C#使用Selenium实现QQ空间数据抓取 说说抓取
上一篇讲的是如何模拟真人操作登录QQ空间,本篇主要讲述一下如何抓取QQ说说数据
继续登录空间后的操作
登陆后我们发现QQ空间的菜单其实是固定的,只需要找到对应元素就可以,继续XPath

可以得到地址
//*[@id="menuContainer"]/div/ul/li[5]/a
看来是第5个li元素,不过这个5看起来并不是索引
点击说说菜单
//*[@id="menuContainer"]/div/ul/li[5]/a
var msgDom = driver.FindElementByXPath("//*[@id='menuContainer']/div/ul/li[5]/a");
if (msgDom != null && msgDom.Displayed == true)
{
msgDom.Click();
}
说说界面查看元素,瞧瞧,我们又发现了什么

没错,又是Iframe,机智的跳转
//页面跳转,切换到说说页面的说说列表Iframe
ITargetLocator t = driver.SwitchTo();
//这里我们换一种获取元素方法,直接使用css获取
//xpath //*[@id="app_container"]/iframe
//css #app_container > iframe
IWebElement frame = driver.FindElementByCssSelector("#app_container > iframe");
t.Frame(frame);
这就找到了列表页,现在我们看下一个说说都有哪些内容组成的
头像,这个属于固定的,每个人单独一个,可以提取出来
QQ号码 说说内容 说说图片 说说日期 赞数量 回复 re回复 可能还有位置 等其他信息
我们定义一个简单的实体类,来存放这些数据,把这些数据先保存到一个集合中
public class MessageInfo
{
/// <summary>
/// 号码
/// </summary>
public string QQ { get; set; }
/// <summary>
/// 发布内容
/// </summary>
public string Content { get; set; }
/// <summary>
/// 发布时间
/// </summary>
public DateTime? MessageTime { get; set; }
/// <summary>
/// 说说图片列表
/// </summary>
public List<string> ImageList { get; set; } }
实体类定义了 那就开始找元素
这个说说列表是一个列表,而且还有分页,那么我们需要考虑的问题就有两个
列表读取和翻页操作了
先说列表,怎么才能知道当前页面有多少条说说呢?
有方法,我们通过li元素的数量就可以判断当前页面有多少个说说了,如下图
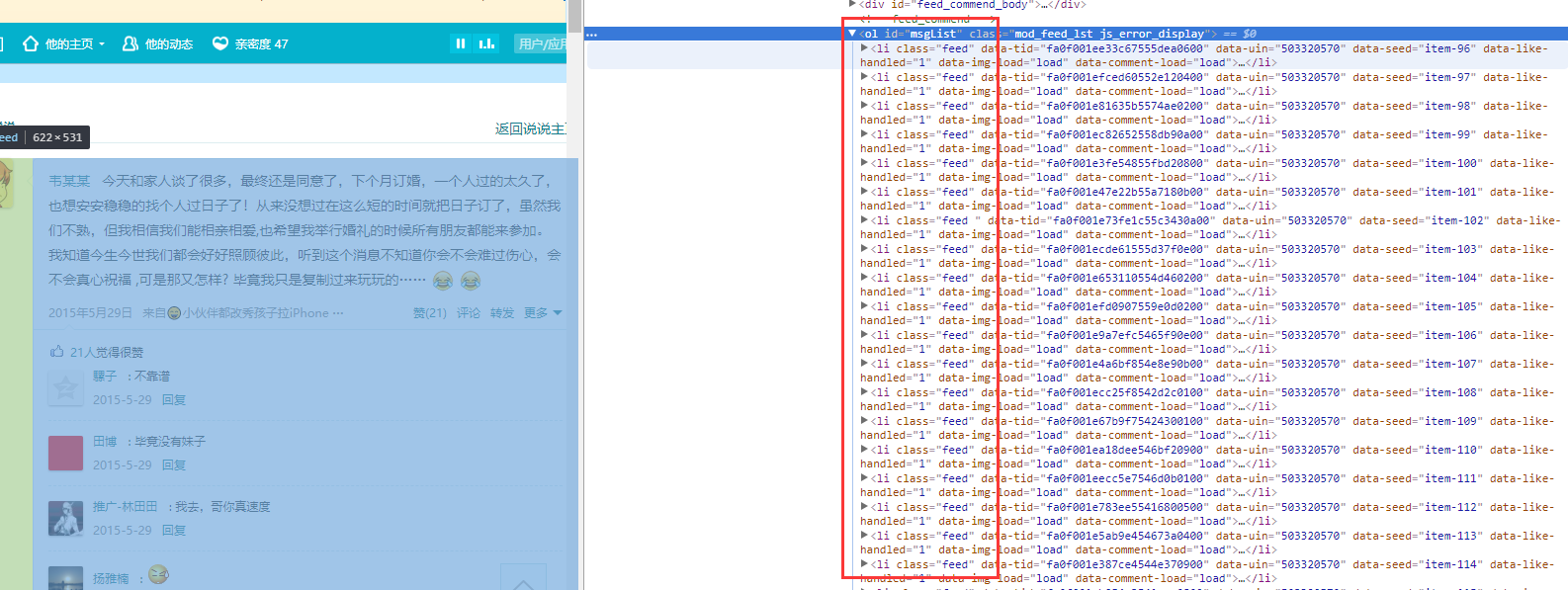
当然不是一个一个找,而是通过方法
//注意这里是复数
var msgListDom = driver.FindElementsByXPath("//*[@id='msgList']/li");
调试可以看到
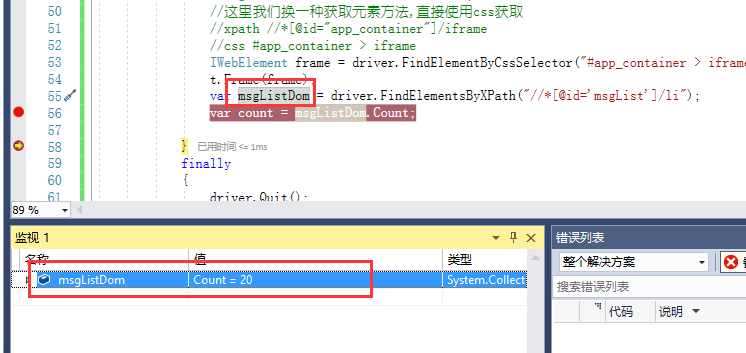
QQ空间的说说一页是20条
我们获取到这些元素,并且循环查找单个元素,并且保存到定义好的集合之中
var msgListDom = driver.FindElementsByXPath("//*[@id='msgList']/li");
//接下来就是循环取数了
//定义说说集合
var dataAll = new List<MessageInfo>();
//因为查找元素需要用到索引值,所以这里就用for循环方式
