R实战 第八篇:重塑数据(reshape2)
数据重塑通常使用reshape2包,reshape2包用于实现对宽数据及长数据之间的相互转换,由于reshape2包不在R的默认安装包列表中,在第一次使用之前,需要安装和引用:
install.packages("reshape2")
library(reshape2)
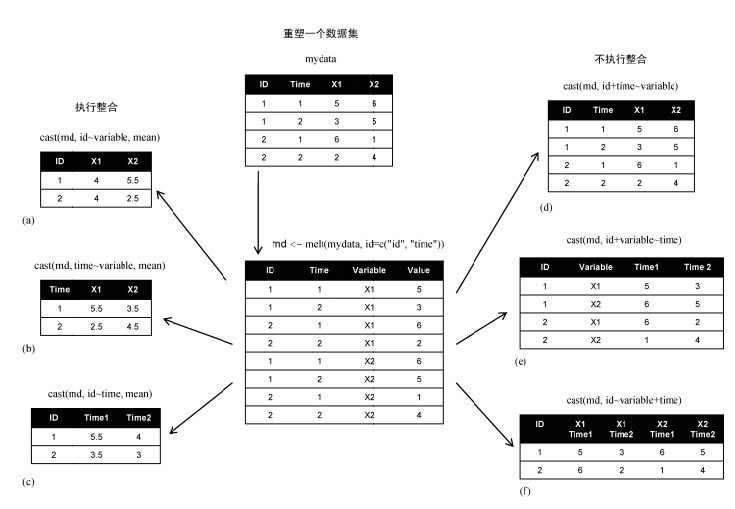
重塑数据,首先把宽数据融合(melt),以使每一行都只表示一个变量,然后把数据重塑(cast)为想要的任何形状。在重塑过程中,可以使用任何函数对数据进行整合,也可以把长格式转换为宽格式,这种操作类似于Excel的透视和逆透视。
一,认识宽数据
在同一行,标识变量(一列或多列)能够唯一标识两个或多个变量的值,这种数据显示叫做数据的宽格式,也叫做宽数据:

创建示例数据,ID和Time的组合是唯一的,X1和X2是该行的观测变量值,
> ID <- c(1,1,2,2)
> Time <- c(1,2,1,2)
> X1 <- c(5,3,6,2)
> X2 <-c(6,5,1,4)
> mydata <- data.frame(ID,Time,X1,X2)
如下所示宽格式的数据,ID和Time的组合是唯一的,同一行有两个变量X1和X2,通过ID和Time能够唯一确定变量X1和X2的值:
ID Time X1 X2
二,融合数据
数据的融合是指把数据集重塑为特定的格式,使得每个观测变量独占一行,每行都有唯一确定每个观测变量所需要的标识变量。融合之后的数据,称作长格式,也叫作长数据。
原始数据中,主键列唯一确定variable1和variable2的值,在融合之后,如下图所示,主键列和variable列(变量名)唯一确定value列的值。

在R语言中,使用melt()函数来融合数据:
melt(data,id.vars,measure.vars,variable.name='variable',...,na.rm=FALSE,value.name='value',factorAsStrings=TRUE)
参数注释:
- data:融合的数据框
- id.vars:由标识变量构成的向量,用于标识观测的变量
- measure.vars :由观测变量构成的向量
- variable.name:用于保存原始变量名的变量的名称
- value.name:用于保存原始值的名称
示例,标识变量是ID和Time,X1和X2作为观测变量:
md <- melt(mydata,id=c("ID","Time"),measure=c("X1","X2"))
数据融合之后,变成长数据,长数据的特征是 ID列(多列或单列)+ 变量名 唯一确定变量的值,并且每一行只能确定一个变量的值。
ID Time variable value
X1
X1
X1
X1
X2
X2
X2
X2
注意:必须指定唯一确定每个观测所需的变量(ID和Time),而表示观测变量名的变量(X1和X2)由程序自动创建,从结果中可以看出,函数自动创建了两个变量:variable和value,这两个变量名称是默认的,这可以在melt()函数中,通过参数 variable.name="new_variable_name"和 value.name="new_value_name"来自定义。
md <- melt(mydata,id=c("ID","Time"),measure=c("X1","X2"),variable.name = "MeasuredVariable",value.name = "IntValue")
三,重塑数据
dcast()函数用于读取已融合的数据框(d是指data frame),并使用formula和用于整合数据的函数把数据集重塑成任意形状:
dcast(data, formula, fun.aggregate = NULL, ..., margins = NULL,
subset = NULL, fill = NULL, drop = TRUE, value.var = guess_value(data))
参数注释:
- data:已融合的数据框
- formula:用于指定输出的结果集格式
- fun.aggregate:用于指定聚合函数,对已聚合的数据执行聚合运算
- margins:相当于透视表中的行总计和列总计
- subset:选取满足一些特定值的数据,相当于Excel透视表的筛选。例如, subset =.(variable ==“length”)
- fill:用于填充结构缺失的值,默认为将fun.aggregate应用于0长度向量的值
- value:value列的名称
参数formula的格式是:
rowvar1 + rowvar2 +... ~ colvar1 + colvar2 +...
