python获取动态网站上面的动态加载的数据(初级)
我们在处理一些网站数据的时候,有时候我们需要的数据很多都是动态加载的,而不都是静态的,以下以一个实例来介绍简单的获取动态数据,首先申明本人小白,还在学习python中,这个方法还是比较笨拙的,但是对于初学者还是需要知道的。
首先我们的要求是获取下面文章的参考文献:
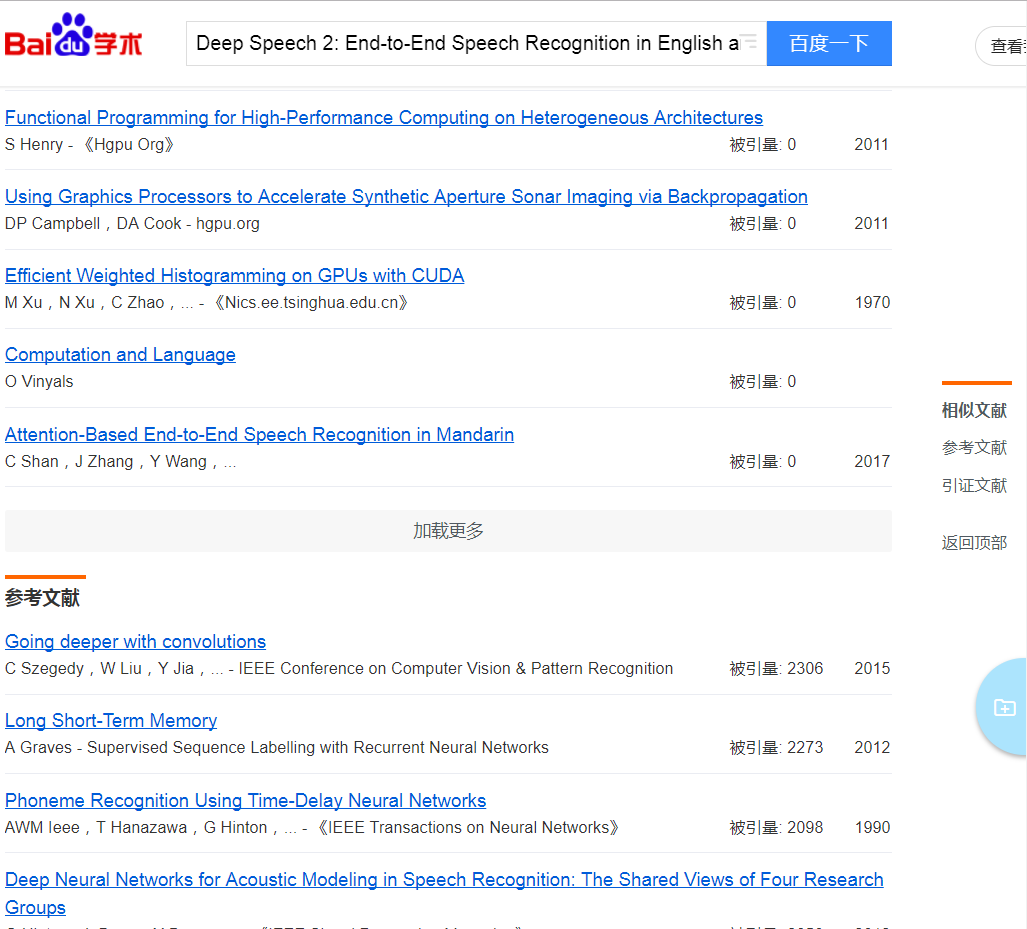
刚刚开始,我的想法是使用lxml、BeatifulSoup、正则表达式来处理,这几个是处理静态网站的常用方法,查看网页源码我们会发现相应的div里面是空,也就是说上面的数据不是静态的,而是后面动态加载的,利用googl浏览器可以看到:
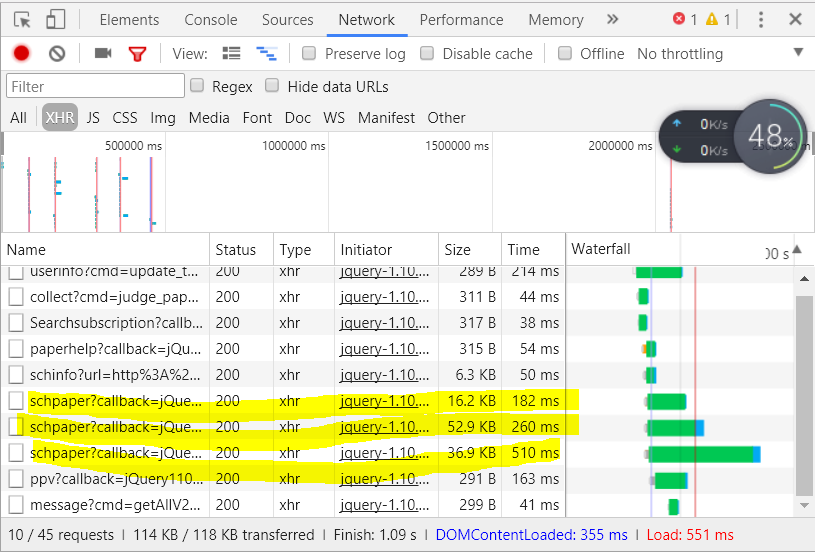
标记的三个对应了网站里面的相似文献、参考文献、引证文献,我们需要的是参考文献,所以点击第二个:
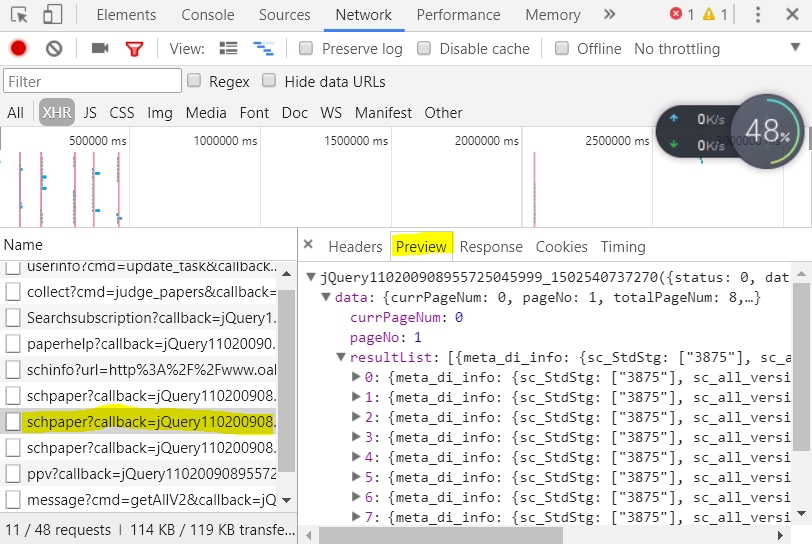
我们可以看到数据就在里面,然后点击Header,复制里面的URL:
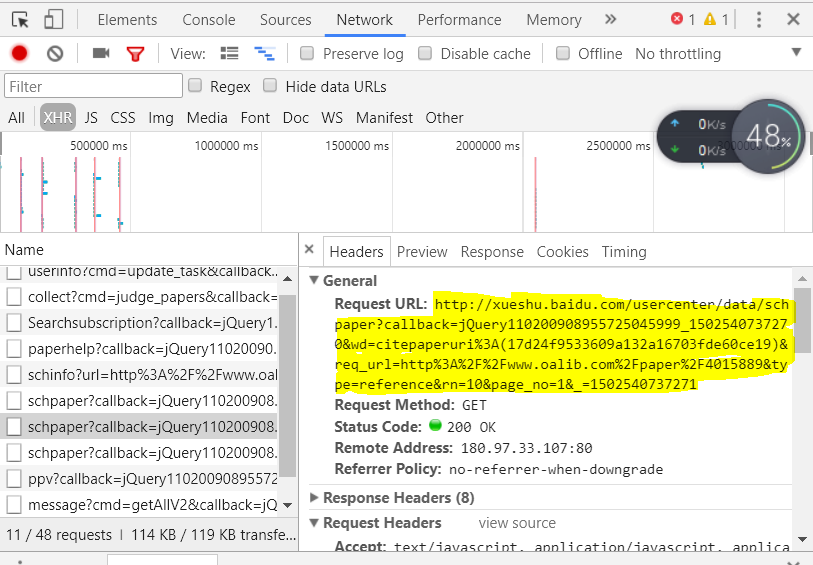
利用下面的代码就可以获取相应的数据了:
#-*- coding:utf-8 -*-
import requests
url='http://xueshu.baidu.com/usercenter/data/schpaper?callback=jQuery110208239584223582068_1502539053728&wd=citepaperuri%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2Fwww.oalib.com%2Fpaper%2F4015889&type=reference&rn=10&page_no=1'
data=requests.get(url)
print data
