python获取动态网站上面的动态加载的数据(初级)
我们在处理一些网站数据的时候,有时候我们需要的数据很多都是动态加载的,而不都是静态的,以下以一个实例来介绍简单的获取动态数据,首先申明本人小白,还在学习python中,这个方法还是比较笨拙的,但是对于初学者还是需要知道的。
首先我们的要求是获取下面文章的参考文献:
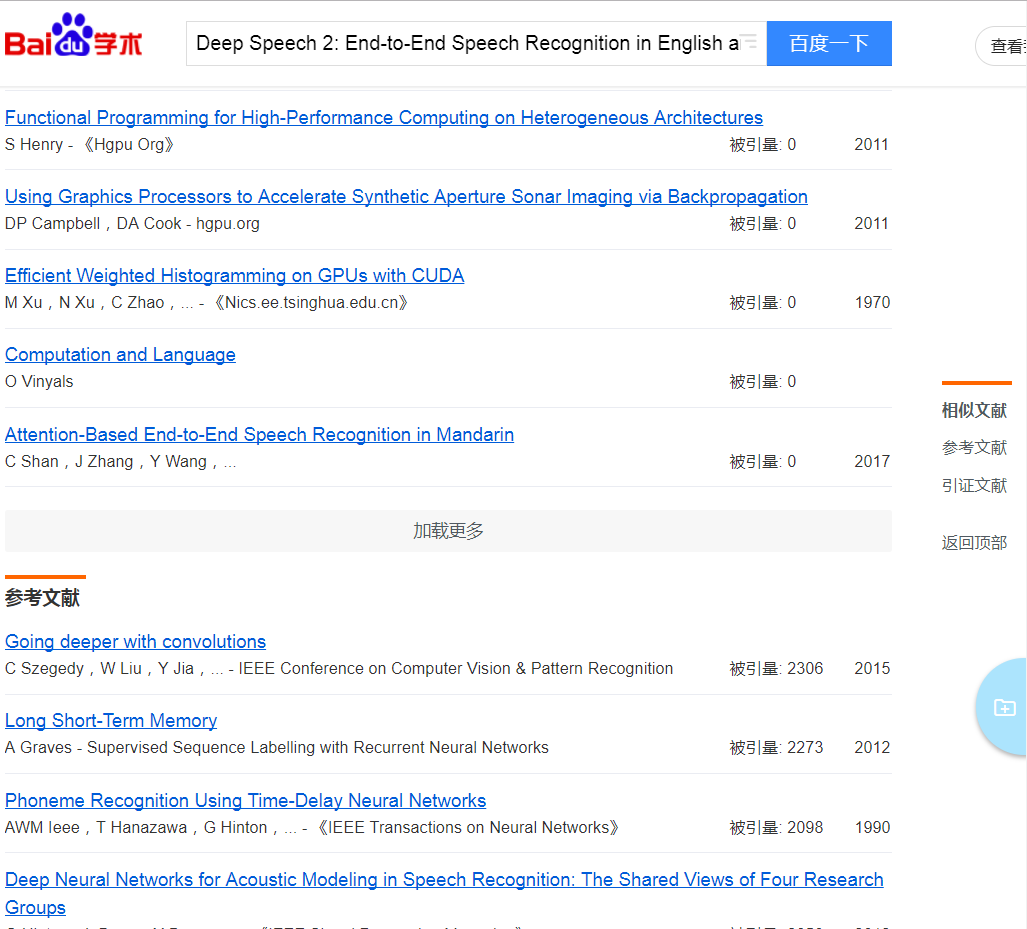
刚刚开始,我的想法是使用lxml、BeatifulSoup、正则表达式来处理,这几个是处理静态网站的常用方法,查看网页源码我们会发现相应的div里面是空,也就是说上面的数据不是静态的,而是后面动态加载的,利用googl浏览器可以看到:
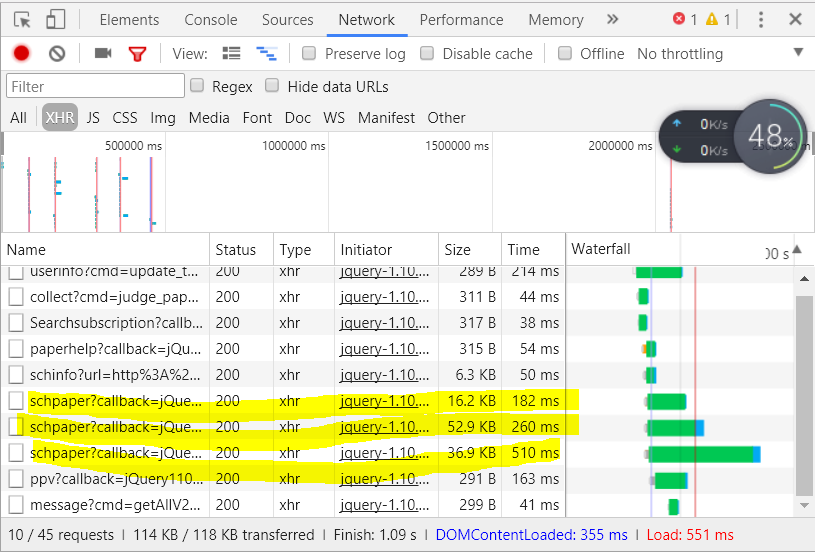
标记的三个对应了网站里面的相似文献、参考文献、引证文献,我们需要的是参考文献,所以点击第二个:
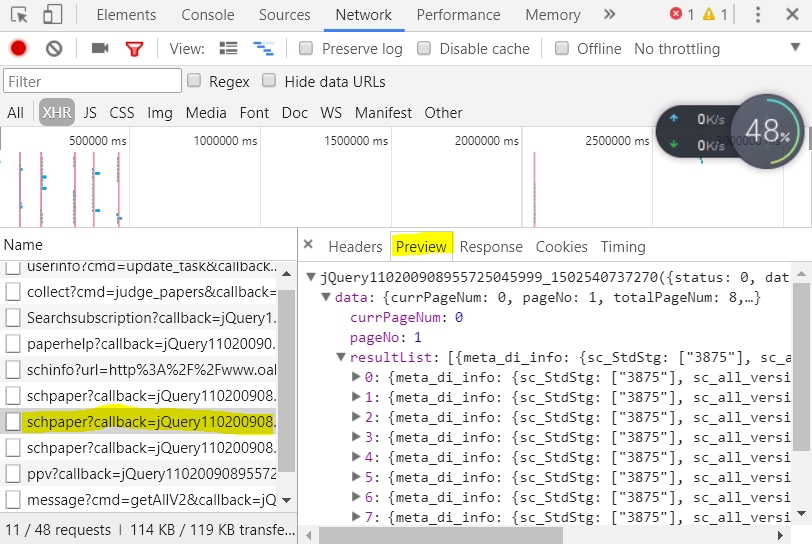
我们可以看到数据就在里面,然后点击Header,复制里面的URL:
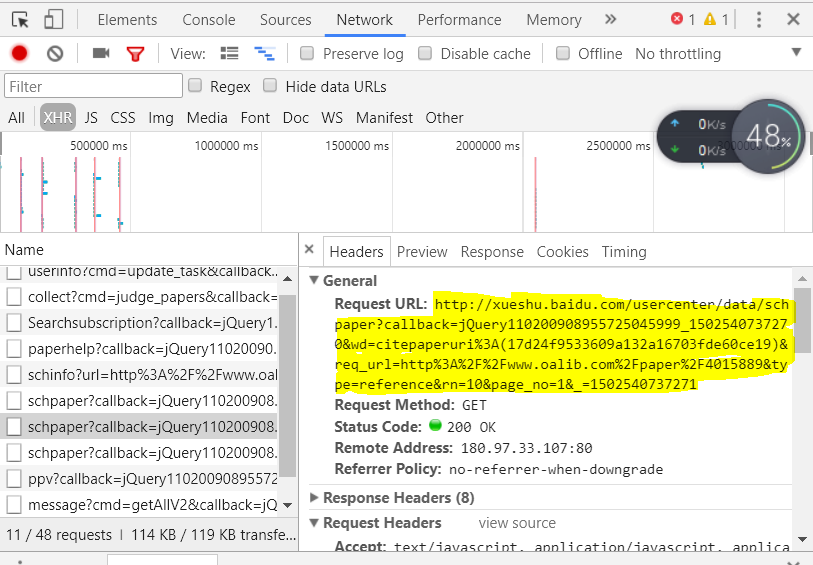
利用下面的代码就可以获取相应的数据了:
#-*- coding:utf-8 -*-
import requests
url='http://xueshu.baidu.com/usercenter/data/schpaper?callback=jQuery110208239584223582068_1502539053728&wd=citepaperuri%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2Fwww.oalib.com%2Fpaper%2F4015889&type=reference&rn=10&page_no=1'
data=requests.get(url)
print data
但是如果要获取所有的参考文献怎么办,我们不能一个链接一个链接的复制,那不就特别麻烦,下面是代码的改进,首先我们要知道总共有多少页参考文献,也就是URL里面的page_no的·值,以下为改进的代码:(其实我们也可以直接估计有50页参考文献,然后使用try。。。except。。。来获取异常也是可以的)
