hadoop 修改datanode balance带宽使用限制
前段时间,一个客户现场的Hadoop看起来很不正常,有的机器的存储占用达到95%,有的机器只有40%左右,刚好前任的负责人走了,这边还没有明确接班人的时候。
我负责的大数据计算部分,又要依赖Hadoop的基础平台,要是Hadoop死了,我的报表也跑不出来(专业背锅)。
做下balance,让各个节点的存储均衡一下。
1、首先需要配上这个参数:
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value></value>
<description>hdfs做balance的占用的网络带宽,建议配置网卡带宽的一半(//*=480MBps)</description>
</property>
2、重启datanode
# 停止datanode
[hadoop@venn06 sbin]$ ./hadoop-daemon.sh stop datanode
stopping datanode # 启动datanode
[hadoop@venn06 sbin]$ ./hadoop-daemon.sh start datanode
starting datanode, logging to /opt/hadoop/hadoop3/logs/hadoop-hadoop-datanode-venn06.out
服务器网卡的带宽有限,不设置这个参数,做balance的时候,会把网卡的带宽跑满。需要移动的block很多,执行时间就会很长,会导致集群网络资源不足,任务跑得很慢。
3、执行balance
[hadoop@venn05 bin]$ pwd
/opt/hadoop/hadoop3/bin
[hadoop@venn05 bin]$ nohup ./hdfs balancer -threshold 1 &
由于执行时间会很长,所以把命令放到后台执行。
HDFS做balance的方式大概如下:
1、计算集群中需要移动的block数量,计算需要移动的文件大小。
2、并发的从资源占用高的机器,往资源占用低的机器移数据。一批一批的移,一批的大小,会根据需要移动的文件大小计算。
3、重复第1步,直到资源均衡(1%左右的差距)
HDFS做balance的时候,会先移动block,成功后才会删除数据,只要集群网络资源充足,可以不警慎的执行balance操作,随时停也不影响,不会丢数据。
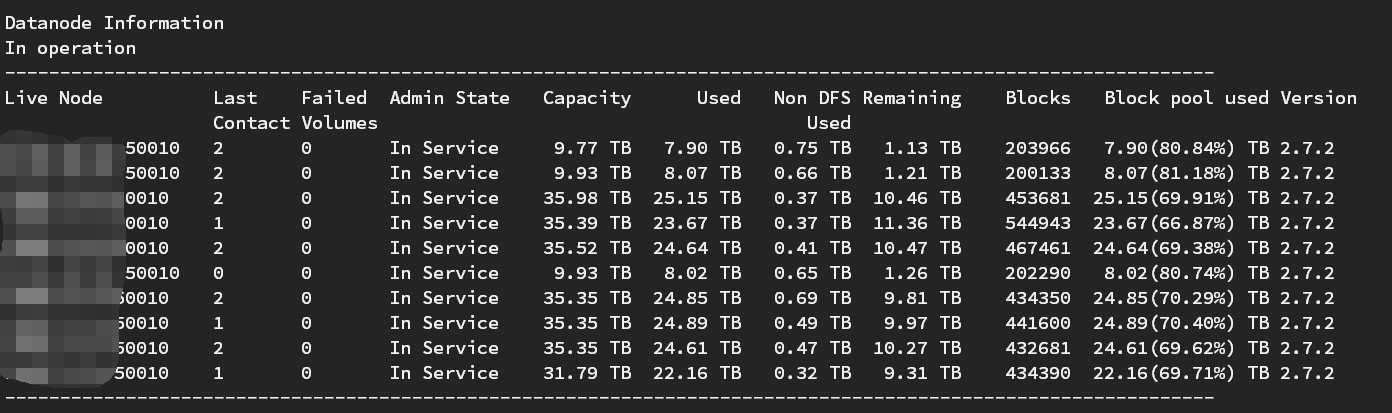
由于datanode 空间大小不同,所以有的机器磁盘占用会高一点。
hadoop 修改datanode balance带宽使用限制的更多相关文章
- Hadoop的datanode无法启动
Hadoop的datanode无法启动 hdfs-site中配置的dfs.data.dir为/usr/local/hadoop/hdfs/data 用bin/hadoop start-all.sh启动 ...