for (var i = ; i < msgListDom.Count + ; i++)
{
var data = new MessageInfo();
//接下来是查找元素
//第一个
//*[@id="msgList"]/li[1]/div[3]/div[2]/a 所以获取元素可以这样写
var qqDom = driver.FindElementByXPath("//*[@id='msgList']/li[" + i + "]/div[3]/div[2]/a"); //*[@id="msgList"]/li[1]/div[3]/div[2]/a.content 昵称 data-uin QQ号码
if (qqDom != null)
{
//获取元素属性 data-uin对应QQ号码
data.QQ = qqDom.GetAttribute("data-uin");
}
var preDom = driver.FindElementByXPath("//*[@id='msgList']/li[" + i + "]/div[3]/div[2]/pre"); //*[@id="msgList"]/li[1]/div[3]/div[2]/a.content 昵称 data-uin QQ号码
if (preDom != null)
{
//获取元素Text文本值
data.Content = preDom.Text;
}
//获取时间值,我们使用css方式获取,当然也可以使用xpath或者其他方法,查找元素方法第一篇讲过了
//这是获取的是和时间型号同一级的元素,有的包含型号,有的不包含
var times = driver.FindElementsByCssSelector("#msgList > li:nth-child(" + i + ") > div.box.bgr3 > div.ft > div.info > span");
//一个是时间,一个是机型
//2015年2月10日 来自iPhone
if (times.Count > )
{
var time = driver.FindElementByCssSelector("#msgList > li:nth-child(" + i + ") > div.box.bgr3 > div.ft > div.info > span:nth-child(1) > a");
data.MessageTime = Convert.ToDateTime(time.GetAttribute("title"));
//获取手机型号
var mobileDom = driver.FindElementsByCssSelector("#msgList > li:nth-child(" + i + ") > div.box.bgr3 > div.ft > div.info > span:nth-child(2) > span");
if (mobileDom.Count > )
{
var mobile = driver.FindElementByCssSelector("#msgList > li:nth-child(" + i + ") > div.box.bgr3 > div.ft > div.info > span:nth-child(2) > span");
data.MobileType = mobile.Text;
}
}
else
{
var time = driver.FindElementByCssSelector("#msgList > li:nth-child(" + i + ") > div.box.bgr3 > div.ft > div.info > span > a");
data.MessageTime = Convert.ToDateTime(time.GetAttribute("title"));
