python3获取一个网页特定内容
我们今天要爬取的网址为:https://www.zhiliti.com.cn/html/luoji/list7_1.html
一、目标:获取下图红色部分内容
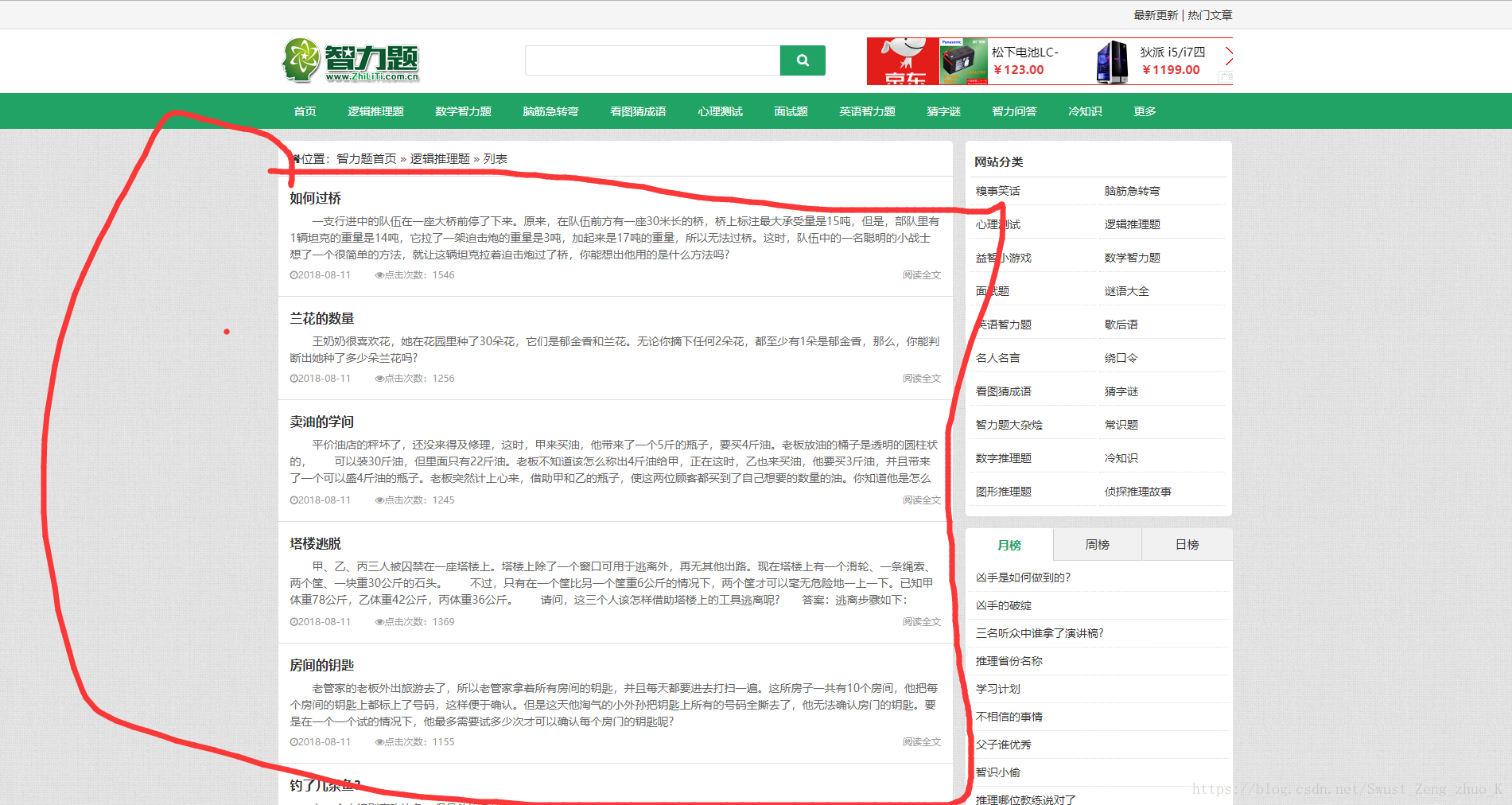
即获取所有的题目以及答案。
二、实现步骤。
分析:
1,首先查看该网站的结构。
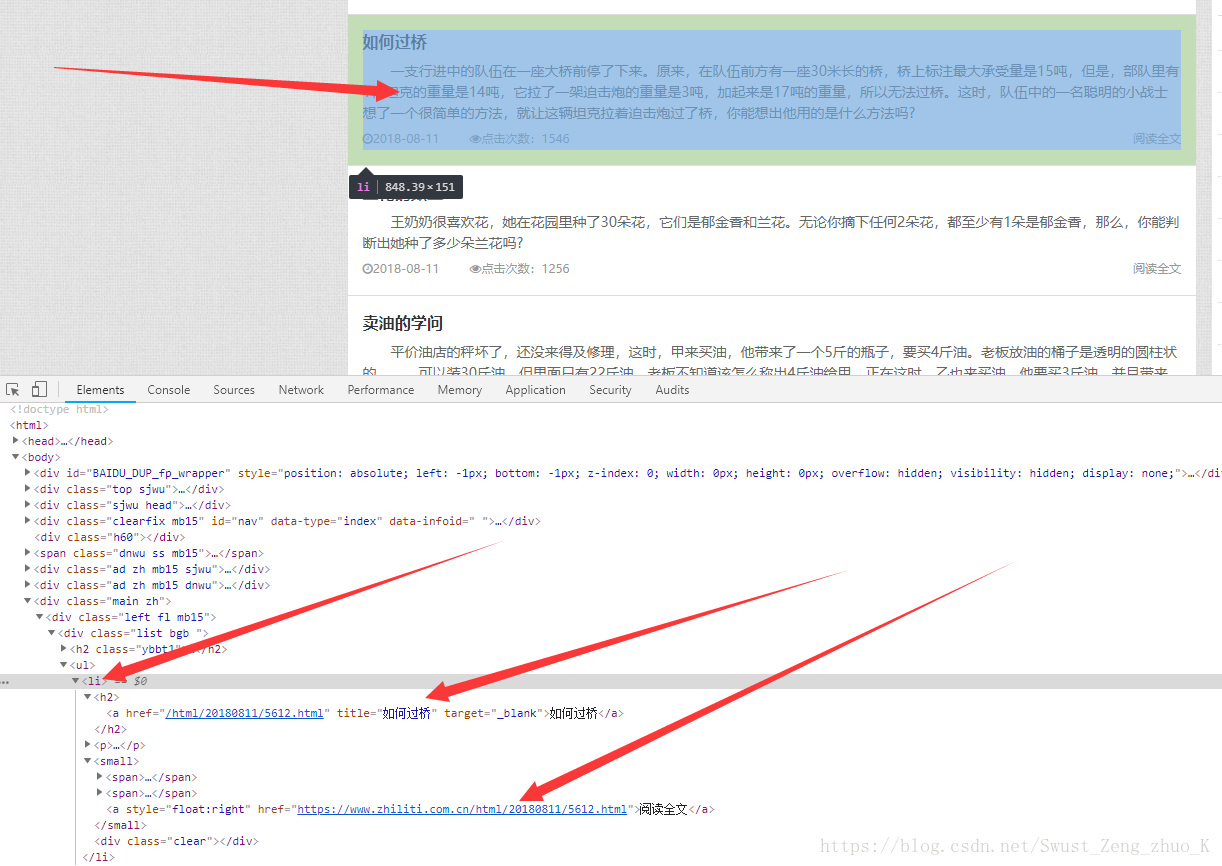
分析网页后可以得到:
我们需要的内容是在该网页<li>标签下,详细内容链接在<small>的<a>的href中。
但是这样我们最多只能获取这一页的内容
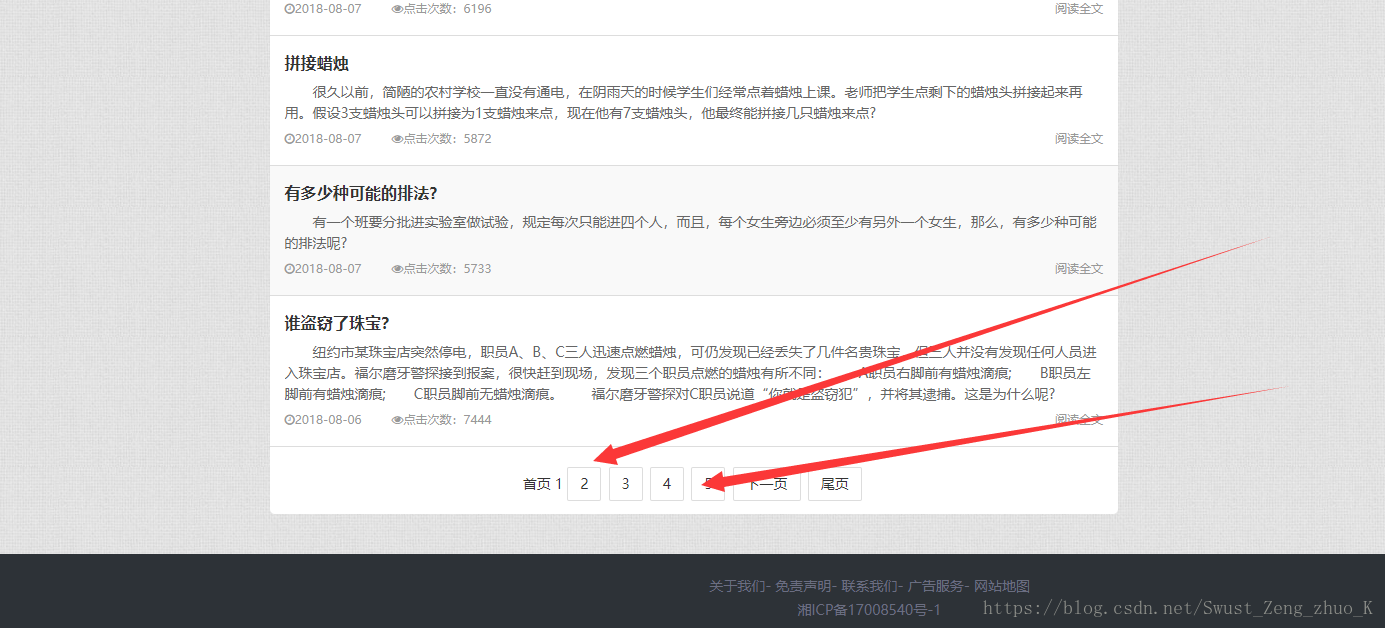
别着急
我们点击第二页看一下目标网址有什么变化
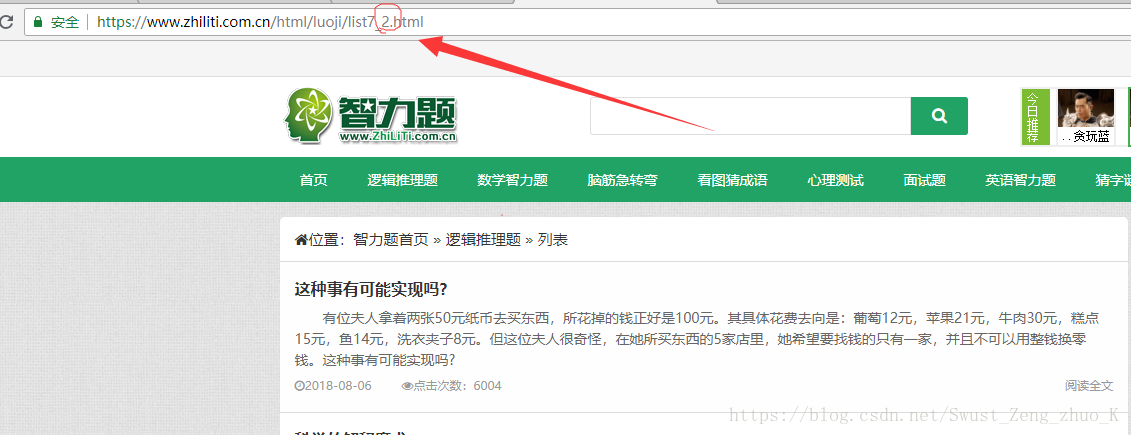
我们发现目标网址最后的数字变成了2
再看一下最后一页
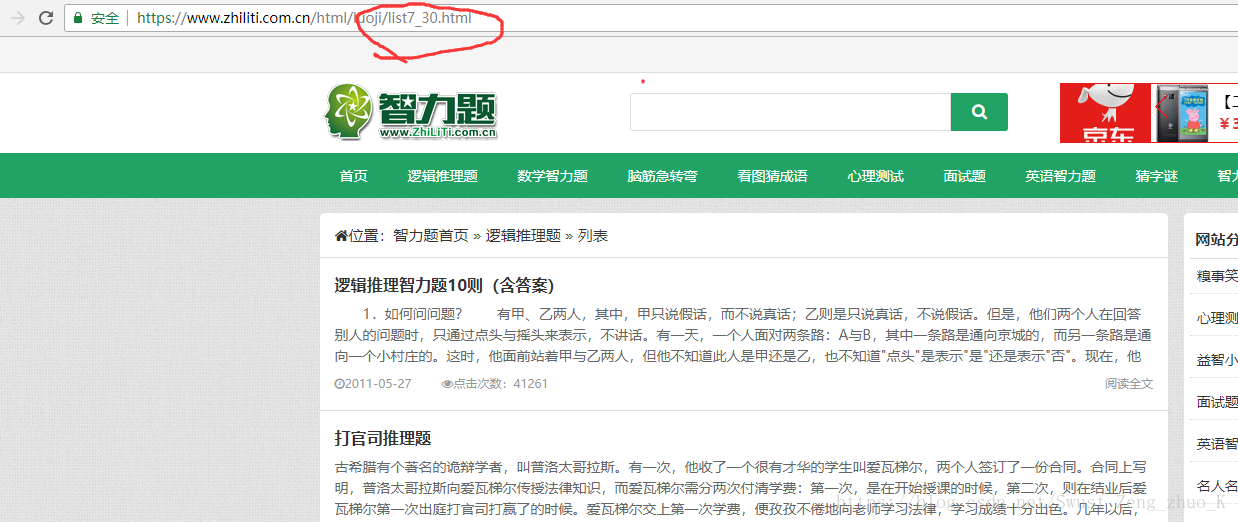
我们可以分析出最后那个数字即第几页,所以我们待会可以直接用一个for循环拼接字符串即可。
分析详细页面:
我们随便点击进入一个阅读全文
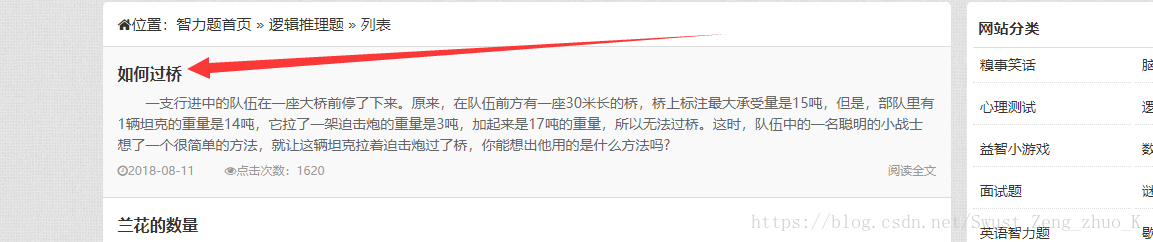
同样分析网页结构。
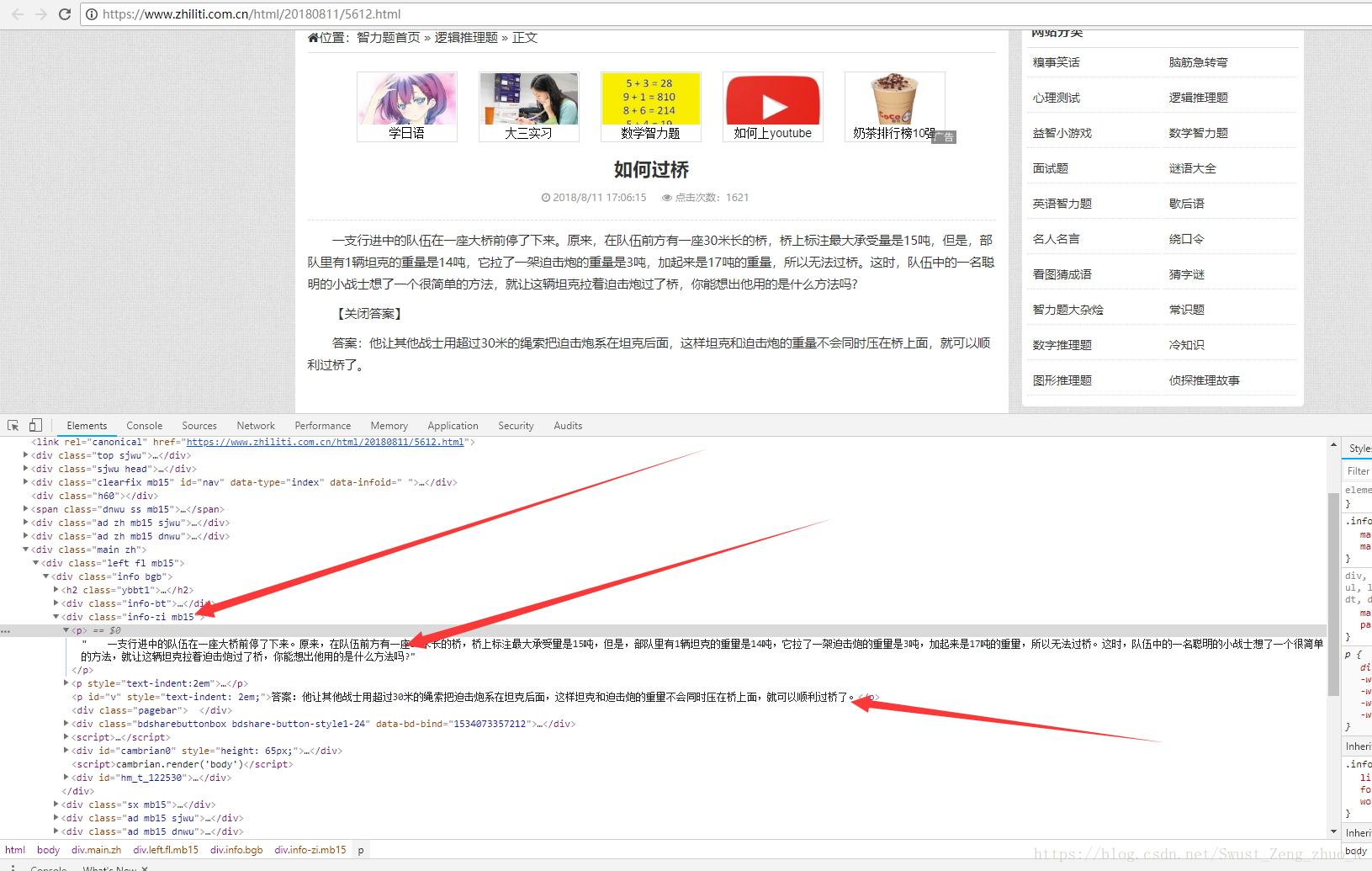
发现我们要的内容在一个块<div class="info-zi mb15"/>的<p>标签中,我们在看一下其他题是不是也是这样的