#-*- coding:utf-8 -*-
import requests n=相关页数
url='http://xueshu.baidu.com/usercenter/data/schpaper?callback=jQuery110208239584223582068_1502539053728&wd=citepaperuri%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2Fwww.oalib.com%2Fpaper%2F4015889&type=reference&rn=10&page_no='
for i in range(1,n+1):
data=requests.get(url+str(i))
print data
返回值是json格式的,剩下的就是处理json格式了(记得除去返回的多余数据),参见:http://www.cnblogs.com/ybf-yyj/articles/7351580.html。
以下贴上所有代码:
#-*- coding:utf-8 -*-
import requests
import re
import json def get_reference(url):
data=requests.get(url)
json_datas=data.content #使用贪婪算法的正则表达式获取json类型的字符串
json_data = re.compile(r"{.*}")
json_data = json_data.search(json_datas).group()
# 将获取的json字符串转化为字典
title_data=json.loads(json_data) n=title_data.get('data').get("resultList")
for i in range(0,len(n)):
try:
print 'reference:',
print n[i].get('meta_di_info').get('sc_title')[0]
for i in n[i].get('meta_di_info').get('sc_author'):
print i.get('sc_name')[1]+u',',
print '\n'
except:
print i n=4
url='http://xueshu.baidu.com/usercenter/data/schpaper?callback=jQuery110204974031490917943_1502604841329&wd=citepaperuri%3A(0689fe98fd34a1aac82d41225ad9ceca)&req_url=http%3A%2F%2Feuropepmc.org%2Fabstract%2Fmed%2F24235252&type=reference&rn=10&page_no='
for i in range(1,n+1):
get_reference(url+str(i))
python获取动态网站上面的动态加载的数据(初级)的更多相关文章
- python获取动态网站上面的动态加载的数据(selenium+Firefox)
最近突然想到以前爬取百度学术上的参考文献,大家可以看一下以前我的写的博客:http://www.cnblogs.com/ybf-yyj/p/7351493.html,但是如果利用这个方法,太痛苦了,需 ...
- Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢
- GitHub 网站上不去/加载慢/加载不全 解决办法
1. 当你打开你的 GitHub 2. F12 进入检查页面,点击 network 3. 找到变红的字段右键复制连接 4. 打开 DNS 查询网站,输入你复制的网址,点击查询 5. 选择国内的 ip ...
- Learning Spark中文版--第五章--加载保存数据(2)
SequenceFiles(序列文件) SequenceFile是Hadoop的一种由键值对小文件组成的流行的格式.SequenceFIle有同步标记,Spark可以寻找标记点,然后与记录边界重新 ...
