Spark项目之电商用户行为分析大数据平台之(七)数据调研--基本数据结构介绍
一、user_visit_action(Hive表)
1.1 表的结构
date:日期,代表这个用户点击行为是在哪一天发生的
user_id:代表这个点击行为是哪一个用户执行的
session_id :唯一标识了某个用户的一个访问session
page_id :点击了某些商品/品类,也可能是搜索了某个关键词,然后进入了某个页面,页面的id
action_time :这个点击行为发生的时间点
search_keyword :如果用户执行的是一个搜索行为,比如说在网站/app中,搜索了某个关键词,然后会跳转到商品列表页面;搜索的关键词
click_category_id :可能是在网站首页,点击了某个品类(美食、电子设备、电脑)
click_product_id :可能是在网站首页,或者是在商品列表页,点击了某个商品(比如呷哺呷哺火锅XX路店3人套餐、iphone 6s)
order_category_ids :代表了可能将某些商品加入了购物车,然后一次性对购物车中的商品下了一个订单,这就代表了某次下单的行为中,有哪些
商品品类,可能有6个商品,但是就对应了2个品类,比如有3根火腿肠(食品品类),3个电池(日用品品类)
order_product_ids :某次下单,具体对哪些商品下的订单
pay_category_ids :代表的是,对某个订单,或者某几个订单,进行了一次支付的行为,对应了哪些品类
pay_product_ids:代表的,支付行为下,对应的哪些具体的商品
1.2 表的说明
user_visit_action表,其实就是放,比如说网站,或者是app,每天的点击流的数据。可以理解为,用户对网站/app每点击一下,就会代表在这个表里面的一条数据。
二、user_info(Hive表)
2.1 表的结构
user_id:其实就是每一个用户的唯一标识,通常是自增长的Long类型,BigInt类型
username:是每个用户的登录名
name:每个用户自己的昵称、或者是真实姓名
age:用户的年龄
professional:用户的职业
city:用户所在的城市
2.2 表的说明
user_info表,实际上,就是一张最普通的用户基础信息表;这张表里面,其实就是放置了网站/app所有的注册用户的信息。那么我们这里也是对用户信息表,进行了一定程度的简化。比如略去了手机号等这种数据。因为我们这个项目里不需要使用到某些数据。那么我们就保留一些最重要的数据,即可。