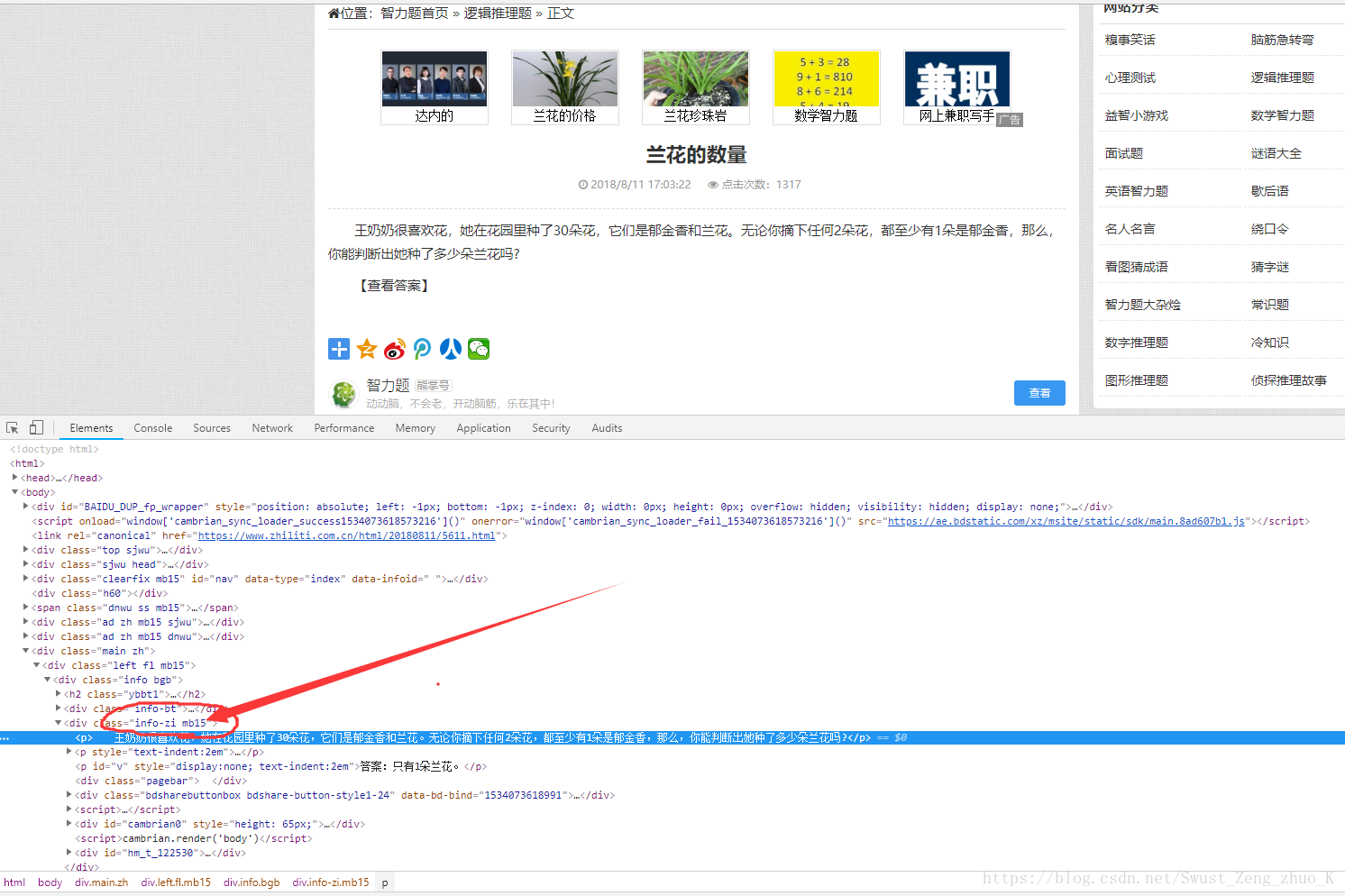
很明显是这样的,所以我们只需要获取class为info-zi mb15下的<p>标签下的内容即可。
所以我们接下来开始实现。
Let's Go
实现:
1,获取所有页
def getall():
for i in range(1,31,1):
getalldoc(i)
i表示第i页,一共30页所以i从1变化到30,每次增加1。
2,获取当前页详细页面的连接
#获取目标网址第几页
def getalldoc(ii):
#字符串拼接成目标网址
testurl = "https://www.zhiliti.com.cn/html/luoji/list7_"+str(ii)+".html"
#使用request去get目标网址
res = requests.get(testurl,headers=headers)
#更改网页编码--------不改会乱码
res.encoding="GB2312"
#创建一个BeautifulSoup对象
soup = BeautifulSoup(res.text,"html.parser")
#找出目标网址中所有的small标签
#函数返回的是一个list
ans = soup.find_all("small")
#用于标识问题
cnt = 1
#先创建目录
mkdir("E:\\Python爬取的文件\\问题\\第" + str(ii) + "页\\")
