【elasticsearch】关于elasticSearch的基础概念了解【转载】
转载原文:https://www.cnblogs.com/chenmc/p/9516100.html
该作者本系列文章,写的很详尽
=================================================================================
1. 关于索引
1.1 关于索引的一些基础知识
在创建标准化索引的时候,我们传入的请求体如下:

{
"settings":{
"number_of_shards":5,
"number_of_replicas":1
},
"mappings":{
"novel":{
"properties":{
"id":{
"type":"integer"
},
"book_name":{
"type":"text"
},
"author":{
"type":"keyword"
},
"brief_introduction":{
"type":"text"
},
"publish_date":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss || yyyy-MM-dd"
},
"word_count":{
"type":"integer"
}
}
}
}
}
首先,ElasticSearch的对象模型如下:
- 索引(Index):相当于数据库,用于定义文档类型的存储;在同一个索引中,同一个字段只能定义一个数据类型;
- 文档类型(Type):相当于关系表,用于描述文档中的各个字段的定义;不同的文档类型,能够存储不同的字段,服务于不同的查询请求;
- 文档(Document):相当于关系表的数据行,存储数据的载体,包含一个或多个存有数据的字段;
- 字段(Field):文档的一个Key/Value对;
- 词(Term):表示文本中的一个单词;
- 标记(Token):表示在字段中出现的词,由该词的文本、偏移量(开始和结束)以及类型组成;
所以,上面的请求体我们就可以这样标记:
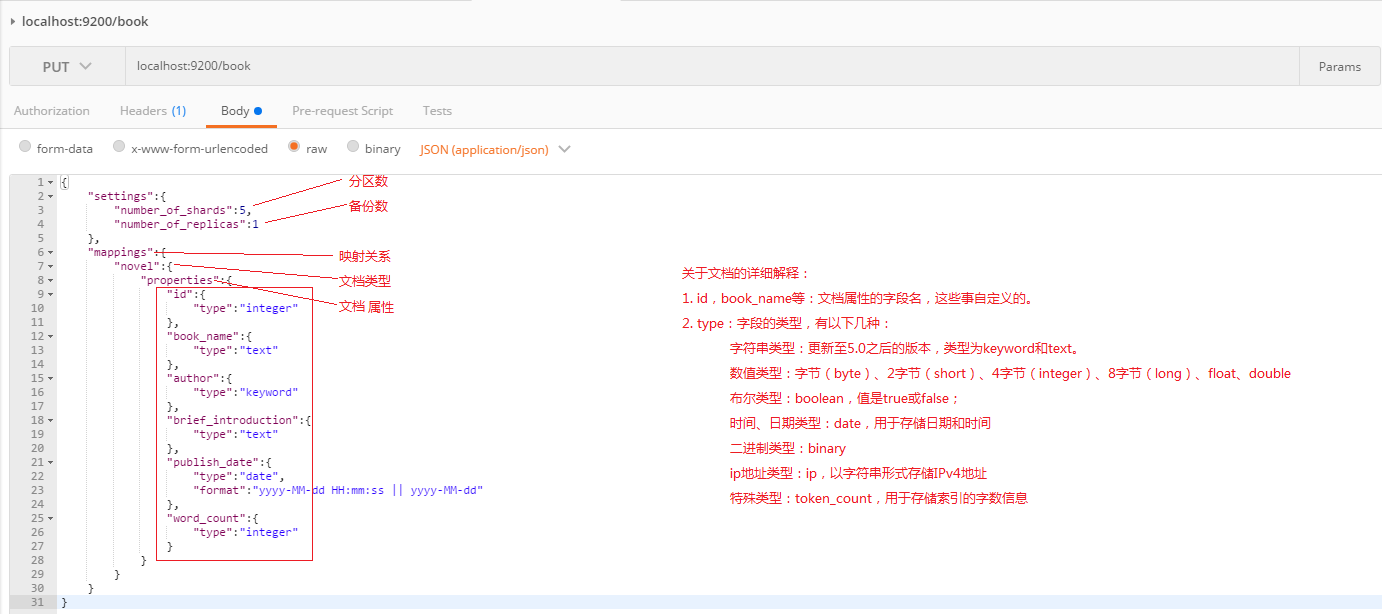
详细的解释下:
type:目前在6.0的时候,有keyword和text,区别为:
keyword:数据类型用来建立电子邮箱地址、姓名、邮政编码和标签等数据类型,不需要进行分词。可以被用来检索过滤、排序和聚合。keyword 类型字段只能用本身来进行检索。
text:Text 数据类型被用来索引长文本,这些文本会被分析,在建立索引前会将这些文本进行分词,转化为词的组合,建立索引。比如你配置了IK分词器,那么就会进行分词,搜索的时候会搜索分词来匹配这个text文档。但是:text 数据类型不能用来排序和聚合
1.2 关于索引的自动创建禁止与否
在上篇博客中,我们提到,当我们插入数据的时候,如果有超出我们结构化的数据的时候,索引会自动更新数据,但是很多时候会出现,不是同一个人操作的时候,插入的数据各式各样的,最后导致索引无法使用!如何解决?