在该公式中,rowvar 定义了保留的变量名,以唯一确定各行的内容;colvar定义了需要重塑的变量名,以确定各列的值。重塑的含义是:按照rowvar,展开colvar,对value进行聚合运算(当fun.aggregate为聚合函数时)。
1,展开colvar
展开colvar的过程,实际上是把列值转换为列名称的过程,这种展开操作是由formula参数决定的。
重塑操作中的特例是数据融合的逆操作,把数据的长格式转化为数据的宽格式,即,把已融合的数据转换为原始数据格式,对于这种操作,formula参数的格式是固定的:标识变量~variable。
> dcast(md,ID+Time~variable)
ID Time X1 X2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
2,对观测变量进行聚合运算
按照ID,计算观测变量的平均值:
> dcast(md,ID~variable,mean)
ID X1 X2
1 1 4 5.5
2 2 4 2.5
这种操作,类似于分组聚合:按照ID进行分组,分别计算变量X1和X2的聚合值。
3,添加总计列
计算按照ID分组的X1和X2的均值,并对重塑的结果按照ID计算各列均值,按照X1和X2计算各行的均值。
> dcast(md,ID~variable,mean,margins = c("ID","variable"))
ID X1 X2 (all)
5.5 4.75
2.5 3.25
(all) 4.0 4.00
计算的过程是:
按照ID计算各列的均值: X1的值是(5.5+2.5)/2=4
按照变量计算各行的均值:第一行的均值是 (4+5.5)/2=4.75
示例图:
参考文档:
R实战 第八篇:重塑数据(reshape2)的更多相关文章
- R实战 第六篇:数据变换(aggregate+dplyr)
数据分析的工作,80%的时间耗费在处理数据上,而数据处理的主要过程可以分为:分离-操作-结合(Split-Apply-Combine),也就是说,首先,把数据根据特定的字段分组,每个分组都是独立的:然 ...
- R实战 第三篇:数据处理(基础)
数据结构用于存储数据,不同的数据结构对应不同的操作方法,对应不同的分析目的,应选择合适的数据结构.在处理数据时,为了便于检查数据对象,可以通过函数attributes(x)来查看数据对象的属性,str ...
- Spring Cloud实战 | 最八篇:Spring Cloud +Spring Security OAuth2+ Axios前后端分离模式下无感刷新实现JWT续期
一. 前言 记得上一篇Spring Cloud的文章关于如何使JWT失效进行了理论结合代码实践的说明,想当然的以为那篇会是基于Spring Cloud统一认证架构系列的最终篇.但关于JWT另外还有一个 ...
- R实战 第三篇:数据处理
在实际分析数据之前,必须对数据进行清理和转化,使数据符合相应的格式,提高数据的质量.数据处理通常包括增加新的变量.处理缺失值.类型转换.数据排序.数据集的合并和获取子集等. 一,增加新的变量 通常需要 ...
