Kettle性能调优汇总
性能调优在整个工程中是非常重要的,也是非常有必要的。但有的时候我们往往都不知道如何对性能进行调优。其实性能调优主要分两个方面:一方面是硬件调优,一方面是软件调优。本章主要是介绍Kettle的性能优化及效率提升。
一、Kettle调优
1、 调整JVM大小进行性能优化,修改Kettle定时任务中的Kitchen或Pan或Spoon脚本。
|
修改脚本代码片段 |
|
set OPT=-Xmx512m -cp %CLASSPATH% -Djava.library.path=libswt\win32\ -DKETTLE_HOME="%KETTLE_HOME%" -DKETTLE_REPOSITORY="%KETTLE_REPOSITORY%" -DKETTLE_USER="%KETTLE_USER%" -DKETTLE_PASSWORD="%KETTLE_PASSWORD%" -DKETTLE_PLUGIN_PACKAGES="%KETTLE_PLUGIN_PACKAGES%" -DKETTLE_LOG_SIZE_LIMIT="%KETTLE_LOG_SIZE_LIMIT%" |
|
参数参考: -Xmx1024m:设置JVM最大可用内存为1024M。 |
|
样例:OPT=-Xmx1024m -Xms512m |
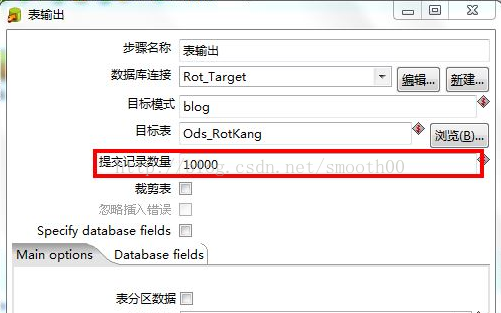
2、 调整提交(Commit)记录数大小进行优化
如修改RotKang_Test01中的“表输出”组件中的“提交记录数量”参数进行优化,Kettle默认Commit数量为:1000,可以根据数据量大小来设置Commitsize:1000~50000。
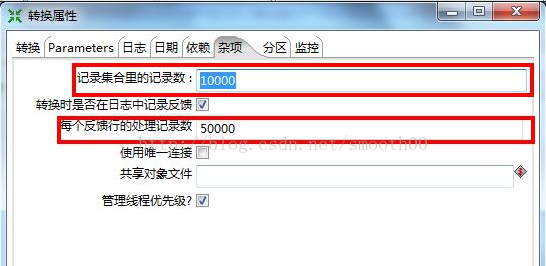
3、 调整记录集合里的记录数
4、尽量使用数据库连接池;
5、尽量提高批处理的commit size;
6、尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流);
7、Kettle是Java做的,尽量用大一点的内存参数启动Kettle;
8、可以使用sql来做的一些操作尽量用sql;
Group , merge , stream lookup,split field这些操作都是比较慢的,想办法避免他们.,能用sql就用sql;
9、插入大量数据的时候尽量把索引删掉;
10、尽量避免使用update , delete操作,尤其是update,如果可以把update变成先delete, 后insert;
11、能使用truncate table的时候,就不要使用deleteall row这种类似sql合理的分区,如果删除操作是基于某一个分区的,就不要使用delete row这种方式(不管是deletesql还是delete步骤),直接把分区drop掉,再重新创建;
12、尽量缩小输入的数据集的大小(增量更新也是为了这个目的);
13、尽量使用数据库原生的方式装载文本文件(Oracle的sqlloader, mysql的bulk loader步骤);
14、尽量不要用kettle的calculate计算步骤,能用数据库本身的sql就用sql ,不能用sql就尽量想办法用procedure,实在不行才是calculate步骤;
15、要知道你的性能瓶颈在哪,可能有时候你使用了不恰当的方式,导致整个操作都变慢,观察kettle log生成的方式来了解你的ETL操作最慢的地方;
16、远程数据库用文件+FTP的方式来传数据,文件要压缩。(只要不是局域网都可以认为是远程连接)。
二、索引的正确使用
在ETL过程中的索引需要遵循以下使用原则:
1、当插入的数据为数据表中的记录数量10%以上时,首先需要删除该表的索引来提高数据的插入效率,当数据全部插入后再建立索引。
2、避免在索引列上使用函数或计算,在where子句中,如果索引列是函数的一部分,优化器将不使用索引而使用全表扫描。
3、避免在索引列上使用 NOT和 “!=”,索引只能告诉什么存在于表中,而不能告诉什么不存在于表中,当数据库遇到NOT和 “!=”时,就会停止使用索引转而执行全表扫描。
4、索引列上用 >=替代 >
高效:select * from temp where deptno>=4
低效:select * from temp where deptno>3
两者的区别在于,前者DBMS将直接跳到第一个DEPT等于4的记录而后者将首先定位到DEPTNO=3的记录并且向前扫描到第一个DEPT大于3的记录。
三、数据抽取的SQL优化
1、Where子句中的连接顺序。
2、删除全表是用TRUNCATE替代DELETE。
3、尽量多使用COMMIT。
4、用EXISTS替代IN。
5、用NOT EXISTS替代NOT IN。
6、优化GROUP BY。
7、有条件的使用UNION-ALL替换UNION。
8、分离表和索引。
Kettle性能调优汇总的更多相关文章
- MySQL性能优化总结___本文乃《MySQL性能调优与架构设计》读书笔记!