dynamic属性有三个值:
true:默认,可以自动创建索引,插入数据字段不符合的话就创建新的索引。
false:不自动创建索引,当插入数据不符合默认属性的时候,忽略新插入的不符合的字段的值。
strict:精确的,不允许插入不符合默认属性的值,如果不符合,直接报错。
我们可以在创建索引的时候,指定索引是绝对的,精确的,就可以避免因为写错而更新了新的字段,如下图:当然我们也可以设置当插入字段和我们预先定义的映射不符的话,忽略这些新插入的字段,但是这样的话后期查找问题可能会比较麻烦。
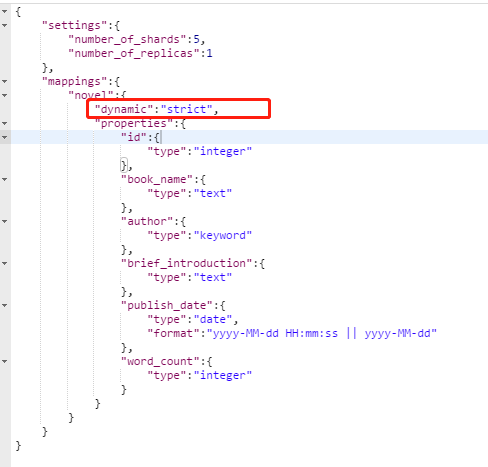
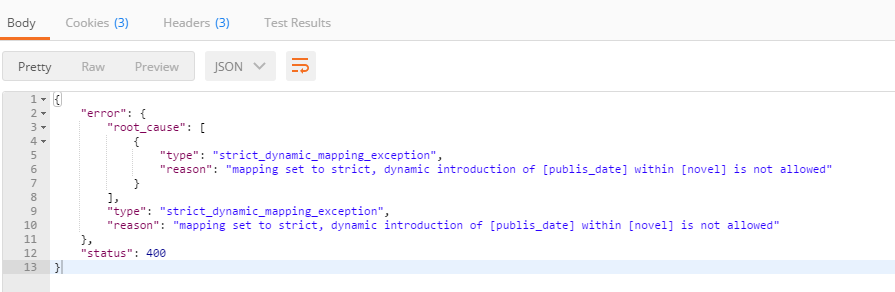
这样的话,当你插入不符合标准化索引的时候,就会提示错误而导致无法插入,当然这样也有麻烦的地方,如果插入数据出错,可能会导致数据丢失,所以如果在项目中你需要这样做的话,最好可以将失败的数据写入日志文件或者直接写入数据库,这样就可以避免数据的丢失了,也可以重新拿到失败的数据进行重新索引。
1.3 关于文档类型的属性
文档属性定义了文档类型的共用属性,适用于文档的所有字段。当然也可以指定字段属性,只适用于某个特定的字段。
- dynamic_date_formats属性:该属性定义可以识别的日期格式列表;如果文档中有多个字段都是时间格式,可以通用的进行设置。
- dynamic属性:默认为true,允许动态地向文档类型中加入新的字段。可选值为:true,false,strict。上面已经介绍过了(详见1.2.)。
1.4 关于文档字段的属性值
1.4.1 字段的数据类型
字段的数据类型由字段的属性type指定,ElasticSearch支持的基础数据类型主要有:
- 字符串类型:keyword和text。(在5.0之后更改,原来为string)。详细的介绍见1.1。
- 数值类型:字节(byte)、2字节(short)、4字节(integer)、8字节(long)、float、double;
- 布尔类型:boolean,值是true或false;
- 时间/日期类型:date,用于存储日期和时间;
- 二进制类型:binary;
- IP地址类型:ip,以字符串形式存储IPv4地址;
- 特殊数据类型:token_count,用于存储索引的字数信息
1.4.2 字段的公共属性:
- index:该属性控制字段是否编入索引被搜索,该属性共有三个有效值:analyzed、no和not_analyzed:store:指定是否将字段的原始值写入索引,默认值是no,字段值被分析,能够被搜索,但是,字段值不会存储,这意味着,该字段能够被查询,但是不会存储字段的原始值。
- analyzed:(默认属性)表示该字段被分析,编入索引,产生的token能被搜索到;
- not_analyzed:表示该字段不会被分析,使用原始值编入索引,在索引中作为单个词;
- no:不编入索引,无法搜索该字段;
- 其中analyzed是分析,分解的意思,默认值是analyzed,表示将该字段编入索引,以供搜索。
- boost:字段级别的助推,默认值是1,定义了字段在文档中的重要性/权重;
- include_in_all:该属性指定当前字段是否包括在_all字段中,默认值是ture,所有的字段都会包含_all字段中;如果index=no,那么属性include_in_all无效,这意味着当前字段无法包含在_all字段中。
- copy_to:该属性指定一个字段名称,ElasticSearch引擎将当前字段的值复制到该属性指定的字段中;
- doc_values:文档值是存储在硬盘上的索引时(indexing time)数据结构,对于not_analyzed字段,默认值是true,analyzed string字段不支持文档值;
- fielddata:字段数据是存储在内存中的查询时(querying time)数据结构,只支持analyzed string字段;