三、task(MySQL表)
3.1 表的结构
task_id:表的主键
task_name:任务名称
create_time:创建时间
start_time:开始运行的时间
finish_time:结束运行的时间
task_type:任务类型,就是说,在一套大数据平台中,肯定会有各种不同类型的统计分析任务,比如说用户访问session分析任务,页面单跳转化率统计任务;所以这个字段就标识了每个任务的类型
task_status:任务状态,任务对应的就是一次Spark作业的运行,这里就标识了,Spark作业是新建,还没运行,还是正在运行,还是已经运行完毕
task_param:最最重要,用来使用JSON的格式,来封装用户提交的任务对应的特殊的筛选参数
3.2 表的说明
task表,其实是用来保存平台的使用者,通过J2EE系统,提交的基于特定筛选参数的分析任务,的信息,就会通过J2EE系统保存到task表中来。之所以使用MySQL表,是因为J2EE系统是要实现快速的实时插入和查询的。
四、工作流程
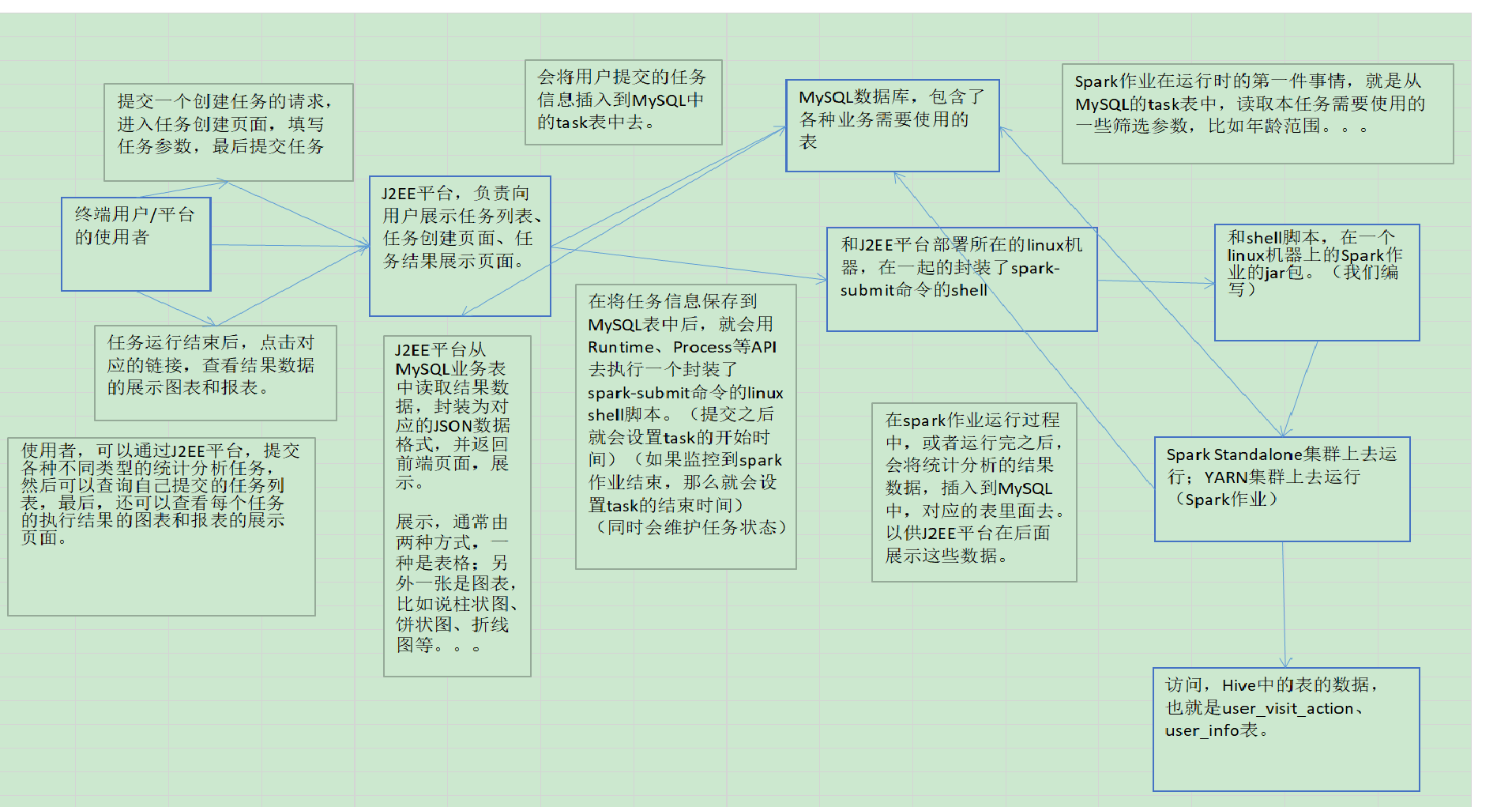

Spark项目之电商用户行为分析大数据平台之(七)数据调研--基本数据结构介绍的更多相关文章
- Spark项目之电商用户行为分析大数据平台之(六)用户访问session分析模块介绍
一.对用户访问session进行分析 1.可以根据使用者指定的某些条件,筛选出指定的一些用户(有特定年龄.职业.城市): 2.对这些用户在指定日期范围内发起的session,进行聚合统计,比如,统计出 ...
- Spark项目之电商用户行为分析大数据平台之(一)项目介绍
一.项目概述 本项目主要用于互联网电商企业中,使用Spark技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.购物行为.广告点击行为等)进行复杂的分析.用统计分析出来的数据,辅助公司中 ...
- Spark项目之电商用户行为分析大数据平台之(十二)Spark上下文构建及模拟数据生成
一.模拟生成数据 package com.bw.test; import java.util.ArrayList; import java.util.Arrays; import java.util. ...
