二叉树、B树、B+树、B*树、LSM树
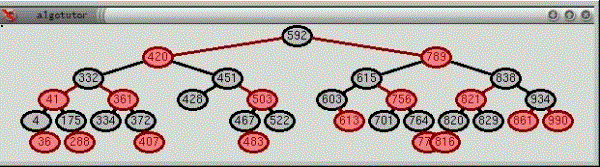
B+树
数据的读取速度因素
由于传统的机械磁盘具有快速顺序读写、慢速随机读写的访问特性,这个特性对磁盘存储结构和算法的选择影响甚大。
为了改善数据访问特性,文件系统或数据库系统通常会对数据排序后存储,加快数据检索速度,这就需要保证数据在不断更新、插入、删除后依然有序,传统关系数据库的做法是使用B+树,如图所示。
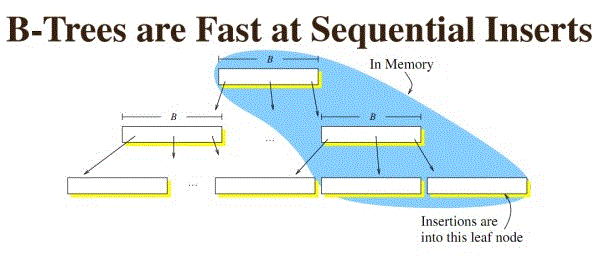
B树在插入的时候,如果是最后一个node,那么速度非常快,因为是顺序写。
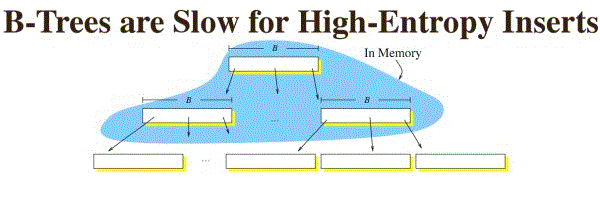
但如果有更新插入删除等综合写入,最后因为需要循环利用磁盘块,所以会出现较多的随机io.大量时间消耗在磁盘寻道时间上。
-----------------------------------------------------------------------------------------------------------------------------------
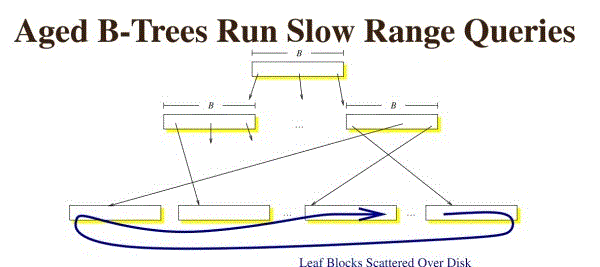
b+树原理,b+树在查询过程中应该是不会慢的,但如果数据插入比较无序的时候,比如先插入5 然后10000然后3然后800 这样跨度很大的数据的时候,就需要先“找到这个数据应该被插入的位置”,然后插入数据。这个查找到位置的过程,如果非常离散,那么就意味着每次查找的时候,他的子节点都不在内存中,这时候就必须使用磁盘寻道时间查找。更新基本与插入是相同的
LSM树

简单来说,就是放弃磁盘读性能来换取写的顺序性。乍一看,似乎会认为读应该是大部分系统最应该保证的特性,所以用读换写似乎不是个好买卖。但别急,听我分析之 LSM树性能分析。
1. 内存的速度超磁盘1000倍以上。而读取的性能提升,主要还是依靠内存命中率而非磁盘读的次数
2. 写入不占用磁盘的io,读取就能获取更长时间的磁盘io使用权,从而也可以提升读取效率。
因此,虽然SSTable降低了了读的性能,但如果数据的读取命中率有保障的前提下,因为读取能够获得更多的磁盘io机会,因此读取性能基本没有降低,甚至还会有提升。而写入的性能则会获得较大幅度的提升,基本上是5~10倍左右。
LSM树 插入数据可以看作是一个N阶合并树。数据写操作(包括插入、修改、删除也是写)都在内存中进行,
数据首先会插入内存中的树。当内存树的数据量超过设定阈值后,会进行合并操作。合并操作会从左至右便利内存中树的子节点 与 磁盘中树的子节点并进行合并,会用最新更新的数据覆盖旧的数据(或者记录为不同版本)。当被合并合并数据量达到磁盘的存储页大小时。会将合并后的数据持久化到磁盘,同时更新父节点对子节点的指针。
LSM树 读数据 磁盘中书的非子节点数据也被缓存到内存中。在需要进行读操作时,总是从内存中的排序树开始搜索,如果没有找到,就从磁盘上的排序树顺序查找。
在LSM树上进行一次数据更新不需要磁盘访问,在内存即可完成,速度远快于B+树。当数据访问以写操作为主,而读操作则集中在最近写入的数据上时,使用LSM树可以极大程度地减少磁盘的访问次数,加快访问速度。
LSM树 删除数据 前面讲了。LSM树所有操作都是在内存中进行的,那么删除并不是物理删除。而是一个逻辑删除,会在被删除的数据上打上一个标签,当内存中的数据达到阈值的时候,会与内存中的其他数据一起顺序写入磁盘。 这种操作会占用一定空间,但是LSM-Tree 提供了一些机制回收这些空间。
作为存储结构,B+树不是关系数据库所独有的,NoSQL数据库也可以使用B+树。同理,关系数据库也可以使用LSM,而且随着SSD硬盘的日趋成熟及大容量持久存储的内存技术的出现,相信B+树这一"古老"的存储结构会再次焕发青春。
二叉树:,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
二叉树,B树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点; 所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B树基础上,为子结点增加链表指针,所有关键字都在子结点中出现,非子结点作为子结点的索引;B+树总是到子结点才命中;
B*树:(寻道)在B+树基础上,为非子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
LSM树:(传输) 在 B+树 基础上, 将读写分离、读操作先内存后磁盘、数据写操作(包括插入、修改、删除也是写)都在内存中进行。到达一定阈值的时候才会刷新到磁盘上。(HBase 刷新到 memStore me) 在大规模情况下,寻道明显比传输低效。
(从磁盘使用方面讲,有两种不同的数据库范式:一种是寻道,一种是传输) RDBMS 通常都是寻道型的。主要是用于存储数据的B树 或 B+ 树结构引起的。 在磁盘寻道的速率级别上实现各种操作,通常每个访问需要 log(N)个寻道操作。
God has given me a gift. Only one. I am the most complete fighter in the world. My whole life, I have trained. I must prove I am worthy of someting. rocky_24
二叉树、B树、B+树、B*树、LSM树的更多相关文章
- LSM树由来、设计思想以及应用到HBase的索引
讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来: 哈希存储引擎 是哈希表的持久化实现,支持增.删.改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储 ...