但是如果要获取所有的参考文献怎么办,我们不能一个链接一个链接的复制,那不就特别麻烦,下面是代码的改进,首先我们要知道总共有多少页参考文献,也就是URL里面的page_no的·值,以下为改进的代码:(其实我们也可以直接估计有50页参考文献,然后使用try。。。except。。。来获取异常也是可以的)
#-*- coding:utf-8 -*-
import requests n=相关页数
url='http://xueshu.baidu.com/usercenter/data/schpaper?callback=jQuery110208239584223582068_1502539053728&wd=citepaperuri%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2Fwww.oalib.com%2Fpaper%2F4015889&type=reference&rn=10&page_no='
for i in range(1,n+1):
data=requests.get(url+str(i))
print data
返回值是json格式的,剩下的就是处理json格式了(记得除去返回的多余数据),参见:http://www.cnblogs.com/ybf-yyj/articles/7351580.html。
以下贴上所有代码:
#-*- coding:utf-8 -*-
import requests
import re
import json def get_reference(url):
data=requests.get(url)
json_datas=data.content #使用贪婪算法的正则表达式获取json类型的字符串
json_data = re.compile(r"{.*}")
json_data = json_data.search(json_datas).group()
# 将获取的json字符串转化为字典
title_data=json.loads(json_data) n=title_data.get('data').get("resultList")