- R实战 第五篇:绘图(ggplot2)
ggplot2包实现了基于语法的.连贯一致的创建图形的系统,由于ggplot2是基于语法创建图形的,这意味着,它由多个小组件构成,通过底层组件可以构造前所未有的图形.ggplot2可以把绘图拆分成多个 ...
- R实战 第七篇:绘图文本表
文本表是显示数据的重要图形,一个文本表按照区域划分为:列标题,行标题,数据区,美学特征有:前景样式.背景央视.字体.网格线等. 一,使用ggtexttable绘图文本表 载入ggpubr包,可以使用g ...
- R实战 第十一篇:处理缺失值
在真实的世界中,缺失数据是经常出现的,并可能对分析的结果造成影响.在R中,经常使用VIM(Visualization and Imputation of Missing values)包来对缺失值进行 ...
- R绘图 第八篇:绘制饼图(ggplot2)
geom_bar()函数不仅可以绘制条形图,还能绘制饼图,跟绘制条形图的区别是坐标系不同,绘制饼图使用的坐标系polar,并且设置theta="y": coord_polar(th ...
- R实战 第十篇:列联表和频数表
列联表是观测数据按两个或更多属性(定性变量)分类时所列出的频数分布表,它是由两个以上的变量进行交叉分类的频数分布表.交互分类的目的是将两变量分组,然后比较各组的分布状况,以寻找变量间的关系. 按两个变 ...
随机推荐
- ionic默认样式android和ios差异
ionicframework中android和ios在默认样式上有一些不同的地方,官方文档中都有说明,但是经常会想不起. 一.差异: 1.tab位置,$ionicConfigProvider, tab ...
- sql server对并发的处理-乐观锁和悲观锁(转)
假如两个线程同时修改数据库同一条记录,就会导致后一条记录覆盖前一条,从而引发一些问题. 例如: 一个售票系统有一个余票数,客户端每调用一次出票方法,余票数就减一. 情景: 总共300张票,假设两个售票 ...
- 为何使用Microsoft SQL Server Management Studio连接Integration Services服务失败
检查是否满足以下各项: 1. 首先你要确保当前你使用的Windows账号是有管理员权限的 2. 其次请在打开Microsoft SQL Server Management Studio时,通过右键Ru ...
- sql server 时间格式转换
sql server2000中使用convert来取得datetime数据类型样式(全) 日期数据格式的处理,两个示例: CONVERT(varchar(16), 时间一, 20) 结果:2007-0 ...
- Android external扩展工程
Android的扩展工程包含在external文件夹中,这是一些经过修改后适应Android系统的开源工程,这些工程有些在主机上运行,有些在目标机上运行: 工程名称 工程描述 aes 高级加密标 ...
- 理解lua中 . : self
前言 在LUA中,经常可以看到:. self,如果你学习过Java或C#语言,可以这样理解 .对于c#和java的静态方法 :相当于是实例方法 今天在CSDN上看到一篇博客写的很清楚,转载过来 原文出 ...
- crontab 命令使用
什么是crontab? crontab命令常见于Unix和类Unix的操作系统之中,用于设置周期性被执行的指令.该命令从标准输入设备读取指令,并将其存放于“crontab”文件中,以供之后读取和执行. ...
- 【爬坑】Vim 文档加密 & 解密
0. 说明 在 Vim 使用过程中,最后保存的时候输入了 :X ,提示输入密码,输完密码发现以前没遇到类似情况. 有时候最后保存那会儿默认大写. 在网上一查发现原来给文件加密了,就顺带搜索怎么取消密 ...
- [Python_4] Python 面向对象(OOP)
0. 说明 Python 面向对象(OOP) 笔记.迭代磁盘文件.析构函数.内置方法.多重继承.异常处理 参考 Python面向对象 1. 面向对象 # -*-coding:utf-8-*- &quo ...
- SDN2017 第四次实验作业
实验目的 1.使用图形化界面搭建拓扑如下并连接控制器 2.使用python脚本搭建拓扑如下并通过命令行连接控制器 3.使用任一种方法搭建拓扑连接控制器后下发流表 实验步骤 建立以下拓扑,并连接上ODL ...