- null_value:该属性指定一个值,当字段的值为NULL时,该字段使用null_value代替NULL值;在ElasticSearch中,NULL 值不能被索引和搜索,当一个字段设置为NULL值,ElasticSearch引擎认为该字段没有任何值,使用该属性为NULL字段设置一个指定的值,使该字段能够被索引和搜索。
1.4.3 字符串类型常用的其他属性
- analyzer:该属性定义用于建立索引和搜索的分析器名称,默认值是全局定义的分析器名称,该属性可以引用在配置结点(settings)中自定义的分析器;
- search_analyzer:该属性定义的分析器,用于处理发送到特定字段的查询字符串;
- ignore_above:该属性指定一个整数值,当字符串字段(analyzed string field)的字节数量大于该数值之后,超过长度的部分字符数据将不能被analyzer处理,不能被编入索引;对于 not analyzed string字段,超过长度的部分字符将被忽略,不会被编入索引。默认值是0,禁用该属性;
- position_increment_gap:该属性指定在相同词的位置上增加的gap,默认值是100;
- index_options:索引选项控制添加到倒排索引(Inverted Index)的信息,这些信息用于搜索(Search)和高亮显示:
- docs:只索引文档编号(Doc Number)
- freqs:索引文档编号和词频率(term frequency)
- positions:索引文档编号,词频率和词位置(序号)
- offsets:索引文档编号,词频率,词偏移量(开始和结束位置)和词位置(序号)
- 默认情况下,被分析的字符串(analyzed string)字段使用positions,其他字段使用docs;
分析器(analyzer)把analyzed string 字段的值,转换成标记流(Token stream),例如,字符串"The quick Brown Foxes",可能被分解成的标记(Token)是:quick,brown,fox。这些词(term)是该字段的索引值,这使用对索引文本的查找更有效率。字段的属性 analyzer 用于指定在index-time和search-time时,ElasticSearch引擎分解字段值的分析器名称。
2. 关于请求方法
在使用ElasticSearch的时候,我们会牵扯到很多的请求方法,比如GET,POST,PUT,DELETE等等,这些方法使用的都是Restful的调用风格,我们来简单介绍下这些方法
- GET 请求:获取服务器中的对象
- 相当于SQL的Select命令
- GET /book 获取所有的book信息
- POST 请求:在服务器上更新对象
- 相当于SQL的update命令
- POST /book/1 更新id为1的book的信息
- PUT 请求:在服务器上创建对象
- 相当于SQL的create命令
- PUT /book/id 创建一个id为xx的书
- DELETE 请求:删除服务器中的对象HEAD 请求:仅仅用于获取对象的基础信息
- 相当于sql中的delete命令
- DELETE /book/1 删除id为1的书
【elasticsearch】关于elasticSearch的基础概念了解【转载】的更多相关文章
- 【Elasticsearch学习】之基础概念
Elasticsearch是一个近实时的分布式搜索引起,其底层基于开源全文搜索库Lucene:Elasticsearch对Lucene进行分装,对外提供REST API 的操作接口.基于 ES,可以快 ...
- [Elasticsearch] 全文搜索 (一) 基础概念和match查询
全文搜索(Full Text Search) 现在我们已经讨论了搜索结构化数据的一些简单用例,是时候开始探索全文搜索了 - 如何在全文字段中搜索来找到最相关的文档. 对于全文搜索而言,最重要的两个方面 ...