- js动态创建的select2标签样式加载不上解决办法
js动态创建的select2标签样式加载不上:调用select2的select2()函数来初始化一下: js抛出了Uncaught query function not defined for Sel ...
- geotrellis使用(二十三)动态加载时间序列数据
目录 前言 实现方法 总结 一.前言 今天要介绍的绝对是华丽的干货.比如我们从互联网上下载到了一系列(每天或者月平均等)的MODIS数据,我们怎么能够对比同一区域不同时间的数据情况,采用 ...
- Echarts使用及动态加载图表数据
Echarts使用及动态加载图表数据 官网:http://echarts.baidu.com/ 1.文档 2.实例 名词: 1.统计维度(说明数据) 维度就是统计致力于建立一个基于多方位统计(时间.地 ...
- 使用 Cesium 动态加载 GeoJSON 数据
前言 需求是这样的,我需要在地图中显示 08 年到现在的地震情况,地震都是发生在具体的时间点的,那么问题就来了,如何实现地震情况按照时间动态渲染而不是一次全部加载出来. 一. 方案分析 这里面牵扯到两 ...
- ListView下拉刷新,上拉自动加载更多
下拉刷新,Android中非常普遍的功能.为了方便便重写的ListView来实现下拉刷新,同时添加了上拉自动加载更多的功能.设计最初是参考开源中国的Android客户端源码.先看示例图. ...
随机推荐
- VMware14 安装CentOS7及其配置;CentOS7配置网桥,做远程连接;
1.VMware14安装 进入百度链接,按照图形安装就好了.https://jingyan.baidu.com/article/9f7e7ec09da5906f281554d6.html ...
- 第07章:MongoDB-CRUD操作--文档--创建
①语法 insert() save() --有修改没有新增 insertOne() [3.2版本新增]向指定集合中插入一条文档数据 insertMany() [3.2版本新增]向指定集合中插入多条文 ...
- Java异常、事件、多线程
异常 捕捉异常,以便程序继续执行,同时可进行异常处理使程序更加健壮. Throwble类,派生Exception类和Error类,Exception类供应用程序用,Error类系统保留 ...
- 在Ubuntu上建立Arm Linux 开发环境
我使用的是友善2410的板子,以前都是用Fedora,现在家里的电脑被我转为Linux专用的了,装的是Ubuntu.但是嵌入式还是要玩的,在装载过程中也遇到一些小麻烦.在此记录一下,一来自己比较健忘, ...
- codeblocks+SDCC开发51单片机
说到51,大部分人都是用的是KEIL开发环境,但是KEIL是商业软件,我们一般人都用的是破解版的,如果用于商业就会收到法律诉讼.然而有一款很好的编译器专为51内核而存在.SDCC最大的有点就是开源免费 ...
- Beta阶段第六篇Scrum冲刺博客-Day5
1.站立式会议 提供当天站立式会议照片一张 2.每个人的工作 (有work item 的ID),并将其记录在码云项目管理中: 昨天已完成的工作. 张晨晨:完善收藏功能 郭琪容:收藏功能的实现 吴玲:完 ...
- 20155326 实验三 敏捷开发与XP实践
20155326 实验三 敏捷开发与XP实践 实验内容 XP基础 XP核心实践 相关工具 实验要求 1.没有Linux基础的同学建议先学习<Linux基础入门(新版)><Vim编辑器 ...
- Android webview 退出时关闭声音 4.视频全屏 添加cookie
全屏问题,可以参考 http://bbs.csdn.net/topics/390839259,点击 webView = (WebView) findViewById(R.id.webView); vi ...
- ASP.NET Web API 框架研究 核心的消息处理管道
ASP.NET Web API 的核心框架是一个由一组HttpMessageHandler有序组成的双工消息处理管道:寄宿监听到请求接受后,把消息传入该管道经过所有HttpMessageHandler ...
- git命令行的操作实例教程
Git 常用命令常用命令 创建新仓库 创建新文件夹,打开,然后执行 git init 1 以创建新的 git 仓库. 检出仓库 执行如下命令以创建一个本地仓库的克隆版本: git clone /pat ...