for tag in ans:
#获取a标签下的href网址
string_ans=str(tag.a.get("href"))
#请求详细页面
#返回我们需要的字符串数据
string_write = geturl(string_ans)
#写文件到磁盘
writedoc(string_write,cnt,ii)
cnt = cnt+1
print("第",ii,"页写入完成")
先拼接处目标网页url,然后调用request去请求,更改网页编码,使用BeautifulSoup对html文档进行解析,找出所有<small>标签,存入一个list,然后遍历该list,获取每一个<small>标签里的<a>标签的href属性,并将其转换为字符串string_ans。
得到详细页面的url之后我们调用geturl(自定义函数下面讲解)返回我们所需要的题目字符串,最后调用writedoc写入文件。
3,得到详细页面的url后筛选目标字符串
#根据详细页面url获取目标字符串
def geturl(url):
#请求详细页面
r = requests.get(url, headers=headers)
#改编码
r.encoding = "GB2312"
soup = BeautifulSoup(r.text, "html.parser")
#找出类名为 info-zi mb15 下的所有p标签
ans = soup.find_all(["p", ".info-zi mb15"])
#用来储存最后需要写入文件的字符串
mlist = ""
for tag in ans:
#获取p标签下的string内容,并进行目标字符串拼接
mlist=mlist+str(tag.string)
#返回目标字符串
return mlist
首先请求网页构建一个BeautifulSoup对象,筛选出class=info-zi mb15的对象下的<p>标签内容,返回类型为list,遍历list,将每个item的string拼接到目标字符串并返回。
4,将目标字符串写进文件
#写文件
def writedoc(ss, i,ii):
#打开文件
#编码为utf-8
with open("E:\\Python爬取的文件\\问题\\第" + str(ii) + "页\\"+"问题" + str(i) + ".txt", 'w', encoding='utf-8') as f:
#写文件
f.write(ss)
print("问题" + str(i) + "文件写入完成" + "\n")
5,创建指定目录
def mkdir(path):
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已存在
return False
三,最终python文件
import requests
from bs4 import BeautifulSoup
import os # 服务器反爬虫机制会判断客户端请求头中的User-Agent是否来源于真实浏览器,所以,我们使用Requests经常会指定UA伪装成浏览器发起请求