}
#region 图片视频区域
//如果有视频则获取视频,否则获取图片
var videos = driver.FindElementsByCssSelector("#msgList > li:nth-child(" + i + ") > div.box.bgr3 > div.md > div.video");
if (videos.Count > ) { }
else
{
var imageList = new List<string>();
var images = driver.FindElementsByXPath("//*[@id='msgList']/li[" + i + "]/div[3]/div[3]/div[1]/div/a");
if (images != null && images.Count > )
{
//*[@id="msgList"]/li[1]/div[3]/div[3]/div[1]/div/a[2]
for (int m = ; m < images.Count; m++)
{
var imageDom = driver.FindElementByXPath("//*[@id='msgList']/li[" + i + "]/div[3]/div[3]/div[1]/div/a[" + (m + ) + "]");
if (imageDom != null)
{
imageList.Add(imageDom.GetAttribute("href"));
}
}
}
data.ImageList = imageList;
}
#endregion
dataAll.Add(data);
}
里面需要注意一些细节,元素查找的地方,有不一样的地方,不是所有的说说都是规整的格式,有转发的,转发带视频的,
还有一些自定义的图标之类的,这些都可能会影响我们的数据抓取,不过这个可以慢慢调整,直到程序慢慢完善
举个例子 比如这条说说,在原来显示时间的地方多一个span标签,一个是时间 一个是手机型号,如图

上面代码中,针对这个做了下特殊处理
调试测试如图,我们正确获取到了想要的数据,当然这些只是简单的数据,如需评论 回复的 大家可以自行研究一下,也是找元素
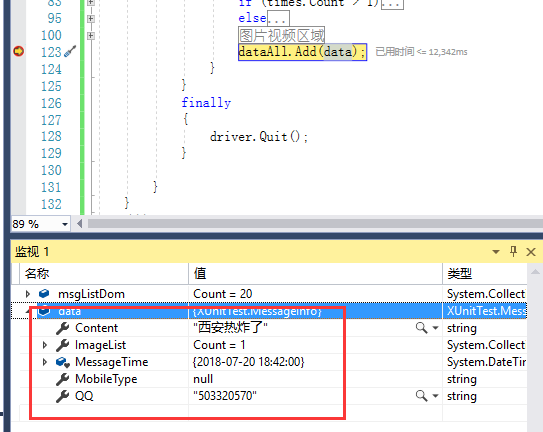
这样我们能获取到当前页的数据,接下来我们介绍下如何翻页
既然是模拟真人操作,那么我们就找到翻页,点击下一页进行数据获取
我们找到下一页这个元素,当页面20条数据循环完毕之后点击它进行翻页操作,每一次都是页面数据读取完成之后点击下一页
我们把读取数据和翻页的方法提取出来,做一个递归,直到下一页无法点击(最后一页的时候,点击下一页是无效的,就终止数据抓取了)
调试图片
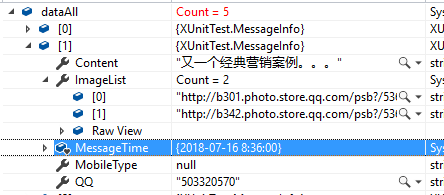
源码,大家可以根据个人情况进行调试修改
public class QzoneTest
{
[Fact]
public void QQLogin()
{
dynamic type = (new PictureTest()).GetType();
string currentDirectory = Path.GetDirectoryName(type.Assembly.Location);
var driver = new ChromeDriver(currentDirectory);
driver.Url = "https://qzone.qq.com/";
try
{
//切换语法有两种,一种是根据索引切换,另外一种根据iframe名称切换
//这里我们使用name切换
ITargetLocator tagetLocator = driver.SwitchTo();
//tagetLocator.Frame(1); //frame index.