for i in range(0,len(n)):
try:
print 'reference:',
print n[i].get('meta_di_info').get('sc_title')[0]
for i in n[i].get('meta_di_info').get('sc_author'):
print i.get('sc_name')[1]+u',',
print '\n'
except:
print i n=4
url='http://xueshu.baidu.com/usercenter/data/schpaper?callback=jQuery110204974031490917943_1502604841329&wd=citepaperuri%3A(0689fe98fd34a1aac82d41225ad9ceca)&req_url=http%3A%2F%2Feuropepmc.org%2Fabstract%2Fmed%2F24235252&type=reference&rn=10&page_no='
for i in range(1,n+1):
get_reference(url+str(i))
python获取动态网站上面的动态加载的数据(初级)的更多相关文章
- python获取动态网站上面的动态加载的数据(selenium+Firefox)
最近突然想到以前爬取百度学术上的参考文献,大家可以看一下以前我的写的博客:http://www.cnblogs.com/ybf-yyj/p/7351493.html,但是如果利用这个方法,太痛苦了,需 ...
- Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢
- GitHub 网站上不去/加载慢/加载不全 解决办法
1. 当你打开你的 GitHub 2. F12 进入检查页面,点击 network 3. 找到变红的字段右键复制连接 4. 打开 DNS 查询网站,输入你复制的网址,点击查询 5. 选择国内的 ip ...