headers = {'user-agent': 'Mozilla/5.0'} #写文件
def writedoc(ss, i,ii):
#打开文件
#编码为utf-8
with open("E:\\Python爬取的文件\\问题\\第" + str(ii) + "页\\"+"问题" + str(i) + ".txt", 'w', encoding='utf-8') as f:
#写文件
f.write(ss)
print("问题" + str(i) + "文件写入完成" + "\n") #根据详细页面url获取目标字符串
def geturl(url):
#请求详细页面
r = requests.get(url, headers=headers)
#改编码
r.encoding = "GB2312"
soup = BeautifulSoup(r.text, "html.parser")
#找出类名为 info-zi mb15 下的所有p标签
ans = soup.find_all(["p", ".info-zi mb15"])
#用来储存最后需要写入文件的字符串
mlist = ""
for tag in ans:
#获取p标签下的string内容,并进行目标字符串拼接
mlist=mlist+str(tag.string)
#返回目标字符串
return mlist #获取目标网址第几页
def getalldoc(ii):
#字符串拼接成目标网址
testurl = "https://www.zhiliti.com.cn/html/luoji/list7_"+str(ii)+".html"
#使用request去get目标网址
res = requests.get(testurl,headers=headers)
#更改网页编码--------不改会乱码
res.encoding="GB2312"
#创建一个BeautifulSoup对象
soup = BeautifulSoup(res.text,"html.parser")
#找出目标网址中所有的small标签
#函数返回的是一个list
ans = soup.find_all("small")
#用于标识问题
cnt = 1
#先创建目录
mkdir("E:\\Python爬取的文件\\问题\\第" + str(ii) + "页\\")
for tag in ans:
#获取a标签下的href网址
string_ans=str(tag.a.get("href"))
#请求详细页面
#返回我们需要的字符串数据
string_write = geturl(string_ans)
#写文件到磁盘
writedoc(string_write,cnt,ii)
cnt = cnt+1
print("第",ii,"页写入完成") def mkdir(path):
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已存在
return False def getall():