一.MySQL的主要适用场景 1.Web网站系统 2.日志记录系统 3.数据仓库系统 4.嵌入式系统 二.MySQL架构图: 三.MySQL存储引擎概述 1)MyISAM存储引擎 MyISAM存储引擎 ...
- Informatica_(6)性能调优
六.实战汇总31.powercenter 字符集 了解源或者目标数据库的字符集,并在Powercenter服务器上设置相关的环境变量或者完成相关的设置,不同的数据库有不同的设置方法: 多数字符集的问题 ...
- 初窥MySQL性能调优
本文涉及:MySQL自带的性能测试工具mysqlslap的使用及几个性能调优的方法 性能测试工具—mysqlslap mysqlslap是MySQL自带的一款非常优秀的性能测试工具.使用它可以 模拟多 ...
- 数据库实例性能调优利器:Performance Insights
Performance Insights是什么 阿里云RDS Performance Insights是RDS CloudDBA产品一项专注于用户数据库实例性能调优.负载监控和关联分析的利器,以简单直 ...
- 一目了然 | 数据库实例性能调优利器:Performance Insights
Performance Insights是什么 阿里云RDS Performance Insights是RDS CloudDBA产品一项专注于用户数据库实例性能调优.负载监控和关联分析的利器,以简单直 ...
- JVM性能调优(3) —— 内存分配和垃圾回收调优
前序文章: JVM性能调优(1) -- JVM内存模型和类加载运行机制 JVM性能调优(2) -- 垃圾回收器和回收策略 一.内存调优的目标 新生代的垃圾回收是比较简单的,Eden区满了无法分配新对象 ...
- Elasticsearch原理解析与性能调优
基本概念 定义 一个分布式的实时文档存储,每个字段 可以被索引与搜索 一个分布式实时分析搜索引擎 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据 用途 全文检索 结构化搜索 分 ...
- web前端性能调优
最近2个月一直在做手机端和电视端开发,开发的过程遇到过各种坑.弄到快元旦了,终于把上线了.2个月干下来满满的的辛苦,没有那么忙了自己准备把前端的性能调优总结以下,以方便以后自己再次使用到的时候得于得心 ...
- [网站性能2]Asp.net平台下网站性能调优的实战方案
文章来源:http://www.cnblogs.com/dingjie08/archive/2009/11/10/1599929.html 前言 最近帮朋友运营的平台进行了性能调优,效果还不错, ...
随机推荐
- jmeter—JDBC request动态参数设置
jmeter—JDBC request动态参数设置 重要参数说明: Variable Name:数据库连接池的名字,需要与JDBC Connection Configuration的Variable ...
- Hystrix 详细说明
在 Hystrix 入门中,使用 Hystrix 时创建命令并给予执行,实际上 Hystrix 有一套较为复杂的执行逻辑,简单来说明以下运作流程: 在命令开始执行时,会做一些准备工作,例如为命令创建响 ...
- ueditor图片上传和显示问题
图片上传: 这段是contorller代码 @RequestMapping(value = "/uploadImg", method = RequestMethod.POST) @ ...
- Vivado中ILA的使用
Vivado中ILA的使用 1.编写RTL代码 其中需要说明的是(* keep = "TRUE" *)语句的意识是保持cnt信号不被综合掉,方便以后的调试,是否可以理解为 ...
- Delphi实现菜单项上出现提示
type TMenuHintWindow = class(THintWindow) private FTimerShow: TTimer; FTimerHide: TTimer; procedure ...
- DS树+图综合练习--二叉树之最大路径
题目描述 给定一颗二叉树的逻辑结构(先序遍历的结果,空树用字符‘0’表示,例如AB0C00D00),建立该二叉树的二叉链式存储结构 二叉树的每个结点都有一个权值,从根结点到每个叶子结点将形成一条路径, ...
- Boost:shared_memory_object --- 共享内存
什么是共享内存 共享内存是最快速的进程间通信机制.操作系统在几个进程的地址空间上映射一段内存,然后这几个进程可以在不需要调用操作系统函数的情况下在那段内存上进行读/写操作.但是,在进程读写共享内存时, ...
- C#对Mongodb数组对象操作
Mongo对数据的存储非常随意,需要修改对象中的数组对象时,就会变得比较复杂. 类中的类对象可以直接通过“.”例如:Department.User.name 类中的对象User是数组时可以用Depar ...
- SQL优化系列——查询优化器
大多数查询优化器将查询计划用“计划节点”树表示.计划节点封装执行查询所需的单个操作.节点被布置为树,中间结果从树的底部流向顶部.每个节点具有零个或多个子节点 - 这些子节点是输出作为父节点输入的节点. ...
- Dubbo(2)发布Dubbo服务
主要参考Dubbo源码包里面的dubbo-demo源码: 1.项目结构: 2.pom.xml中的依赖: <project xmlns="http://maven.apache.org/ ...