- LSM树由来、设计思想以及应用到HBase的索引(转)
转自: http://www.cnblogs.com/yanghuahui/p/3483754.html 讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来: 哈希存储引擎 是哈 ...
- 面对key数量多和区间查询低效问题:Hash索引趴窝,LSM树申请出场
摘要:Hash索引有两个明显的限制:(1)当key的数量很多时,维护Hash索引会给内存带来很大的压力:(2)区间查询很低效.如何对这两个限制进行优化呢?这就轮到本文介绍的主角,LSM树,出场了. 我 ...
- LSM树以及在hbase中的应用
转自:http://www.cnblogs.com/yanghuahui/p/3483754.html 讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来: 哈希存储引擎 是哈希 ...
- 平衡二叉树、B树、B+树、B*树、LSM树简介
平衡二叉树是基于分治思想采用二分法的策略提高数据查找速度的二叉树结构.非叶子结点最多只能有两个子结点,且左边子结点点小于当前结点值,右边子结点大于当前结点树,并且为保证查询性能增增删结点时要保证左右两 ...
- LSM树——放弃读能力换取写能力,将多次修改放在内存中形成有序树再统一写入磁盘
LSM树(Log-Structured Merge Tree)存储引擎 代表数据库:nessDB.leveldb.hbase等 核心思想的核心就是放弃部分读能力,换取写入的最大化能力.LSM Tree ...
- 关于时间序列数据库的思考——(1)运用hash文件(例如:RRD,Whisper) (2)运用LSM树来备份(例如:LevelDB,RocksDB,Cassandra) (3)运用B-树排序和k/v存储(例如:BoltDB,LMDB)
转自:http://0351slc.com/portal.php?mod=view&aid=12 近期网络上呈现了有关catena.benchmarking boltdb等时刻序列存储办法的介 ...
- LSM树存储模型
----<大规模分布式存储系统:原理解析与架构实战>读书笔记 之前研究了Bitcask存储模型,今天来看看LSM存储模型,两者尽管同属于基于键值的日志型存储模型.可是Bitcask使用哈希 ...
- HBase LSM树存储引擎详解
1.前提 讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来: 哈希存储引擎. B树存储引擎. LSM树(Log-Structured Merge Tree)存储引擎. 2. 哈希 ...
随机推荐
- swift语言点评二
一.数据类型 1.基础类型的封装 Swift provides its own versions of all fundamental C and Objective-C types, includi ...
- n行m列矩阵顺时针填写1~n*m
程序效果图如下: 程序参考代码如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 ...
- .NET Framework 3.5 无法安装以下功能 安装错误:0x800F0906(客户端加域后出现)
问题:安装错误:0x800F0906 系统安装并加域后,在安装用友软件时提示没有.net 3.5 系统为win10 但是,点击确定后,却出现了这样的错误.如下: 点击下载并安装此功能,出现了这样 ...
- scrapy框架学习
一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- anaconda安装basemap
https://blog.csdn.net/m0_37556124/article/details/80560384 basemap安装前需要先安装geos conda install geos 其次 ...
- canvas 连线曲线图封装
$.fn.hChart=function (opt) { var setting=$.extend({ className:'', data:[] },opt); var tbody=this; va ...
- SpaceVim配置中遇到的问题
这是一个不断更新的随笔,若遇到SpaceVim配置问题时,会添加项 字体乱码(linux企鹅乱码,tabline图标乱码等) git clone https://github.com/powerlin ...
- 详解:(cron , crontab , anacron)
导读: 人类把时间做了切割,想象一条笔直的线永远向前,本来这条直线上什么都没有,但是人类根据时间的长短(单位)在这条直线上做了密密麻麻的标记(世纪-年-月-日-时-分-秒-纳秒......),通过这样 ...
- The Karplus-Strong Algorithm
本系列文章由 @YhL_Leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/48730857 Karplus-Stro ...
- Lucene3.6.2包介绍,第一个Lucene案例介绍,查看索引信息的工具lukeall介绍,Luke查看的索引库内容,索引查找过程
2.Lucene3.6.2包介绍,第一个Lucene案例介绍,查看索引信息的工具lukeall介绍,Luke查看的索引库内容,索引查找过程 2014-12-07 23:39 2623人阅读 评论(0) ...