xtrabackup的执行过程
XtraBackup的执行过程
执行全量备份过程中对数据库进行的操作
https://www.cnblogs.com/digdeep/p/4946230.html
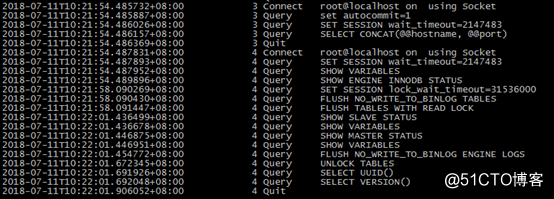
可以看出执行xtrabackup进行全量备份总共有两个线程
SET SESSION lock_wait_timeout=31536000的作用是:因为如果某个会话中使用了lock tables语句对某表加了锁,或者某个会话在进行DDL,又或者某个会话正在进行一个大的事务,那么flush tables和flush tables with read lock会被阻塞。设置锁等待时间是为了防止innobackup执行获取全局锁超时而导致备份失败退出。FLUSH NO_WRITE_TO_BINLOG TABLES的作用是:关闭所有打开的表,强制关闭所有正在使用的表,并刷新查询缓存和预准备语句缓存。还会从查询缓存中删除查询结果。默认情况下flush语句会写入binlog,这里使用no_write_to_binlog禁止记录。查看Binlog发现,binlog内真的啥都没记录。FLUSH TABLES WITH READ LOCK的作用是:关闭所有被打开的表,并且使用全局锁锁住所有库的所有表(锁住之后只能被select,不能做其他操作)。当我们备份或者需要数据库的一致状态时,这个是最高效的方式。如果有事务存在,那么该事务提交时会hang住,不会回滚。但是不会阻止数据库往log tables(比如general_log和slow log)里插入数据。FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS的作用是:将innodb层的重做日志持久化到磁盘,然后再进行拷贝。说白了就是在所有的事务表和非事务表备份完成,获取全局读锁,且使用了show master status语句获取了binlog的pos之后,执行刷新redo log buffer中的日志到磁盘中,然后redo log copy线程拷贝这最后的redo log日志数据。为啥这样数据就是完整的?因为获取了全局读锁到unlock tables释放之前,不会再有请求进来。UNLOCK TABLES的作用是:释放全局读锁。在flush tables with read lock和unlock tables之间,执行了下面操作
a、 拷贝所有非事务表,如系统MyISAM表
b、 将redo log buffer落盘
c、 拷贝redo logXtraBackup备份全过程
1、连接mysql进行版本检查。
2、通过读取配置文件,获取数据和日志文件位置。
3、扫描监控读取redo log,有新的redo log就拷贝到xtrabackup的logfile中。
4、拷贝共享表空间文件,innodb的.ibd数据文件
5、关闭所有打开的表,获取全局读锁,开始拷贝非Innodb的表和文件Starting to backup non-InnoDB tables and files
6、将redo log落盘,拷贝到xtrabackup的logfile中。
7、释放全局读锁。
8、记录binlog信息等,备份结束。对全备进行恢复时,并没有对数据库进行任何操作,全量日志中无任何记录- 增量备份只针对innodb和全量备份的不同之处在于:
A、在对增量innodb表等进行拷贝前,会统计变化的页儿的数量
SELECT 'INNODB_CHANGED_PAGES', COUNT(*) FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME LIKE 'INNODB_CHANGED_PAGES'
B、使用全扫描进行增备,备份的共享表空间和ibd文件等都是增量,后缀为.delta
- ================
- 6. innobackupex 选项优化/最佳实践6.1 优化FTWRL锁:在备份非innodb数据库时,会使用:flush tables with read lock 全局锁锁住整个数据库。如果数据库中有一个长查询在运行,那么FTWRL就不能获得,会被阻塞,进而阻塞所有的DML操作。此时即使我们kill掉FTWRL全局锁也是无法从阻塞中恢复出来的。另外在我们成功的获得了FTWRL全局锁之后,在copy非事务因为的文件的过程中,整个数据库也是被锁住的。所以我们应该让FTWRL的过程尽量的短。(在copy非事务引擎数据的文件时,会阻塞innodb事务引擎。当然也会阻塞所有其他非事务引擎。)1> 防止阻塞:innobackupex 提供了多个选项来避免发生阻塞:--ftwrl-wait-timeout=# 替换 --lock-wait-timeoutThis option specifies time in seconds that innobackupexshould wait for queries that would block FTWRL beforerunning it. If there are still such queries when thetimeout expires, innobackupex terminates with an error.Default is 0, in which case innobackupex does not waitfor queries to complete and starts FTWRL immediately.--ftwrl-wait-threshold=# 替换 --lock-wait-thresholdThis option specifies the query run time threshold whichis used by innobackupex to detect long-running querieswith a non-zero value of --ftwrl-wait-timeout. FTWRL isnot started until such long-running queries exist. Thisoption has no effect if --ftwrl-wait-timeout is 0.Default value is 60 seconds.