word2vec改进之Hierarchical Softmax
首先Hierarchical Softmax是word2vec的一种改进方式,因为传统的word2vec需要巨大的计算量,所以该方法主要有两个改进点:
1. 对于从输入层到隐藏层的映射,没有采取神经网络的线性变换加激活函数的方法,而是采用简单的对所有输入词向量求和并取平均的方法。
比如输入的是三个4维词向量:(1,2,3,4),(9,6,11,8),(5,10,7,12)(1,2,3,4),(9,6,11,8),(5,10,7,12),那么我们word2vec映射后的词向量就是(5,6,7,8)。这里是从多个词向量变成了一个词向量。
2.第二个改进就是从隐藏层到输出的softmax层这里的计算量个改进。为了避免要计算所有词的softmax概率,word2vec采样了霍夫曼树来代替从隐藏层到输出softmax层的映射
所以这里主要分为三个部分,霍夫曼树的介绍,基于Hierarchical Softmax的CBOW模型和基于Hierarchical Softmax的Skip-Gram模型。
一. 霍夫曼树
构造霍夫曼树步骤:
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 w1、w2、…、wn,则哈夫曼树的构造规则为:
(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
举例:假设有a,b,c,d,e,f六个数,并且值分别为9,12,6,3,5,15
构造的哈夫曼树如下图所示:

这里约定编码方式左子树的编码为1,右子树的编码为0,同时约定左子树的权重不小于右子树的权重。
二. 基于Hierarchical Softmax的CBOW模型
同时CBOW采用了Hierarchical Softmax,该算法结合了Huffman编码,每个词 w 都可以从树的根结点root沿着唯一一条路径被访问到,其路径也就形成了其编码code。假设 n(w, j)为这条路径上的第 j 个结点,且 L(w)为这条路径的长度, j 从 1 开始编码,即 n(w, 1)=root,n(w, L(w)) = w。对于第 j 个结点,层次 Softmax 定义的Label 为 1 - code[j]。
取一个适当大小的窗口当做语境,输入层读入窗口内的词,将它们的向量(K维,初始随机)加和在一起,形成隐藏层K个节点。输出层是一个巨大的二叉树,叶节点代表语料里所有的词(语料含有V个独立的词,则二叉树有|V|个叶节点)。而这整颗二叉树构建的算法就是Huffman树。这样,对于叶节点的每一个词,就会有一个全局唯一的编码,形如"010011",不妨记左子树为1,右子树为0。接下来,隐层的每一个节点都会跟二叉树的内节点有连边,于是对于二叉树的每一个内节点都会有K条连边,每条边上也会有权值。
比如在给定上下文时,对于一个要预测的词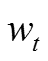
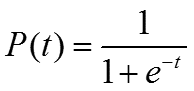
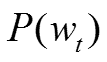
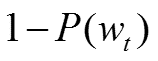
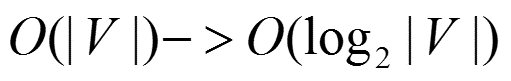
这里总结下基于Hierarchical Softmax的CBOW模型算法流程,梯度迭代使用了随机梯度上升法
步骤:
输入:基于CBOW的语料训练样本,词向量的维度大小M,CBOW的上下文大小2c,步长η
输出:霍夫曼树的内部节点模型参数θ,所有的词向量w
1. 基于语料训练样本建立霍夫曼树。
2. 随机初始化所有的模型参数θ,所有的词向量w
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(context(w),w)做如下处理:

三. 基于Hierarchical Softmax的Skip-Gram模型
Skip-Gram模型和CBOW模型其实是反过来的
对于从输入层到隐藏层(投影层),这一步比CBOW简单,由于只有一个词,所以,即xwxw就是词ww对应的词向量。
第二步,通过梯度上升法来更新我们的θwj−1和xw,注意这里的xw周围有2c个词向量,此时如果我们期望P(xi|xw),i=1,2...2c最大。此时我们注意到由于上下文是相互的,在期望P(xi|xw),i=1,2...2c最大化的同时,反过来我们也期望P(xw|xi),i=1,2...2c最大。那么是使用P(xi|xw)好还是P(xw|xi)好呢,word2vec使用了后者,这样做的好处就是在一个迭代窗口内,我们不是只更新xwxw一个词,而是xi,i=1,2...2c共2c个词。这样整体的迭代会更加的均衡。因为这个原因,Skip-Gram模型并没有和CBOW模型一样对输入进行迭代更新,而是对2c个输出进行迭代更新。
这里总结下基于Hierarchical Softmax的Skip-Gram模型算法流程,梯度迭代使用了随机梯度上升法:
输入:基于Skip-Gram的语料训练样本,词向量的维度大小M,Skip-Gram的上下文大小2c,步长η
输出:霍夫曼树的内部节点模型参数θ,所有的词向量w
1. 基于语料训练样本建立霍夫曼树。
2. 随机初始化所有的模型参数θ,所有的词向量w,
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(w,context(w))做如下处理:

