转:SQL 关于apply的两种形式cross apply 和 outer apply
原文地址:http://www.cnblogs.com/Leo_wl/archive/2013/04/02/2997012.html
SQL 关于apply的两种形式cross apply 和 outer apply
apply有两种形式: cross apply 和 outer apply
先看看语法:
<left_table_expression> {cross|outer} apply <right_table_expression>
再让我们了解一下apply运算涉及的两个步骤:
- A1:把右表表达式(<right_table_expression>)应用到左表(<left_table_expression>)输入的行;
- A2:添加外部行;
使用apply就像是先计算左输入,让后为左输入中的每一行计算一次右输入。(这一句很重要,可能会不理解,但要先记住,后面会有详细的说明)
最后结合以上两个步骤说明cross apply和outer apply的区别:
cross apply和outer apply 总是包含步骤A1,只有outer apply包含步骤A2,如果cross apply左行应用右表表达式时返回空积,则不返回该行。而outer apply返回改行,并且改行的右表表达式的属性为null。
看到上面的解释或步骤大家可能还是一头的雾水,不知所云。下面用例子来说明:
先建表一([dbo].[Customers] 字段说明:customerid -- 消费者id , city -- 所在城市):

CREATE TABLE [dbo].[Customers](
[customerid] [char](5) COLLATE Chinese_PRC_CI_AS NOT NULL,
[city] [varchar](10) COLLATE Chinese_PRC_CI_AS NOT NULL,
PRIMARY KEY CLUSTERED
(
[customerid] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
向表一插入数据:
insert into dbo.Customers values('FISSA','Madrid');
insert into dbo.Customers values('FRNDO','Madrid');
insert into dbo.Customers values('KRLOS','Madrid');
insert into dbo.Customers values('MRPHS','Zion');
查询所插入的数据:
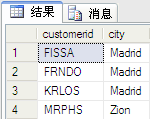
select * from dbo.Customers
结果如图:
再建表二([dbo].[Orders] 字段说明:orderid -- 订单id , customerid -- 消费者id):
CREATE TABLE [dbo].[Orders](
[orderid] [int] NOT NULL,
[customerid] [char](5) COLLATE Chinese_PRC_CI_AS NULL,
PRIMARY KEY CLUSTERED
(
[orderid] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
向表二插入数据:
insert into dbo.Orders values(1,'FRNDO');
insert into dbo.Orders values(2,'FRNDO');
insert into dbo.Orders values(3,'KRLOS');
insert into dbo.Orders values(4,'KRLOS');
insert into dbo.Orders values(5,'KRLOS');
insert into dbo.Orders values(6,'MRPHS');
insert into dbo.Orders values(7,null);
查询插入的数据:
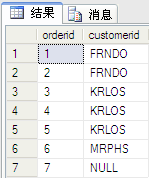
select * from dbo.orders
结果如图:
例子:题目:得到每个消费者最新的两个订单:
用cross apply
sql:
select *
from dbo.Customers as C
cross apply
(select top 2 *
from dbo.Orders as O
where C.customerid=O.customerid
order by orderid desc) as CA
结果如图:
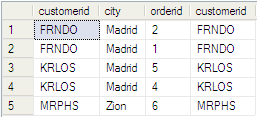
过程分析:
它是先得出左表【dbo.Customers】里的数据,然后把此数据一条一条的放入右表表式中,分别得出结果集,最后把结果集整合到一起就是最终的返回结果集了(T1的数据 像for循环一样 一条一条的进入到T2中 然后返回一个集合 最后把所有的集合整合到一块 就是最终的结果),最后我们再理解一下上面让记着的话(使用apply就像是先计算左输入,让后为左输入中的每一行计算一次右输入)是不是有所明白了。
实验:用outer apply 试试看看的到的结果:
sql语句:
select *
from dbo.Customers as C
outer apply
(select top 2 *
from dbo.Orders as O
where C.customerid=O.customerid
order by orderid desc) as CA
结果如图:

结果分析:
发现outer apply得到的结果比cross多了一行,我们结合上面所写的区别(cross apply和outer apply 总是包含步骤A1,只有outer apply包含步骤A2,如果cross apply左行应用右表表达式时返回空积,则不返回该行。而outer apply返回改行,并且改行的右表表达式的属性为null)就会知道了。
关于with cube ,with rollup 和 grouping
通过查看sql 2005的帮助文档找到了CUBE 和 ROLLUP 之间的具体区别:
- CUBE 生成的结果集显示了所选列中值的所有组合的聚合。
- ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合。
再看看对grouping的解释:
当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。