- Spark项目之电商用户行为分析大数据平台之(十)IDEA项目搭建及工具类介绍
一.创建Maven项目 创建项目,名称为LogAnalysis 二.常用工具类 2.1 配置管理组建 ConfigurationManager.java import java.io.InputStr ...
- Spark项目之电商用户行为分析大数据平台之(九)表的设计
一.概述 数据设计,往往包含两个环节: 第一个:就是我们的上游数据,就是数据调研环节看到的项目基于的基础数据,是否要针对其开发一些Hive ETL,对数据进行进一步的处理和转换,从而让我们能够更加方便 ...
- Spark项目之电商用户行为分析大数据平台之(八)需求分析
1.按条件筛选session 搜索过某些关键词的用户.访问时间在某个时间段内的用户.年龄在某个范围内的用户.职业在某个范围内的用户.所在某个城市的用户,发起的session.找到对应的这些用户的ses ...
- Spark项目之电商用户行为分析大数据平台之(三)大数据集群的搭建
Zookeeper集群搭建 http://www.cnblogs.com/qingyunzong/p/8619184.html Hadoop集群搭建 http://www.cnblogs.com/qi ...
- Spark项目之电商用户行为分析大数据平台之(十一)JSON及FASTJSON
一.概述 JSON的全称是”JavaScript Object Notation”,意思是JavaScript对象表示法,它是一种基于文本,独立于语言的轻量级数据交换格式.XML也是一种数据交换格式, ...
- Spark项目之电商用户行为分析大数据平台之(五)实时数据采集
随机推荐
- C# serialPort的DataReceived事件无法触发 ,用的霍尼韦尔的扫码枪并且装了相应的USB转串口驱动。
昨天想试试霍尼韦尔的扫码枪,扫码枪有两种模式,键盘模式和串口模式, 1.键盘模式直接插上就行了,就像一个键盘一样不需要任何驱动,扫出来的数据直接落到PC的输入焦点上.就像一个键盘一样,只能输入字符. ...
- oracle的学习笔记(转)
Oracle的介绍 1. Oracle的创始人----拉里•埃里森 2. oracle的安装 [连接Oracle步骤](](https://img2018.cnblogs.com/blog/12245 ...
- SpringIOC的小例子
IOC IOC--Inversion of Control即控制反转,常常和DI--依赖注入一起被提到. 核心是为了解除程序之间的耦合度. 那么什么样的代码是耦合度高的呢? 假如有个人现在去买苹果 i ...
- TCP连接与OKHTTP复用连接池
Android网络编程(八)源码解析OkHttp后篇[复用连接池] 1.引子 在了解OkHttp的复用连接池之前,我们首先要了解几个概念. TCP三次握手 通常我们进行HTTP连接网络的时候我们会进行 ...
- php中parse_url函数解析
1.在php开发过程中我们经常要用到用户上传文件这个功能,那么用户上传文件我们肯定要知道用户上传文件的合法性,那么我们就要从url中获取文件的扩展名.那么就会用到parse_url()这个函数. pa ...
- js 微信支付
引入 <script type="text/javascript" src="http://res.wx.qq.com/open/js/jweixin-1.2.0. ...
- js-ES6学习笔记-let命令
1.let命令 ES6新增了let命令,用来声明变量.它的用法类似于var,但是所声明的变量,只在let命令所在的代码块内有效. for循环的计数器,就很合适使用let命令. 下面的代码如果使用var ...
- ES6——TDZ(暂时性死区)
暂时性的死区(Temporal Dead Zone),简写为 TDZ: 只要块级作用域里存在let命令,它所声明的变量就绑定这个区域,不在受外部的影响 let 和 const 声明的变量不会被提升到作 ...
- SD从零开始45-46
[原创] SD从零开始45 运输流程的控制 运输业务场景的例子Examples 一个公司可使用不同的运输业务场景,通过不同的处理类型或者运输方式来刻画: 要模型化这些不同的装运,你可以在配置中定义装运 ...
- js判断数组是否包含某个字符串变量
最近碰到一个这样的现象,后台返回的数据中,数组里面有一些有变量值,有一些没有变量值. 举个例子,比如后台返回的例子是这样的: var arr=[ { "status":" ...