sklearn学习9----LDA(discriminat_analysis)
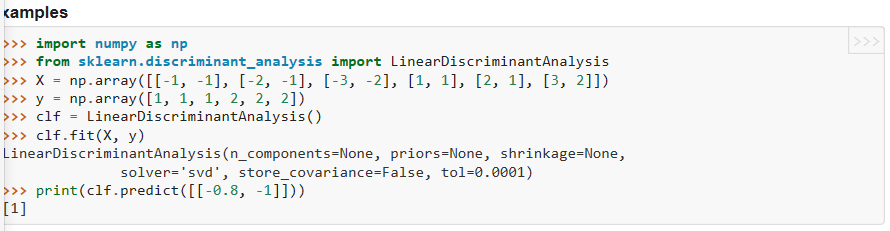
1、导入模块
http://scikit-learn.org/stable/modules/generated/sklearn.discriminant_analysis.LinearDiscriminantAnalysis.html#sklearn.discriminant_analysis.LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
da = LinearDiscriminantAnalysis()
2、使用参数说明:https://blog.csdn.net/qsczse943062710/article/details/75977118
class sklearn.discriminant_analysis.LinearDiscriminantAnalysis(solver=’svd’, shrinkage=None, priors=None, n_components=None, store_covariance=False, tol=0.0001)
solver:str,求解算法,
取值可以为:svd:使用奇异值分解求解,不用计算协方差矩阵,适用于特征数量很大的情形,无法使用参数收缩(shrinkage)lsqr:最小平方QR分解,可以结合shrinkage使用eigen:特征值分解,可以结合shrinkage使用
shrinkage:str or float,是否使用参数收缩
取值可以为:None:不适用参数收缩auto:str,使用Ledoit-Wolf lemma浮点数:自定义收缩比例
priors:array,用于LDA中贝叶斯规则的先验概率,当为None时,每个类priors为该类样本占总样本的比例;当为自定义值时,如果概率之和不为1,会按照自定义值进行归一化n_components:int,需要保留的特征个数,小于等于n-1store_covariance:是否计算每个类的协方差矩阵
3、方法:

4、LinearDiscriminantAnalysis类的fit方法
def fit(self, X, y, store_covariance=None, tol=None):
类型检查,包括priors的检测
根据不同的solver调用不同的求解方法 - 1
- 2
- 3
fit()方法里根据不同的solver调用的方法均为LinearDiscriminantAnalysis的类方法
fit()返回值:
self:LinearDiscriminantAnalysis实例对象
属性:
covariances_:每个类的协方差矩阵, shape = [n_features, n_features]means_:类均值,shape = [n_classes, n_features]priors_:归一化的先验概率rotations_:LDA分析得到的主轴,shape [n_features, n_component]scalings_:数组列表,每个高斯分布的方差σ
5、使用例子(可预测、可降维)
from sklearn.discriminat_analysis import LinearDiscriminantAnalysis as LDA sklearn_lda=LDA(n_components=2)
X_lda_sklearn=sklearn_lda.fit_transform(X,Y)
sklearn学习9----LDA(discriminat_analysis)的更多相关文章
- sklearn学习总结(超全面)
https://blog.csdn.net/fuqiuai/article/details/79495865 前言sklearn想必不用我多介绍了,一句话,她是机器学习领域中最知名的python模块之 ...
- sklearn学习笔记之简单线性回归
简单线性回归 线性回归是数据挖掘中的基础算法之一,从某种意义上来说,在学习函数的时候已经开始接触线性回归了,只不过那时候并没有涉及到误差项.线性回归的思想其实就是解一组方程,得到回归函数,不过在出现误 ...
- sklearn学习 第一篇:knn分类
K临近分类是一种监督式的分类方法,首先根据已标记的数据对模型进行训练,然后根据模型对新的数据点进行预测,预测新数据点的标签(label),也就是该数据所属的分类. 一,kNN算法的逻辑 kNN算法的核 ...
- sklearn 学习 第一篇:分类
分类属于监督学习算法,是指根据已有的数据和标签(分类)进行学习,预测未知数据的标签.分类问题的目标是预测数据的类别标签(class label),可以把分类问题划分为二分类和多分类问题.二分类是指在两 ...
- SKlearn | 学习总结
1 简介 scikit-learn,又写作sklearn,是一个开源的基于python语言的机器学习工具包.它通过NumPy, SciPy和Matplotlib等python数值计算的库实现高效的算法 ...
- sklearn学习笔记3
Explaining Titanic hypothesis with decision trees decision trees are very simple yet powerful superv ...
- sklearn学习笔记2
Text classifcation with Naïve Bayes In this section we will try to classify newsgroup messages using ...
- sklearn学习笔记1
Image recognition with Support Vector Machines #our dataset is provided within scikit-learn #let's s ...
- 莫烦sklearn学习自修第九天【过拟合问题处理】
1. 过拟合问题可以通过调整机器学习的参数来完成,比如sklearn中通过调节gamma参数,将训练损失和测试损失降到最低 2. 代码实现(显示gamma参数对训练损失和测试损失的影响) from _ ...
随机推荐
- Mysql插入语句.txt
INSERT INTO 目标表 SELECT * FROM 来源表;比如要将 articles 表插入到 newArticles 表中,则是:INSERT INTO newArticles SELEC ...
- Laravel的维护模式
1.开启维护模式: php artisan down 2.关闭维护模式:php artisan up 3.当应用处于维护模式时,所有的路由都会指向一个自定义的视图.这对于更新应用或执行维护任务时临时 ...
- 汇编-理解call,ret
; 有意思的东西,主函数调用子函数用汇编来理解 assume cs:codeseg codeseg segment start: main: call sub1 ; 调用子函数1, push IP1 ...
- 小学生都能学会的python(一)2018.9.3
一,小学生第一天 1,认识和了解python python的创始⼈为吉多·范罗苏姆(Guido van Rossum). python是一门解释性语言 弱类型语言 优点:(1).Python的定位是 ...
- Centos7 下安装 Docker
一.简介 Docker是一个开源的应用容器引擎:是一个轻量级容器技术:Docker支持将软件编译成一个镜像:然后在镜像中各种软件做好配置,将镜像发布出去,其他使用者可以直接使用这个镜像:运行中的这个镜 ...
- T4系列文章之1:认识T4
一.导读 MSDN:Code Generation and T4 Text Templates 博客园:编写T4模板进行代码生成 Oleg Sych系列文章:http://www.olegsych.c ...
- nyoj19(排列组合next_permutation(s.begin(),s.end()))
题目意思: 从n个数中选择m个数,按字典序输出其排列. pid=19">http://acm.nyist.net/JudgeOnline/problem.php?pid=19 例: 输 ...
- TCP打洞技术
//转http://iamgyg.blog.163.com/blog/static/3822325720118202419740/ 建立穿越NAT设备的p2p的TCP连接仅仅比UDP复杂一点点,TCP ...
- hdu 1165 Eddy's research II(数学题,递推)
// Eddy 继续 Problem Description As is known, Ackermann function plays an important role in the sphere ...
- 探索Android调用系统的分享功能
非常多的应用为了应用的推广和传播都会使用"分享"的功能,点击分享button.就能将想要分享的内容或者图片分享至QQ空间.微博.微信朋友圈等实现了分享功能的应用.这篇文章主要是为了 ...