总结:以上是基于Hierarchical Softmax的word2vec模型。
主要参考内容链接如下:
https://www.cnblogs.com/pinard/p/7243513.html
https://blog.csdn.net/weixin_33842328/article/details/86246017
word2vec改进之Hierarchical Softmax的更多相关文章
- Word2Vec实现原理(Hierarchical Softmax)
由于word2vec有两种改进方法,一种是基于Hierarchical Softmax的,另一种是基于Negative Sampling的.本文关注于基于Hierarchical Softmax的改进 ...
- word2vec原理(二) 基于Hierarchical Softmax的模型
word2vec原理(一) CBOW与Skip-Gram模型基础 word2vec原理(二) 基于Hierarchical Softmax的模型 word2vec原理(三) 基于Negative Sa ...
- word2vec 中的数学原理具体解释(四)基于 Hierarchical Softmax 的模型
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单.高效,因此引起了非常多人的关注.因为 word2vec 的作者 Tomas M ...
- DL4NLP——词表示模型(三)word2vec(CBOW/Skip-gram)的加速:Hierarchical Softmax与Negative Sampling
上篇博文提到,原始的CBOW / Skip-gram模型虽然去掉了NPLM中的隐藏层从而减少了耗时,但由于输出层仍然是softmax(),所以实际上依然“impractical”.所以接下来就介绍一下 ...
- 词表征 2:word2vec、CBoW、Skip-Gram、Negative Sampling、Hierarchical Softmax
原文地址:https://www.jianshu.com/p/5a896955abf0 2)基于迭代的方法直接学 相较于基于SVD的方法直接捕获所有共现值的做法,基于迭代的方法一次只捕获一个窗口内的词 ...
- Word2Vector 中的 Hierarchical Softmax
Overall Introduction 之前我们提过基于可以使用CBOW或者SKIP-GRAM来捕捉预料中的token之间的关系,然后生成对应的词向量. 常规做法是我们可以直接feed DNN进去训 ...
- 层次softmax函数(hierarchical softmax)
一.h-softmax 在面对label众多的分类问题时,fastText设计了一种hierarchical softmax函数.使其具有以下优势: (1)适合大型数据+高效的训练速度:能够训练模型“ ...
- [DeeplearningAI笔记]序列模型2.6Word2Vec/Skip-grams/hierarchical softmax classifier 分级softmax 分类器
5.2自然语言处理 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 Word2Vec Word2Vec相对于原先介绍的词嵌入的方法来说更加的简单快速. Mikolov T, Chen ...
- Hierarchical Softmax
When predicting over large vocabulary, softmax becomes one of the expensive computation part. There ...
随机推荐
- 字符串str
字符串: #字符串的索引从0开始的,如果倒数最后一位是-1,索引的位置是唯一的.var1 = var[0:2] #从第一个字符到第2个字符var2 = var[:] #从第一个到最后var3 = va ...
- Sybase_ASA 字符串拼接
列转行并拼接字符串,使用LIST函数 SELECT LIST(T.NAME,',') FROM TAB_DEMO T;
- 用C#在Visual Studio写Javascript单元测试(Firefox内核)
引用nuget包: 注意:Geckofx45 nuget包必须是最后引用,否则初始化会出错 编写JsRunner using Gecko; using System; using System.Col ...
- IOS内购--后台PHP认证
参考网址:https://blog.csdn.net/que_csdn/article/details/80861408 http://www.php.cn/php-weizijiaocheng-39 ...
- 汇编:MSR/MRS/BIC指令
1.MRS指令MRS指令的格式为:MRS{条件} 通用寄存器,程序状态寄存器(CPSR或SPSR)MRS指令用于将程序状态寄存器的内容传送到通用寄存器中.该指令一般用在以下两种情冴: Ⅰ.当需要改 ...
- react typescript 父组件调用子组件
//父组件import * as React from 'react'import { Input } from 'antd'const Search = Input.Searchimport &qu ...
- webpack打包出错,通过babel将es6转es5的出错。
错误信息如下: 解决方法: 1,先安装babel-preset-es2015到项目中, cnpm install babel-preset-es2015 --save-dev2,在项目根目录中新建一个 ...
- 数据结构与算法(4) -- list、queue以及stack
今天主要给大家介绍几种数据结构,这几种数据结构在实现原理上较为类似,我习惯称之为类list的容器.具体有list.stack以及queue. list的节点Node 首先介绍下node,也就是组成li ...
- Sending Secret Messages LightOJ - 1404
Sending Secret Messages LightOJ - 1404 Alice wants to send Bob some confidential messages. But their ...
- MySQL中的分页操作结合python
mysql中的分页操作结合python --分页: --方式1: ;-- 读取十行 , --从第十行读取 往后再读十行 --方式2: offset ; --从第二十行开始读取10行 -- 结合pyth ...