- Learning Spark中文版--第五章--加载保存数据(2)
SequenceFiles(序列文件) SequenceFile是Hadoop的一种由键值对小文件组成的流行的格式.SequenceFIle有同步标记,Spark可以寻找标记点,然后与记录边界重新 ...
- js动态创建的select2标签样式加载不上解决办法
js动态创建的select2标签样式加载不上:调用select2的select2()函数来初始化一下: js抛出了Uncaught query function not defined for Sel ...
- geotrellis使用(二十三)动态加载时间序列数据
目录 前言 实现方法 总结 一.前言 今天要介绍的绝对是华丽的干货.比如我们从互联网上下载到了一系列(每天或者月平均等)的MODIS数据,我们怎么能够对比同一区域不同时间的数据情况,采用 ...
- Echarts使用及动态加载图表数据
Echarts使用及动态加载图表数据 官网:http://echarts.baidu.com/ 1.文档 2.实例 名词: 1.统计维度(说明数据) 维度就是统计致力于建立一个基于多方位统计(时间.地 ...
- 使用 Cesium 动态加载 GeoJSON 数据
前言 需求是这样的,我需要在地图中显示 08 年到现在的地震情况,地震都是发生在具体的时间点的,那么问题就来了,如何实现地震情况按照时间动态渲染而不是一次全部加载出来. 一. 方案分析 这里面牵扯到两 ...
- ListView下拉刷新,上拉自动加载更多
下拉刷新,Android中非常普遍的功能.为了方便便重写的ListView来实现下拉刷新,同时添加了上拉自动加载更多的功能.设计最初是参考开源中国的Android客户端源码.先看示例图. ...
随机推荐
- js动态删除某一行,内容超出单元格后超出的部分用省略号代替
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <s ...
- Failed to place enough replicas
如果DataNode的dfs.datanode.data.dir全配置成SSD类型,则执行"hdfs dfs -put /etc/hosts hdfs:///tmp/"时会报如下错 ...
- css3种引入方式,样式与长度颜色,常用样式,css选择器
# CSS三种引入方式 ## 一.三种方式的书写规范 #### 1.行间式 ```html<div style="width: 100px; height: 100px; backgr ...
- c语言洗牌算法
#include<stdio.h> #include<stdlib.h> #include<time.h> #include<string.h> voi ...
- hihocoder 二分·二分答案【二分搜索,最大化最小值】 (bfs)
题目 这道题做了几个小时了都没有做出来,首先是题意搞了半天都没有弄懂,难道真的是因为我不打游戏所以连题都读不懂了? 反正今天是弄不懂了,过几天再来看看... 题意:一个人从1点出发到T点去打boss, ...
- Linux查看History记录加时间戳小技巧
Linux查看History记录加时间戳小技巧 熟悉bash的都一定知道使用history可以输出你曾经输入过的历史命令,例如[root@servyou_web ~]# history | more ...
- Spring中ApplicationEvent和ApplicationListener封装
1.测试程序EventTest.java,发布一个事件只需要调用FrameEventHolder.publishEvent()方法即可. package com.junge.spring.event; ...
- 基于Redis的CAS集群
单点登录(SSO)是复杂应用系统的基本需求,Yale CAS是目前常用的开源解决方案.CAS认证中心,基于其特殊作用,自然会成为整个应用系统的核心,所有应用系统的认证工作,都将请求到CAS来完成.因此 ...
- C#: 以管理员权限运行包含有cd命令的.bat文件
最近在做项目的时候遇到一种情:用C#程序以管理员权限去执行一个bat文件,且此bat文件里面有cd命令来进入文件的下一级目录,比如: echo test begin cd test1 setup1.e ...
- GridControl简单属性操作
1.单行记录整行选中 GridView->OptionsBehavior->EditorShowMode 设置为:Click 2.如何让行只能选择而不能编辑(或编辑某一单元格) 只读 Gr ...