各样的统计系统: 1.系统资源负载统计,例如:磁盘空间.CPU负 ...
- 一直性hash解决扩容后的hash算法不用变
转自: http://blog.codinglabs.org/articles/consistent-hashing.html 摘要 本文将会从实际应用场景出发,介绍一致性哈希算法(Consisten ...