--lock-wait-timeout=60 该选项表示:我们在FTWRL时,如果有长查询,那么我们可以最多等待60S的时间,如果60秒之内长查询执行完了,我们就可以成功执行FTWRL了,如果60秒之内没有执行完,那么就直接报错退出,放弃。默认值为0--lock-wait-threshold=10 该选项表示运行了多久的时间的sql当做长查询;对于长查询最多再等待 --lock-wait-timeout 秒。--kill-long-queries-timeout=10 该选项表示发出FTWRL之后,再等待多时秒,如果还有长查询,那么就将其kill掉。默认为0,not to kill.--kill-long-query-type={all|select} 该选项表示我们仅仅kill select语句,还是kill所有其他的类型的长sql语句。这几个选项,我们没有必要都是有,一般仅仅使用 --lock-wait-timeout=60 就行了。注意 --lock-* 和 --kill-* 选项的不同,一个是等待多时秒再来执行FTWRL,如果还是不能成功执行就报错退出;一个是已经执行了FTWRL,超时就进行kill。2> 缩短FTWRL全局锁的时间:--rsync 使用该选项来缩短备份非事务引擎表的锁定时间,如果需要备份的数据库和表数量很多时,可以加快速度。--rsync Uses the rsync utility to optimize local file transfers.When this option is specified, innobackupex uses rsync tocopy all non-InnoDB files instead of spawning a separatecp for each file, which can be much faster for serverswith a large number of databases or tables. This optioncannot be used together with --stream.3> 并行优化:--parallel=# 在备份阶段,压缩/解压阶段,加密/解密阶段,--apply-log,--copy-back 阶段都可以并行On backup, this option specifies the number of threadsthe xtrabackup child process should use to back up filesconcurrently. The option accepts an integer argument. Itis passed directly to xtrabackup's --parallel option. Seethe xtrabackup documentation for details.4> 内存优化:--use-memory=# 在crash recovery 阶段,也就是 --apply-log 阶段使用该选项This option accepts a string argument that specifies theamount of memory in bytes for xtrabackup to use for crashrecovery while preparing a backup. Multiples aresupported providing the unit (e.g. 1MB, 1GB). It is usedonly with the option --apply-log. It is passed directlyto xtrabackup's --use-memory option. See the xtrabackupdocumentation for details.3> 备份slave:--safe-slave-backupStop slave SQL thread and wait to start backup untilSlave_open_temp_tables in "SHOW STATUS" is zero. If thereare no open temporary tables, the backup will take place,otherwise the SQL thread will be started and stoppeduntil there are no open temporary tables. The backup willfail if Slave_open_temp_tables does not become zero after--safe-slave-backup-timeout seconds. The slave SQL threadwill be restarted when the backup finishes.--safe-slave-backup-timeout=#How many seconds --safe-slave-backup should wait forSlave_open_temp_tables to become zero. (default 300)--slave-info This option is useful when backing up a replication slaveserver. It prints the binary log position and name of themaster server. It also writes this information to the"xtrabackup_slave_info" file as a "CHANGE MASTER"command. A new slave for this master can be set up bystarting a slave server on this backup and issuing a"CHANGE MASTER" command with the binary log positionsaved in the "xtrabackup_slave_info" file.