仅在与包含 CUBE 或 ROLLUP 运算符的 GROUP BY 子句相关联的选择列表中才允许分组。
当看到以上的解释肯定非常的模糊,不知所云和不知道该怎样用,下面通过实例操作来体验一下:
先建表(dbo.PeopleInfo):
CREATE TABLE [dbo].[PeopleInfo](
[id] [int] IDENTITY(1,1) NOT NULL,
[name] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[numb] [nchar](10) COLLATE Chinese_PRC_CI_AS NOT NULL,
[phone] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[FenShu] [int] NULL
) ON [PRIMARY]
向表插入数据:
insert into peopleinfo([name],numb,phone,fenshu) values ('李欢','3223','1365255',80)
insert into peopleinfo([name],numb,phone,fenshu) values ('李欢','322123','1',90)
insert into peopleinfo([name],numb,phone,fenshu) values ('李名','3213112352','13152',56)
insert into peopleinfo([name],numb,phone,fenshu) values ('李名','32132312','13342563',60)
insert into peopleinfo([name],numb,phone,fenshu) values ('王华','3223','1365255',80)
查询出插入的全部数据:
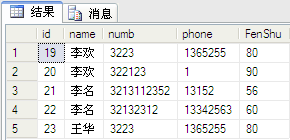
select * from dbo.PeopleInfo
结果如图:
操作一:先试试:1, 查询所有数据;2,用group by 查询所有数据;3,用with cube。这三种情况的比较
SQL语句如下:
select * from dbo.PeopleInfo --1, 查询所有数据; select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb --2,用group by 查询所有数据; select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with cube --3,用with cube。这三种情况的比较
结果如图:
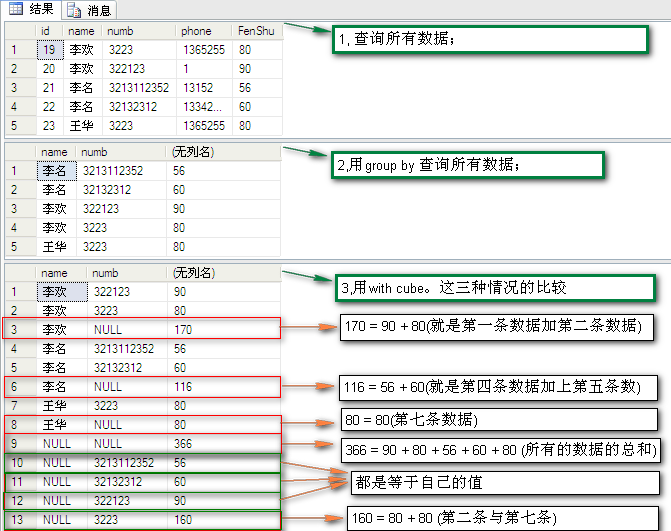
结果分析:
用第三种(用with cube)为什么会多出来有null的字段值呢?通过分析图上的值得组合会发现是怎么回事儿了,以第三条数据(李欢,null,170)为例:它只是把姓名是【李欢】的分为了一组,而没有考虑【numb】,所以有多出来了第三条数据,也说明了170是怎么来的。其他的也是这样。再回顾一下帮助文档的解释:CUBE 生成的结果集显示了所选列中值的所有组合的聚合, 发现明了了许多。
操作二:1,用with cube;2,用with rollup 这两种情况的比较
SQL语句如下:
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with cube --用with cube。 select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with rollup --用with rollup。
结果如图:
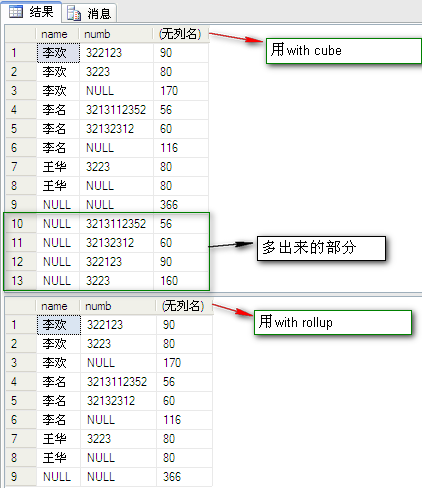
结果分析:
为什么with cube 比 with rollup多出来一部分呢?原来它没有显示,以【numb】分组而不考虑【name】的数据情况。再回顾一下帮助文档的解释:ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合,那这个【某一层次】又是以什么为标准的呢?我的猜想是:距离group up最近的字段必须考虑在分组内。
证明猜想实例:
操作:用两个group up 交换字段位置的sql语句和一个在group up 后面增加一个字段的sql语句进行比较:
SQL语句如下:
select [name],numb from dbo.PeopleInfo group by [name],numb with rollup select [name],numb from dbo.PeopleInfo group by numb,[name] with rollup select [name],numb,phone from dbo.PeopleInfo group by [name],numb,phone with rollup
结果如图:
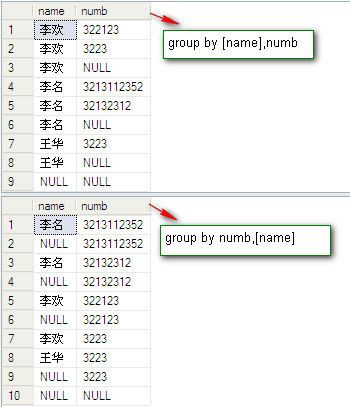
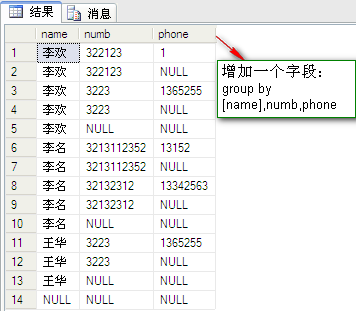
通过结果图的比较发现猜想是正确的。
---------------------------------------------------grouping-------------------------------------------------
现在来看看grouping的实例:
SQL语句看看与with rollup的结合(与with cube的结合是一样的):
select [name],numb,grouping(numb) from dbo.PeopleInfo group by [name],numb with rollup
结果如图:
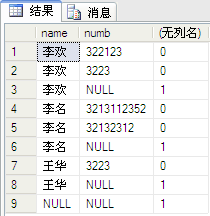
结果分析:
结合帮助文档的解释:当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。 很容易理解再此就不多解释了。
转:SQL 关于apply的两种形式cross apply 和 outer apply的更多相关文章
- SQL 关于apply的两种形式cross apply 和 outer apply
SQL 关于apply的两种形式cross apply 和 outer apply 例子: CREATE TABLE [dbo].[Customers]( ) COLLATE Chinese_PRC_ ...
