JDK8集合类源码解析 - HashMap
java为数据结构中的映射定义了一个接口java.util.Map,此接口主要有四个常用的实现类,分别是HashMap、Hashtable、LinkedHashMap和TreeMap
HashMap 比较常用,无序的,线程不安全的
Hashtable (不推荐使用)线程安全的,如果要确保线程安全,推荐使用ConcurrentHashMap
LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序
TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序(比如在微信支付做签名的时候就可以使用TreeMap),也可以指定排序的比较器
考虑到使用情况 ,Hashmap的使用频率最高,这篇文章主要分析HashMap
接下来我将按照以下几个部分来介绍下
1核心数据结构
2相关方法解析
3其他补充
性能?
扩容因子?
线程安全性?
容量必须是2的n次幂?
4最佳实践
====================
1核心数据结构
Jdk8采用的是数组+链表+红黑树(当链表长度超过8的时候就会转化成红黑树,本文不对红黑树展开讨论,想了解更多红黑树数据结构的工作原理同学 可以点击 红黑树)
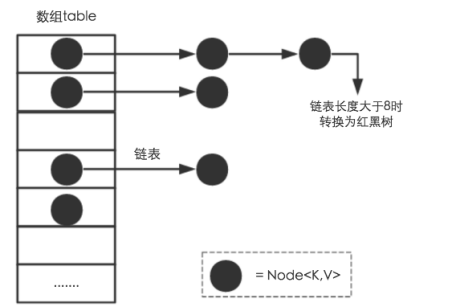
核心代码如下
transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //用来定位数组索引位置
final K key;
V value;
Node<K,V> next; //下一个Node
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
static class LinkedHashMap.Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
可以看出Node是TreeNode的爷爷
2相关方法解析
put 方法解析
public V put(K key, V value) {
//hash() 获取key在table里面的下标值
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; //table为空 初始化table
if ((p = tab[i = (n - 1) & hash]) == null)//table当前下标的值为空直接插入
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//判断是否和已有的key重复,如果重复 把当前节点赋值给e 结束判断
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果该节点 是TreeNode 进行红黑树的操作
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果该链表元素不止一个
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//链表长度超过8 转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//在链表中找到相同的key 循环结束
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//如果找到了相同的key的节点 进行value覆盖
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//如果超过最大容量 就执行扩容操作
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
resize方法解析
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) { //超过最大值就不再扩充了
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//容量扩大一倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // 长度为0 初始化
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//如果原来的数组不为空 移动数据到扩容后的数组中
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null; //让原来的值为空 方便gc
if (e.next == null)
//如果该链只有一个数据 就放置到新的数组去
//新的下标要么是原来的下标,要么是原来的+oldCap(后面会说道)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 如果是该链后面还有数据 就遍历重新得到新的2条或者1条新的链
//新的低位的head,tail
Node<K,V> loHead = null, loTail = null;
//新的高位的head,tail
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
注意:关于扩容后的下标计算
这里假如原来的大小为16,扩容后变成32
分别有两个元素 key1,key2
扩容前 [(n - 1) & hash] 长度16
长度(n-1) 0000 0000 0000 0000 0000 0000 0000 1111
key1 1111 1111 1111 1111 0000 1111 0001 0010 --> 0 0010 2
key2 1111 1111 1111 1111 0000 1111 0000 0010 --> 0 0010 2
扩容后(e.hash & oldCap) 长度32
长度(n) 0000 0000 0000 0000 0000 0000 0001 0000
key1 1111 1111 1111 1111 0000 1111 0001 0010 --> 1 0010 18
key2 1111 1111 1111 1111 0000 1111 0000 0010 --> 0 0010 2
于是乎只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话下标没变,是1的话下标变成 原下标+oldCap
3其他补充
性能?这里分2种情况,第一种,hash比较均匀的状况下,jdk8比jdk7提高了至少10%的性能
第二种,hash不均匀的状况下,jdk7的get方法花费的时间会随着长度的增加而线性增加,而jdk8中当链表长度过长会转成红黑树,get方法花费的时间呈现对数增长稳定。
扩容因子? 默认为0.75,这是综合时间和空间的利用率来考虑的,通常不要变,如果该值过大,可能会造成链表太长,导致get、put等操作缓慢;如果太小,空间利用率不足。
线程安全性?线程不安全,容易导致死循环(形成环形链表),多线程环境推荐使用ConcurrentHashMap
容量必须是2的n次幂?当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,当然这我们指定大小的时候不需要指定为2的n次幂,jdk会调用tableSizeFor()返回大于当前值的最小的2的n次幂整数
4最佳实践
1 在使用hashmap的时候,如果能够预知需要使用的大小,最好指定其大小,较少因为扩容而导致的性能损失。
HashMap<String,Object> map = new HashMap<>(100);
2 HashMap可以插入null的key 的value
3线程不安全,多线程环境推荐使用ConcurrentHashMap
4 JDK1.8引入红黑树很大程度提高了HashMap的性能,特别是在hash极不均衡的时候。
JDK8集合类源码解析 - HashMap的更多相关文章
- JDK8集合类源码解析 - HashSet
HashSet 特点:不允许放入重复元素 查看源码,发现HashSet是基于HashMap来实现的,对HashMap做了一次“封装”. private transient HashMap<E,O ...