for i in range(1,31,1):
getalldoc(i) if __name__ == "__main__":
getall()
四,运行结果
五,总结
一般网页的编码为utf-8编码,但是这个网页就不一样编码为GB2312,我第一次请求返回的是乱码,如果python向一个不存在的目录进行写文件会报错,所以写文件之前要先判断路径是否正确存在,不存在就要创建路径,请求头请使用下面这个
# 服务器反爬虫机制会判断客户端请求头中的User-Agent是否来源于真实浏览器,所以,我们使用Requests经常会指定UA伪装成浏览器发起请求
headers = {'user-agent': 'Mozilla/5.0'}
python3获取一个网页特定内容的更多相关文章
- Python 网络爬虫 009 (编程) 通过正则表达式来获取一个网页中的所有的URL链接,并下载这些URL链接的源代码
通过 正则表达式 来获取一个网页中的所有的 URL链接,并下载这些 URL链接 的源代码 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 ...
- 如何查看一个网页特定效果的js代码(动画效果可js和css)(页面可以看到js的源代码)
如何查看一个网页特定效果的js代码(动画效果可js和css)(页面可以看到js的源代码) 一.总结 1.动画效果可能是 CSS 实现的,也可能是 JS 实现的. 2.直接Chrome的F12调试即可, ...