- SQL关于apply的两种形式cross apply和outer apply(转载)
SQL 关于apply的两种形式cross apply 和 outer apply apply有两种形式: cross apply 和 outer apply 先看看语法: <lef ...
- SQL 关于apply的两种形式cross apply 和 outer apply(转)
转载链接:http://www.cnblogs.com/shuangnet/archive/2013/04/02/2995798.html apply有两种形式: cross apply 和 oute ...
- SQL 关于apply的两种形式cross apply 和 outer apply, with cube 、with rollup 和 grouping
1). apply有两种形式: cross apply 和 outer apply先看看语法: <left_table_expression> {cross|outer} apply &l ...
- C# ASP.NET(配置数据库 sql server 地址的两种形式以及配置信息的获取)
( 1 ) 数据库装在本机,并且采用windows认证模式 <connectionStrings> <add name="SQLConnectionString&qu ...
- 在sql中case子句的两种形式
case子句,在select后面可以进行逻辑判断. 两种形式:判断相等.判断不等 一.判断相等的语法: case 列名 when ... then ... when ... then ... el ...
- MyBatis collection的两种形式——MyBatis学习笔记之九
与association一样,collection元素也有两种形式,现介绍如下: 一.嵌套的resultMap 实际上以前的示例使用的就是这种方法,今天介绍它的另一种写法.还是以教师映射为例,修改映射 ...
- 基于 Scrapy-redis 两种形式的分布式爬虫
基于 Scrapy-redis 两种形式的分布式爬虫 .caret, .dropup > .btn > .caret { border-top-color: #000 !important ...
- C++:一般情况下,设计函数的形参只需要两种形式
C++:一般情况下,设计函数的形参只需要两种形式.一,是引用形参,例如 void function (int &p_para):二,是常量引用形参,例如 void function(const ...
随机推荐
- sql的存储过程实例--动态根据表数据复制一个表的数据到另一个表
动态根据表数据复制一个表的数据到另一个表 把track表的记录 根据mac_id后两位数字,复制到对应track_? 的表中 如:mac_id=12345678910,则后两位10 对应表为track ...
- Re:从零开始的Spring Session(二)
上一篇文章介绍了一些Session和Cookie的基础知识,这篇文章开始正式介绍Spring Session是如何对传统的Session进行改造的.官网这么介绍Spring Session: Spri ...
- [转]Reporting Services 中的身份验证类型
本文转自:https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008/cc281310%28v%3dsql.100%2 ...
- Book Contents Reviews Notes Errata Articles Talks Downloads Resources Code Formatter Cover of C# in Depth Order now (3rd edition) Implementing the Singleton Pattern in C#
原文链接地址: http://csharpindepth.com/Articles/General/Singleton.aspx#unsafe Implementing the Singleton P ...
- c3p0 配置文件的设置。解决编码乱码问题等
<?xml version="1.0" encoding="UTF-8"?> <c3p0-config> <named-confi ...
- MySQL 中NULL和空值的区别,索引列可以有空值或者null吗?
空值跟null的区别.mysql官方: “NULL columns require additional space in the row to record whether their values ...
- NIO学习笔记五:Buffer 的使用
Java NIO中的Buffer用于和NIO通道进行交互.数据是从通道读入缓冲区,从缓冲区写入到通道中. 缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存.这块内存被包装成NIO Buffe ...
- python学习之老男孩python全栈第九期_第一次周末考试题(over)第三次添加完毕
day 6python基础数据类型考试题 考试时间:两个半小时 满分100分(80分以上包含80分及格) 一,基础题. 1. 简述变量命名规范(3分) 答:(1) 变量为数字,字母以及下划线的任意组合 ...
- python正则表达式贪婪与非贪婪模式
之前做程序的时候看到过正则表达式的贪婪与非贪婪模式,今天用的时候就想不起来了,现在这里总结一下,以备自己以后用到注意. 1.什么是正则表达式的贪婪与非贪婪匹配 如:String str="a ...
- 【代码笔记】iOS-UITableView上的button点击事件
代码. ViewController.h #import <UIKit/UIKit.h> @interface ViewController : UIViewController < ...