tagetLocator.Frame("login_frame"); //frame frame name.
var switchLogin = driver.FindElementByCssSelector("#switcher_plogin");
switchLogin.Click();
var userName = driver.FindElementByXPath("//*[@id='u']");
//这里的userName就是用户名的文本框
//设置用户名的值
userName.SendKeys("");
var pwd = driver.FindElementByXPath("//*[@id='p']");
pwd.SendKeys("********");
var btnLogin = driver.FindElementByXPath("//*[@id='login_button']");
//这里是判断登录按钮是否可见,可以不写,直接调用click方法
if (btnLogin != null && btnLogin.Displayed == true)
{
btnLogin.Click();
}
System.Threading.Thread.Sleep();
//*[@id="menuContainer"]/div/ul/li[5]/a
var msgDom = driver.FindElementByXPath("//*[@id='menuContainer']/div/ul/li[5]/a");
if (msgDom != null && msgDom.Displayed == true)
{
msgDom.Click();
}
//页面跳转,切换到说说页面的说说列表Iframe
ITargetLocator t = driver.SwitchTo();
//这里我们换一种获取元素方法,直接使用css获取
//xpath //*[@id="app_container"]/iframe
//css #app_container > iframe
IWebElement frame = driver.FindElementByCssSelector("#app_container > iframe");
t.Frame(frame);
//定义说说集合
var dataAll = new List<MessageInfo>();
//第一页开始,pageIndex 默认0
//定义汉字方法为了直观描述功能,不要在意这些细节
说说内容获取(driver, dataAll, );
}
finally
{
driver.Quit();
} } private static void 说说内容获取(ChromeDriver driver, List<MessageInfo> dataAll, int pageIndex)
{
//翻页之后休眠3s防止数据没有加载完成出现找不到元素异常
System.Threading.Thread.Sleep();
var msgListDom = driver.FindElementsByXPath("//*[@id='msgList']/li");
//接下来就是循环取数了 //因为查找元素需要用到索引值,所以这里就用for循环方式
for (var i = ; i < msgListDom.Count + ; i++)
{
var data = new MessageInfo();
//接下来是查找元素
//第一个
//*[@id="msgList"]/li[1]/div[3]/div[2]/a 所以获取元素可以这样写
var qqDom = driver.FindElementByXPath("//*[@id='msgList']/li[" + i + "]/div[3]/div[2]/a"); //*[@id="msgList"]/li[1]/div[3]/div[2]/a.content 昵称 data-uin QQ号码
if (qqDom != null)
{
//获取元素属性 data-uin对应QQ号码
data.QQ = qqDom.GetAttribute("data-uin");
}
var preDom = driver.FindElementByXPath("//*[@id='msgList']/li[" + i + "]/div[3]/div[2]/pre"); //*[@id="msgList"]/li[1]/div[3]/div[2]/a.content 昵称 data-uin QQ号码
if (preDom != null)
{
//获取元素Text文本值
data.Content = preDom.Text;
}
//获取时间值,我们使用css方式获取,当然也可以使用xpath或者其他方法,查找元素方法第一篇讲过了
//这是获取的是和时间型号同一级的元素,有的包含型号,有的不包含
var times = driver.FindElementsByCssSelector("#msgList > li:nth-child(" + i + ") > div.box.bgr3 > div.ft > div.info > span");
//一个是时间,一个是机型
//2015年2月10日 来自iPhone
if (times.Count > )
{