7. 备份原理:
1)innobackupex 是perl写的脚本,它调用xtrabackup来备份innodb数据库。而xtrabackup是C语言写的程序,它调用了innodb的函数库和mysql客户端的函数库。innodb函数库提供了向数据文件应用的redo log的功能,而mysql客户端函数库提供了解析命令行参数的功能。innobackupex备份innodb数据库的功能,都是通过调用 xtrabackup --backup和xtrabackup --prepare来完成的。我们没有必要直接使用xtrabackup来备份,通过innobackupex更方便。xtrabakup 通过跳转到datadir目录,然后通过两个线程来完成备份过程:1> log-copy thread: 备份开始时,该后台线程一直监控redo log(每秒check一次redo log),将redo log的修改复制到备份之后的文件 xtrabackup_logfile 中。如果redo log生成极快时,有可能log-copy线程跟不上redo log的产生速度,那么在redo log文件切换进行覆盖时,xtrabakcup会报错。2> data-file-copy thread: 前后有一个复制data file的线程,注意这里并不是简单的复制,而是调用了innodb函数库,像innodb数据库那样打开数据文件,进行读取,然后每次复制一个page,然后对page进行验证,如果验证错误,会最多重复十次。当数据文件复制完成时,xtrabackup 停止log-copy 线程,并建立一个文件 xtrabackup_checkpoints记录备份的类型,开始时的lsn和结束时的lsn等信息。而备份生成的 xtrabackup_binlog_info 文件则含义备份完成时对应的binlog的position信息,类似于:mysql-bin.000002 120在备份开始时记录下LSN,然后一个线程复制数据文件,一个线程监控redo log,复制在备份过程中新产生的redo log。虽然我们的到的数据文件显然不是一致性的,但是利用innodb的crash-recovery功能,应用备份过程中产生的redo log文件,就能得到备份完成时那一刻对应的一致性的数据。注意复制数据文件分成了两个过程:一个是复制innodb事务引擎的数据文件,是不需要持有锁的;另一个是复制非事务引擎的数据文件和table的定义文件.frm,复制这些文件时,是需要先通过FTWRL,然后在进行复制的,所以会导致整个数据库被阻塞。增量备份时,是通过对表进行全扫描,比较LSN,如果该page的LSN大于上一次别分时的LSN,那么就将该page复制到table_name.ibd.delta文件中。回复时.delta会和redo log应用到全备是的数据文件中。增量备份在恢复时,除了最后一次增量备份文件之外,其它的增量备份在应用时,只能前滚,不能执行回滚操作,因为没有提交的事务,可能在下一个增量备份中进行了提交,如果你在上一个增量备份时回滚了,那么下一个增量备份应用时,显然就报错了,因为他无法提交事务,该事务以及被回滚了。 - =========
1. 设置超时时间
XtraBackup设置一个超时时间,避免无限期的等待。Xtrabackup提供了一下参数实现该功能:
--lock-wait-timeout=SECONDS :一旦Flush table with read lock被阻塞超过预定时间,则XtraBackup出错返回退出,该值默认为0,也就是说一旦阻塞,立即返回失败。
--lock-wait-query-type=all|update :该参数允许用户指定,哪类的SQL语句是需要Flush table with read lock等待的,同时用户可以通过–lock-wait-threshold=SECONDS设置等待的时间,如果不在query-type指定的类型范围内或者超过了wait-threshold指定的时间,XtraBackup均返回错误。如果指定update类型,则UPDATE/ALTER/REPLACE /INSERT 均会等待,ALL表示所有的SQL语句。
2. kill其他阻塞线程
Kill掉所有阻塞Flush table with read lock的线程:
--kill-long-queries-timeout=SECONDS :参数允许用户指定了超过该阈值时间的查询会被Kill,同时也允许用户指定Kill SQL语句的类型。
--kill-long-query-type=all|select :默认值为ALL,如果选择Select,只有Select语句会被Kill,如果Flush table with read lock是被Update语句阻塞,则XtraBackup不会处理。
数据库运维人员在备份数据库时,应选择正确的XtraBackup版本规避该问题。同时,个人在使用XtraBackup在Slave做备份时,还碰到跟SQL线程产生死锁的情况。MariaDB并行复制,死锁信息如下:
xtrabackup的执行过程的更多相关文章
- ASP.NET Web API 过滤器创建、执行过程(二)
ASP.NET Web API 过滤器创建.执行过程(二) 前言 前面一篇中讲解了过滤器执行之前的创建,通过实现IFilterProvider注册到当前的HttpConfiguration里的服务容器 ...