- JDK8集合类源码解析 - LinkedList
linkedList主要要注意以下几点: 1构造器 2 添加add(E e) 3 获取get(int index) 4 删除 remove(E e),remove(int index) 5 判断对象 ...
- JDK8集合类源码解析 - ArrayList
ArrayList主要要注意以下几点: 1构造方法 2添加add(E e) 3 获取 get(int index) 4 删除 remove(int index) , remove(Objec ...
- Java集合类源码解析:HashMap (基于JDK1.8)
目录 前言 HashMap的数据结构 深入源码 两个参数 成员变量 四个构造方法 插入数据的方法:put() 哈希函数:hash() 动态扩容:resize() 节点树化.红黑树的拆分 节点树化 红黑 ...
- JDK8源码解析 -- HashMap(二)
在上一篇JDK8源码解析 -- HashMap(一)的博客中关于HashMap的重要知识点已经讲了差不多了,还有一些内容我会在今天这篇博客中说说,同时我也会把一些我不懂的问题抛出来,希望看到我这篇博客 ...
- Java集合类源码解析:Vector
[学习笔记]转载 Java集合类源码解析:Vector 引言 之前的文章我们学习了一个集合类 ArrayList,今天讲它的一个兄弟 Vector.为什么说是它兄弟呢?因为从容器的构造来说,Vec ...
- Java集合类源码解析:ArrayList
目录 前言 源码解析 基本成员变量 添加元素 查询元素 修改元素 删除元素 为什么用 "transient" 修饰数组变量 总结 前言 今天学习一个Java集合类使用最多的类 Ar ...
- Java集合类源码解析:AbstractMap
目录 引言 源码解析 抽象函数entrySet() 两个集合视图 操作方法 两个子类 参考: 引言 今天学习一个Java集合的一个抽象类 AbstractMap ,AbstractMap 是Map接口 ...
- Java集合类源码解析:LinkedHashMap
前言 今天继续学习关于Map家族的另一个类 LinkedHashMap .先说明一下,LinkedHashMap 是继承于 HashMap 的,所以本文只针对 LinkedHashMap 的特性学习, ...
随机推荐
- 【selenium+python】关于使用selenium时的几个问题1
问题:selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in ...
- centos 7 redis-4.0.11 主从
redis-master:192.168.199.223 redis-slave: 192.168.199.224 cd /opt wget http://download.redis.io/rele ...
- delet[] 和delete
string *stringPtr1 = new string; string *stringPtr2 = new string[100]; …… delete stringPtr1; delete ...
- vue-webpack项目自动打包压缩成zip文件批处理
为什么需要这个? 使用vue框架开发项目,npm run build这个命令会一直用到,如果需要给后端发包,那你还要打包成zip格式的压缩包,特别是项目提测的时候,一天可能要执行重复好几次,所以才有了 ...
- redis(三)积累-基本的取值和设值
1. 先把redis的连接池拿出来, JedisPool pool=new JedisPool(new JedisPoolConfig(),"127.0.0.1") Jedis ...
- 安装sql server 2008 提示错误 SQL Server 2005 Express 工具。 失败
安装sql server 2008 management,提示错误:Sql2005SsmsExpressFacet 检查是否安装了 SQL Server 2005 Express 工具. 失败,已安装 ...
- Failed to read artifact descriptor for xxx:jar的问题解决
在开发的过程中,尤其是新手,我们经常遇到Maven下载依赖jar包的问题,也就是遇到“Failed to read artifact descriptor for xxx:jar”的错误. 对于这种非 ...
- springmvc.xml,context.xml和web.xml
1:springmvc.xml配置要点 一般它主要配置Controller的组件扫描器和视图解析器 下为:springmvc.xml文件 <?xml version="1.0" ...
- pthreads v3下一些坑和需要注意的地方
一.子线程无法访问父线程的全局变量,但父线程可以访问子线程的变量 <?php class Task extends Thread { public $data; public function ...
- 移动端 input 输入框实现自带键盘“搜索“功能并修改X
主要利用html5的,input[type=search]属性来实现,此时input和type=text外观和功能没啥区别: html代码入下: <form action="" ...