var time = driver.FindElementByCssSelector("#msgList > li:nth-child(" + i + ") > div.box.bgr3 > div.ft > div.info > span:nth-child(1) > a");
data.MessageTime = Convert.ToDateTime(time.GetAttribute("title"));
//获取手机型号
var mobileDom = driver.FindElementsByCssSelector("#msgList > li:nth-child(" + i + ") > div.box.bgr3 > div.ft > div.info > span:nth-child(2) > span");
if (mobileDom.Count > )
{
var mobile = driver.FindElementByCssSelector("#msgList > li:nth-child(" + i + ") > div.box.bgr3 > div.ft > div.info > span:nth-child(2) > span");
data.MobileType = mobile.Text;
}
}
else
{
var time = driver.FindElementByCssSelector("#msgList > li:nth-child(" + i + ") > div.box.bgr3 > div.ft > div.info > span > a");
data.MessageTime = Convert.ToDateTime(time.GetAttribute("title"));
}
#region 图片视频区域
//如果有视频则获取视频,否则获取图片
var videos = driver.FindElementsByCssSelector("#msgList > li:nth-child(" + i + ") > div.box.bgr3 > div.md > div.video");
if (videos.Count > ) { }
else
{
var imageList = new List<string>();
var images = driver.FindElementsByXPath("//*[@id='msgList']/li[" + i + "]/div[3]/div[3]/div[1]/div/a");
if (images != null && images.Count > )
{
//*[@id="msgList"]/li[1]/div[3]/div[3]/div[1]/div/a[2]
for (int m = ; m < images.Count; m++)
{
var imageDom = driver.FindElementByXPath("//*[@id='msgList']/li[" + i + "]/div[3]/div[3]/div[1]/div/a[" + (m + ) + "]");
if (imageDom != null)
{
imageList.Add(imageDom.GetAttribute("href"));
}
}
}
data.ImageList = imageList;
}
#endregion
dataAll.Add(data);
}
//下一页
//数据抓取完成之后点击下一页
driver.FindElementByXPath("//*[@id='pager_next_" + pageIndex + "']").Click();
pageIndex++;
说说内容获取(driver, dataAll, pageIndex);
//dataAll 数据存放于内存之中,如果有需要的可以保存到数据库,这里就不详细介绍了
}
}
另外元素集合获取到了应该是可以解析出所有li元素内容的,我这里偷懒没有仔细检查元素,大家可以看一下通过
FindElementsByXPath找到的元素集合来收集数据,这样就不用再次通过浏览器驱动找了,偷了个懒
总结
1 这种数据获取的方法模拟真人,和谐几率较小
2 学会了获取说说,当然留言板,相册什么的 都是查找元素,相册再多一个图片下载保存,还可以直接使用阿里云oss存储,把爬到的数据直接上传到云
3 思维发散一下 , 可以登录自己的QQ去获取QQ好友空间的留言说说及相册,做个数据分析神马的,毕竟Qzone连接是固定格式,比如https://user.qzone.qq.com/123456
把收集到的QQ号码作为种子保存到一个集合,当作浏览器驱动下一个访问的目标,当然还有一点,模拟真人,速度肯定跟爬虫是不能比的.
都不知道自己想说什么,溜了溜了.
git 源码地址:https://github.com/ermpark/CrawlingQzone
C#使用Selenium实现QQ空间数据抓取 说说抓取的更多相关文章
- C#使用Selenium实现QQ空间数据抓取 登录QQ空间
经@吃西瓜的星星提醒 首先我们介绍下Selenium Selenium也是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE.Mo ...
- 测试开发Python培训:抓取新浪微博抓取数据-技术篇
测试开发Python培训:抓取新浪微博抓取数据-技术篇 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.在poptest的se ...