- Elasticsearch教程之基础概念
基础概念 Elasticsearch有几个核心概念.从一开始理解这些概念会对整个学习过程有莫大的帮助. 1.接近实时(NRT) Elasticsearch是一个接近实时的搜索平台.这意味 ...
- 白日梦的ES笔记三:万字长文 Elasticsearch基础概念统一扫盲
目录 一.导读 二.彩蛋福利:账号借用 三.ES的Index.Shard及扩容机制 四.ES支持的核心数据类型 4.1.数字类型 4.2.日期类型 4.3.boolean类型 4.4.二进制类型 4. ...
- 【转载】Apache Storm 官方文档 —— 基础概念
[转载自https://yq.aliyun.com/articles/87510?t=t1] Storm 系统中包含以下几个基本概念: 拓扑(Topologies) 流(Streams) 数据源(Sp ...
- Elasticsearch学习之基本核心概念
在Elasticsearch中有许多术语和概念 1. 核心概念 Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包 ...
- (转载)小白的linux设备驱动归纳总结(一):内核的相关基础概念---学习总结
1. 学习总结 小白的博客讲的linux内核驱动这一块的东西比较基础,因此想通过学习他的博客,搭配着看书的方式来学习linux内核和驱动.我会依次更新在学习小白的博客的过程的感悟和体会. 2.1 内核 ...
- Elasticserach学习笔记-01基础概念
本文系本人根据官方文档的翻译,能力有限.水平一般,如果对想学习Elasticsearch的朋友有帮助,将是本人的莫大荣幸. 原文出处:https://www.elastic.co/guide/en/e ...
- ELK&ElasticSearch5.1基础概念及配置文件详解【转】
1. 配置文件 elasticsearch/elasticsearch.yml 主配置文件 elasticsearch/jvm.options jvm参数配置文件 elasticsearch/log4 ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
随机推荐
- 报错stale element reference: element is not attached to the page document结局方案
今天在调试脚本时,遇到如下报错: org.openqa.selenium.StaleElementReferenceException: stale element reference: elemen ...
- Android安全系列之:如何在native层保存关键信息
相信大家在日常开发中都要安全层面的需求,最典型的莫过于加密.而apk是脆弱的,反编译拿到你的源码轻而易举,这时候我们就需要更保险的手段来保存密钥之类的关键信息.本文就细致地讲解简单却实用的native ...
- dede列表页读取当前栏目名称
list或者arclist之内使用[field:typename/]之外使用{dede:field name='typename'/}
- python中使用pillow绘制汉字
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pillow from PIL import Image, ImageFont, I ...
- spring boot + vue + element-ui
spring boot + vue + element-ui 一.页面 1.布局 假设,我们要开发一个会员列表的页面. 首先,添加vue页面文件“src\pages\Member.vue” 参照文档h ...
- 【LOJ】#2479. 「九省联考 2018」制胡窜
题解 老了,国赛之前敲一个后缀树上LCT和线段树都休闲的很 现在后缀树上线段树合并差点把我写死 主要思路就是后缀树+线段树合并+容斥,我相信熟练的OIer看到这已经会了 但就是不想写 但是由于我过于老 ...
- 【LOJ】#2496. 「AHOI / HNOI2018」毒瘤
题面 还有这么诚实的出题人! 我们最多影响20个点,然后把这20个点的虚树建出来,并且枚举每个点的选举状态,如果一个点选或不选可以通过改\(dp[u][0] = 0\)或\(dp[u][1] = 0\ ...
- 【LOJ】#2888. 「APIO2015」巴邻旁之桥 Palembang Bridges
题解 发现我们选择一座桥会选择力\(\frac{s + t}{2}\)较近的一座桥 然后我们只需要按照\(s + t\)排序,然后枚举断点,左边取所有s和t的中位数,右边同理 动态求中位数用平衡树维护 ...
- Win7建立FTP站点
Win7建立FTP站点 1.到控制面板---程序---打开或关闭windows功能,列表内找到 Internet信息服务(展开)---选中FTP的三个项: 2.到控制面板---系统和安全---管理工具 ...
- CSS transform中的rotate的旋转中心怎么设置
transform-origin属性 默认情况,变形的原点在元素的中心点,或者是元素X轴和Y轴的50%处.我们没有使用transform-origin改变元素原点位置的情况下,CSS变形进行的旋转.移 ...