- 设置Hadoop的 dataNode的单个Map的内存配置
1.进入hadoop的配置目录 ,找到 环境变量的 $HADOOP_HOME cd $HADOOP_HOME 2.修改dataNode 节点的 单个map的能使用的内存配置 找到配置的文件: /opt ...
- hadoop修改MR的提交的代码程序的副本数
hadoop修改MR的提交的代码程序的副本数 Under-Replicated Blocks的数量很多,有7万多个.hadoop fsck -blocks 检查发现有很多replica missing ...
- linux及hadoop修改权限
linux下修改文件权限: 在shell环境里输入:ls -l 或者 ls -lh drwxr-xr-x 2 nsf users 1024 12-10 17:37 下载文件备份对应:文件属性 连接数 ...
- hadoop启动 datanode的live node为0
hadoop启动 datanode的live node为0 浏览器访问主节点50070端口,发现 Data Node 的 Live Node 为 0 查看子节点的日志 看到 可能是无法访问到主节点的9 ...
- 解决hadoop no dataNode to stop问题
错误原因: datanode的clusterID 和 namenode的 clusterID 不匹配. 解决办法: 1. 打开 hadoop/tmp/dfs/namenode/name/dir 配置对 ...
- hadoop修改
https://github.com/medcl/elasticsearch-analysis-ik/releases hadoop-/etc/hadoop/core-site.xml <con ...
- hadoop 运行 datanode , mac 系统
问题描述 今天使用 hadoop 时,发现无法通过下面命令上传文件到 hadoop 文件系统,会报错. bin/hadoop fs -put input . 运行 jps 后,输出如下: Resour ...
- hadoop中datanode无法启动
一.问题描述 当我多次格式化文件系统时,如 [hadoop@xsh hadoop]$ ./bin/hdfs namenode -format 会出现datanode无法启动,查看日志(/usr/loc ...
随机推荐
- 思维+并查集 hdu5652
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5652 题意: 输入T,接下来T个样例,每个样例输入n,m代表图的大小,接下来n行,每行m个数,代表图, ...
- Codeforces Beta Round #73 (Div. 2 Only)
Codeforces Beta Round #73 (Div. 2 Only) http://codeforces.com/contest/88 A 模拟 #include<bits/stdc+ ...
- PAT L2-016 愿天下有情人都是失散多年的兄妹(深搜)
呵呵.大家都知道五服以内不得通婚,即两个人最近的共同祖先如果在五代以内(即本人.父母.祖父母.曾祖父母.高祖父母)则不可通婚.本题就请你帮助一对有情人判断一下,他们究竟是否可以成婚? 输入格式: 输入 ...
- f5双机配置
1.1)要确认2 台设备的型号及版本完全一致! 2)2台设备分别取名f5_4.com 和f5_3.com,并将时区修改成上海时区 注:设备的hostname不能随便修改. 3)VLAN配置 由于当前环 ...
- java常量类编译问题
常量类编译后并不在.class文件中呈现,取而代之的是各个具体的常量.例如: 编译前:(Constant.OPTIONSRADIO常量值为1) 编译后: 应用场景 1,项目编译后发布项目前可以删除常量 ...
- 再遇ibatisNet
11年在Mr刘的带领下第一次接触ibatisnet ,当时Mr刘很详细的很讲了xml里的写法还有配置文件之类的,但是随着时间越来越久远.很多东西都开始淡忘了. 如今,再次和它相遇,依然觉得很亲切,虽然 ...
- [leetcode]528. Random Pick with Weight按权重挑选索引
Given an array w of positive integers, where w[i] describes the weight of index i, write a function ...
- docker搭建lnmp(二)
上一篇利用 不同的命令来构建 nginx,mysql,php镜像 和 容器. 这样做比较麻烦,也很容易出错,当然可以写入 sh脚本来执行.但是可以通过 docker-compose 来达到效果,管理起 ...
- SQL新增数据取表主键最新值
string strsql = "insert into SB_Survey(title) values ('标题');select @@IDENTITY"; int s = in ...
- 8.Mysql数据类型选择
8.选择合适的数据类型8.1 CHAR与VARCHAR CHAR固定长度的字符类型,char(n) 当输入长度不足n时将用空格补齐,char(n)占用n个字节,CHAR类型输出时会截断尾部的空格,即使 ...