- 网站爬取-案例三:今日头条抓取(ajax抓取JS数据)
今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方法不太一样,对它的抓取需要抓取后台传来的JSON数据,先来看一下今日头条的源码结构:我们 ...
- 使用wireshark抓包分析-抓包实用技巧
目录 使用wireshark抓包分析-抓包实用技巧 前言 自定义捕获条件 输入配置 输出配置 命令行抓包 抓取多个接口 抓包分析 批量分析 合并包 结论 参考文献 使用wireshark抓包分析-抓包 ...
- EL表达式取整数或者取固定小数位数的简单实现
EL表达式取整数或者取固定小数位数的简单实现 例如${8/7} ,${6/7} ,${12/7 } 在页面的显示结果分别为: 1.1428571428571428 0.8571428571428571 ...
- 关于 js 2个数组取差集怎么取
关于 js 2个数组取差集怎么取? 例如求var arr1 = [1]; var arr2 = [1,2];的差集方法一: Array.prototype.diff = function(a) { r ...
- js取整数、取余数
js取整数.取余数 取整 1.取整 // 丢弃小数部分,保留整数部分 parseInt(5/2) // 2 2.向上取整 // 向上取整,有小数就整数部分加1 Math.ceil(5/2) // 3 ...
- 什么是"抓包"?怎样"抓包"?
你是网络管理员吗?你是不是有过这样的经历:在某一天的早上你突然发现网络性能急剧下降,网络服务不能正常提供,服务器访问速度极慢甚至不能访问,网络交换机端口指示灯疯狂地闪烁.网络出口处的路由器已经处于满负 ...
- javascript中的取反再取反~~
操作符~, 是按位取反的意思,表面上~~(取反再取反)没有意义,实际上在JS中可以将浮点数变成整数. <html> <script> var myArray = new Arr ...
随机推荐
- mycat schema.xml 配置文件详解
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> &l ...
- Android JNI编程(一)——JNI概念以及C语言Dev-C++开发环境搭建、编写HelloWorld
版权声明:本文出自阿钟的博客,转载请注明出处:http://blog.csdn.net/a_zhon/. 目录(?)[+] 一:JNI是什么呢? JNI:JNI是JavaNative Interfac ...
- Thinking in UML 学习笔记(四)——UML核心视图之活动图
在UML中活动图的本质就是流程图,它描述了为了完成某一个目标需要做的活动以及这些互动的执行顺序.UML中有两个层面的活动图,一种用于描述用例场景,另一种用于描述对象交互. 活动图只是我们用来描述业务目 ...
- jquery file upload示例
原文链接:http://blog.csdn.net/qq_37936542/article/details/79258158 jquery file upload是一款实用的上传文件插件,项目中刚好用 ...
- js中动态创建json,动态为json添加属性、属性值的实例
如下所示: ? 1 2 3 4 5 6 7 var param = {}; for(var i=0;i<fields.length;i++){ var field = fields[i]; ...
- 【hdu 3863】No Gambling
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65568/32768 K (Java/Others) Total Submission(s) ...
- [Angular] Content Projection with ng-content
For example there is tow form compoennts on the page, and what we want to do is reusing the form com ...
- 【BZOJ 1007】 [HNOI2008]水平可见直线
[题目链接]:http://www.lydsy.com/JudgeOnline/problem.php?id=1007 [题意] [题解] 这个人讲得很好 http://blog.csdn.net/o ...
- WatchDog工作原理
Android系统中,有硬件WatchDog用于定时检测关键硬件是否正常工作,类似地,在framework层有一个软件WatchDog用于定期检测关键系统服务是否发生死锁事件. watchdog的源码 ...
- PHPDocumentor 整理目光规范
你会写凝视么?从我写代码開始.这个问题就一直困扰着我.相信也相同困扰着其它同学.曾经的写凝视总是没有一套行之有效的标准,给维护和协同开发带了很多麻烦,直到近期读到了phpdocumentor的凝视标准 ...