- ASP.NET Web API 过滤器创建、执行过程(一)
ASP.NET Web API 过滤器创建.执行过程(一) 前言 在上一篇中我们讲到控制器的执行过程系列,这个系列要搁置一段时间了,因为在控制器执行的过程中包含的信息都是要单独的用一个系列来描述的,就 ...
- ASP.NET Web API 控制器执行过程(一)
ASP.NET Web API 控制器执行过程(一) 前言 前面两篇讲解了控制器的创建过程,只是从框架源码的角度去简单的了解,在控制器创建过后所执行的过程也是尤为重要的,本篇就来简单的说明一下控制器在 ...
- Struts2拦截器的执行过程浅析
在学习Struts2的过程中对拦截器和动作类的执行过程一度陷入误区,特别读了一下Struts2的源码,将自己的收获分享给正在困惑的童鞋... 开始先上图: 从Struts2的图可以看出当浏览器发出请求 ...
- 通过源码了解ASP.NET MVC 几种Filter的执行过程
一.前言 之前也阅读过MVC的源码,并了解过各个模块的运行原理和执行过程,但都没有形成文章(所以也忘得特别快),总感觉分析源码是大神的工作,而且很多人觉得平时根本不需要知道这些,会用就行了.其实阅读源 ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- 高程(4):执行环境、作用域、上下文执行过程、垃圾收集、try...catch...
高程三 4.2.4.3 一.执行环境 1.全局执行环境是最外层的执行环境. 2.每个函数都有自己的执行环境,执行函数时,函数环境就会被推入一个当前环境栈中,执行完毕,栈将其环境弹出,把控制器返回给之前 ...
- saltstack命令执行过程
saltstack命令执行过程 具体步骤如下 Salt stack的Master与Minion之间通过ZeroMq进行消息传递,使用了ZeroMq的发布-订阅模式,连接方式包括tcp,ipc salt ...
- Web APi之过滤器执行过程原理解析【二】(十一)
前言 上一节我们详细讲解了过滤器的创建过程以及粗略的介绍了五种过滤器,用此五种过滤器对实现对执行Action方法各个时期的拦截非常重要.这一节我们简单将讲述在Action方法上.控制器上.全局上以及授 ...
随机推荐
- Ruby on Rails Tutorial 第一章笔记
搭建开发环境 作者介绍了 Cloud9\ Coding.net 这样的云端开发环境 安装 Rails 1. 新建 rails 应用 首先,调用 rails new 命令创建一个新的 Rails 应用, ...
- PHP+ffmpeg+nginx的配置实现视频转码
最近项目中需要实现上传视频过程中自动转码MP4格式的功能,想到了用FFmpeg来实现它,但从来没有操作过,查阅了很多资料,遇到了好多问题,现在终于安装成功,觉得应该写下来与人分享一下,以免有人遇到和我 ...
- <airsim文档学习> Street View Image, Pose, and 3D Cities Dataset
原文地址: https://github.com/amir32002/3D_Street_View 说明:个人学习笔记,翻译整理自github/airsim. 简介 该存储库共享包含6DOF相机姿态 ...
- match和search的区别
正则表达式帮助你方便的检查一个字符串是否与某种模式匹配. re模块使Python语言拥有全部的正则表达式功能. re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,mat ...
- XenServer7.6命令行导出导入虚拟机(迁移)
一:命令行方法导出虚拟机(先关闭虚拟机) 1.1:打印虚拟机列表 xe vm-list uuid ( RO) : 43dfac04-515e-7769-b2d2-444d4b7cb198 name-l ...
- ES6新特性,对象的快速创建
//es6对象快速赋值 //es5对象赋值 var name="xiaoming"; var age=18 var person={ name:name, age:age } co ...
- layui布局器网站工具
http://layuiout.magicalcoder.com/magicaldrag-admin/drag
- talk with gao about qssp
- json&pickle序列化和软件开发规范
json和pickle 用于序列化的两个模块 json 用于字符串和python数据类型间进行转换,json只支持列表,字典这样简单的数据类型 但是它不支持类,函数这样的数据类型转换 pickle ...
- js解密
import base64 src_code = 'Ly93eDIuc2luYWltZy5jbi9tdzYwMC8wMDc2QlNTNWx5MWcxaWlpOHNybThqMzB1MDE5NWRyMS ...