- 用TcpClient如何获取远程网页的内容
用TcpClient如何获取远程网页的内容 private string GetHTMLTCP(string URL) { string strHTML = "";//用来保存获得 ...
- 利用cURL会话获取一个网页
1.curl_init 作用: 初始化一个新的会话.返回一个cURL句柄,供curl_setopt(), curl_exec()和curl_close() 函数使用. 格式: curl_ ...
- 我最近用Python写了一个算法,不需要写任何规则就能自动识别一个网页的内容
我最近用Python写了一个算法,不需要写任何规则就能自动识别一个网页的内容,目前测试了300多个新闻网站的新闻页,都能准确识别
- 你知道怎么从jar包里获取一个文件的内容吗
目录 背景 报错的代码 原先的写法 编写测试类 找原因 最终代码 背景 项目里需要获取一个excle文件,然后对其里的内容进行修改,这个文件在jar包里,怎么尝试都读取不成功,但是觉得肯定可以做到,因 ...
- [skill][telnet] 用telnet获取一个网页
一直也搞不懂, telnet到底是干嘛用的. 然而, 它可以得到一个网页. /home/tong/Data/performance_test [tong@T7] [:] > telnet nyu ...
- python3 保存一个网页为html文件
我使用的python版本为3.5.2. 最近租房子,恨透了中介,想绕过中介去租.结果发现豆瓣同城里有好多二房东,感觉人都还不错.但是豆瓣这里没有信息检索的功能,只能人工地看房子的地址,非常地不方便.所 ...
- 简单的Java网络爬虫(获取一个网页中的邮箱)
import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; impo ...
随机推荐
- 移动一根火柴使等式成立js版本(递归)
修改成递归版本 思路: 1.设定规则数组,比如:1加一根火柴只可以变成7. 2.设定方法数组,比如:一个数增加了一根火柴,其他的数必然减少一根火柴. 3.增加Array方法,由元素名和方法,得到规则对 ...
- google浏览器高清壁纸保存
谷歌浏览器 扩展程序里边 有一个主题壁纸 好多不错的,并且是高清大图!!! 主题应用市场: https://chrome.google.com/webstore/category/themes?hl= ...
- apt 下载安装包
1) Try both without sudo, apt-get download will pass and apt-get -d install will fail (root required ...
- C++与C的联系与区别
C++与C的联系: C++是在C语言的基础上开发的一种面向对象编程语言,应用广泛.C++支持多种编程范式 --面向对象编程.泛型编程和过程化编程. 其编程领域众广,常用于系统开发,引擎开发等应用领域, ...
- url最后的“/”是什么作用
多了个尾巴 有时候,当你尝试在地址栏输入https://123/demo的时候,会发现浏览器会重定向到https://123/demo/这个地址,也就是多了个/,发生了重定向.有图为证: 上面这个图是 ...
- 第k大的数
问题描述:输入一组数,指定一个k,输出这组数里第k大的数. 一般这种题目,第一想法是把整个数组先排序后,再选取第k位的数.但是这样做实际上浪费了大量的时间在排序上,我们只是要求第k大的数,并非要把整个 ...
- Mysql - 增量脚本中修改字段属性
在增量部署系统的时候, 经常需要提供增量修改的脚本, 如果是修改存储过程或者自定义函数, 那还是很好改的, 不用担心表功能收到影响. 如果是改字段呢? 首先不知道字段是不是已经在系统里面, 没有的话, ...
- Tomcat学习总结(13)—— Tomcat常用参数配置说明
1.修改端口号 Tomcat端口配置在server.xml文件的Connector标签中,默认为8080,可根据实际情况修改. 修改端口号 2.解决URL中文参数乱码 在server.xml文件的Co ...
- 【Vue】v-if与v-show的区别
相同点:v-if与v-show都可以动态控制dom元素显示隐藏 不同点:v-if显示隐藏是将dom元素整个添加或删除,而v-show隐藏则是为该元素添加css--display:none,dom元素还 ...
- VMware12 克隆虚拟机并且重新分配ip、mac
记录如何快速拷贝一台虚拟机,并且重新分配IP.mac等方便自己做实验: 环境:VMWare12 .Redhat6.8 Step1.克隆虚拟机 虚拟机处于未打开状态,右击管理—>克隆 弹出克隆界 ...