Hadoop集群初步搭建:
自己整理了一下Hadoop集群简易搭建的过程,感谢尚观科技贾老师的授课和指导!
基本环境要求:能联网电脑一台;装有Centos系统的VMware虚拟机;Xmanager Enterprise 5软件。
•规划集群的ip地址:(计划)
10.10.10.31-->uplooking01
10.10.10.32-->uplooking02
10.10.10.33-->uplooking03
•克隆2个虚拟机:(在VMware里操作)
- 右击将uplooking重命名为uplooking01;
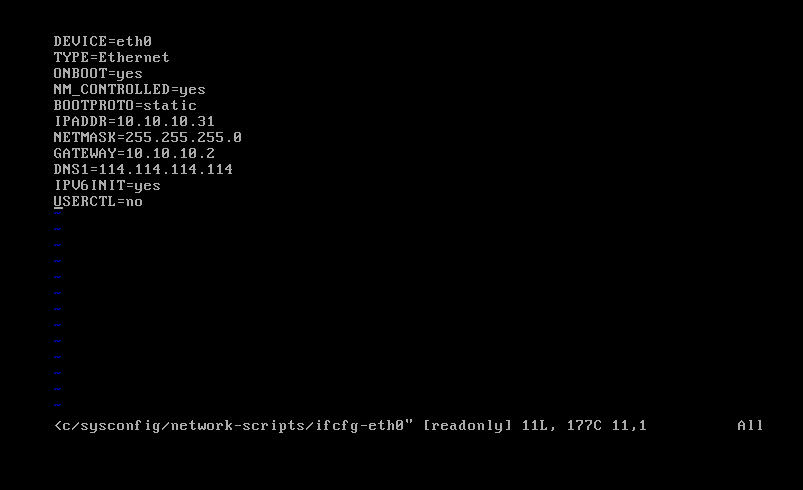
- 打开uplooking01虚拟机,输入指令vim /etc/sysconfig/network-scripts/ifcfg-eth0 将IP地址设置为10.10.10.31
- 虚拟机系统管理->右键克隆->完整克隆->uplooking02、uplooking03
•配置克隆机主机名:(以下操作均可在XShell中进行!)
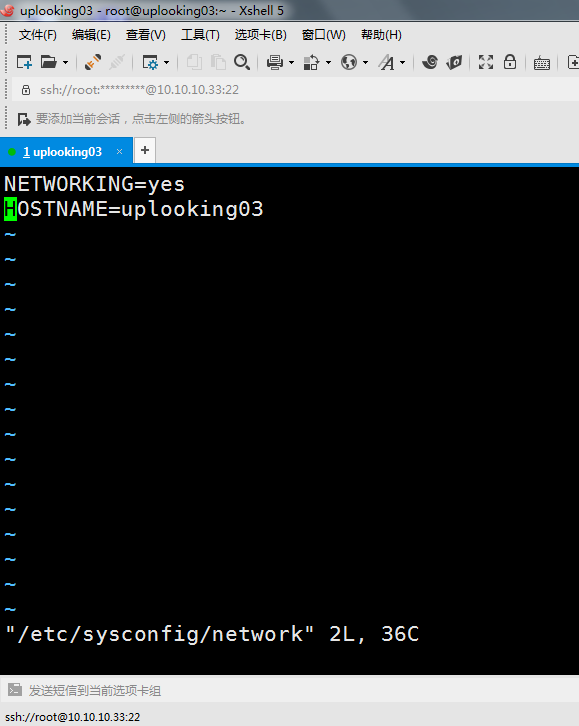
uplooking02和03机下分别输入指令vim /etc/sysconfig/network
将HOSTNAME改为uplooking02、uplooking03
•修改克隆机网络配置:
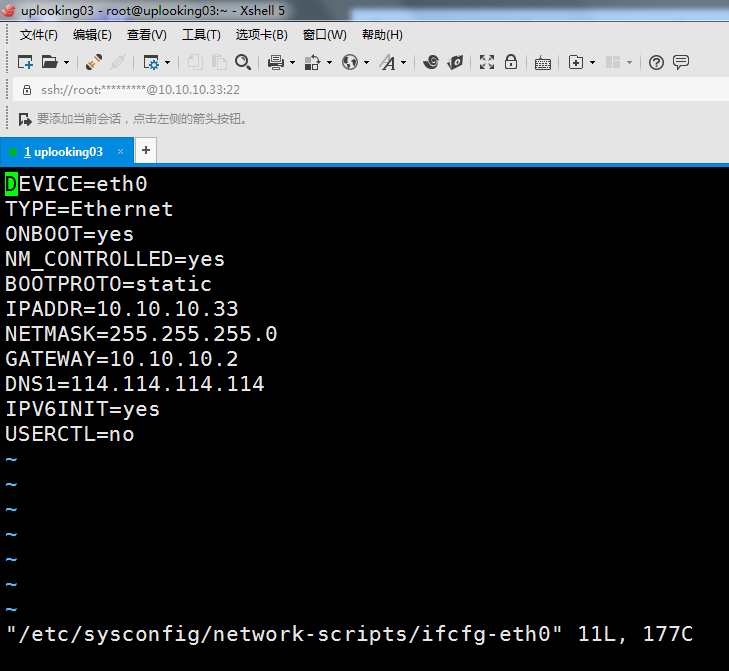
uplooking02和03机下分别输入指令vim /etc/sysconfig/network-scripts/ifcfg-eth0
删去HWADDR、UUID行;
IP地址行分别改为10.10.10.32、10.10.10.33。
•解决克隆机网卡名称变为eth1问题:
uplooking02和03机下分别输入指令rm -rf /etc/udev/rules.d/70-persistent-net.rules
重启reboot。
•配置物理机和虚拟机之间的映射:
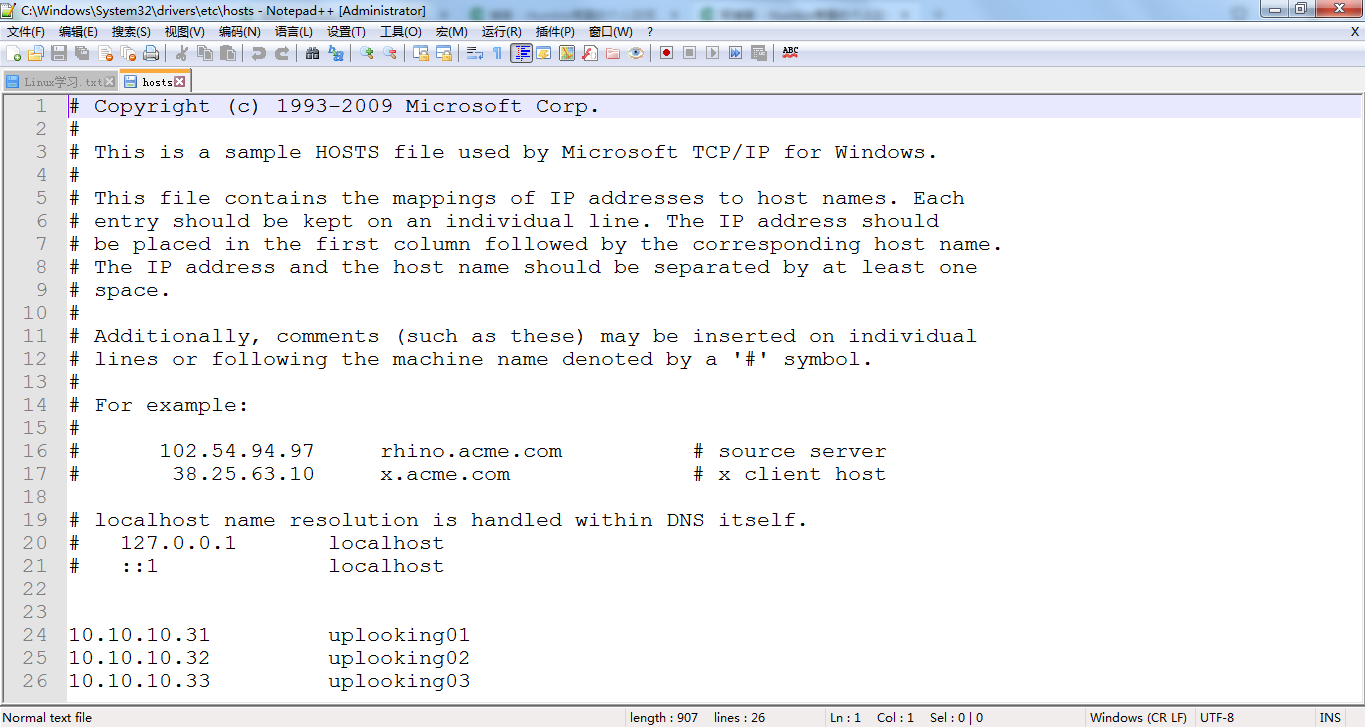
C:\Windows\System32\drivers\etc\hosts 文件,添加并保存
10.10.10.31 uplooking01
10.10.10.32 uplooking02
10.10.10.33 uplooking03
•配置虚拟机之间的映射:
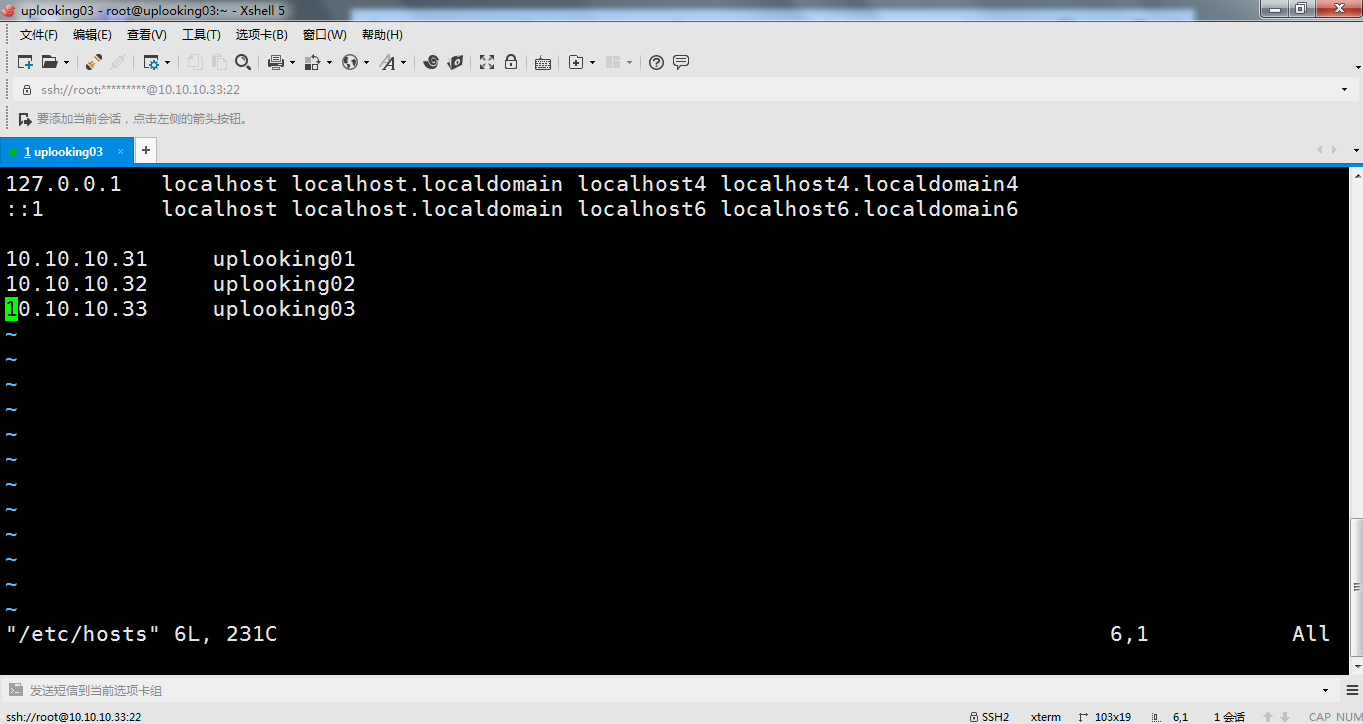
uplooking01、02和03机下分别输入指令vim /etc/hosts 添加并保存
10.10.10.31 uplooking01
10.10.10.32 uplooking02
10.10.10.33 uplooking03
•关闭防火墙:
关闭网络防火墙:service iptables stop
关闭防火墙的开机自启:chkconfig iptables off
关闭selinux(Linux访问权限管理系统)服务:vim /etc/selinux/config SELINUX=disabled
开启时间同步服务器:service ntpd start
设置时间同步服务器开机自启:chkconfig ntpd on
•uplooking01免密码登录到uplooking02与uplooking03
1>生成公钥和私钥 ssh-keygen -t rsa
2>把自己的公钥文件(~/.ssh/id_rsa.pub)追加到需要
免密码登录的主机的认证文件(~/.ssh/authorized_keys)中
ssh-copy-id root@uplooking01
ssh-copy-id root@uplooking02
ssh-copy-id root@uplooking03
scp ~/.ssh/authorized_keys
•安装jdk:
先查询本机是否安装了jdk如果安装了先卸载:rpm -qa | grep jdk
查看当前Java版本: java -version
在uplooking01上进行操作:
①mkdir /software (在/目录下创建software文件夹)
②上传jdk的安装包到linux主机下的的 /software (Ctrl+Alt+F新建文件传输)
③tar -zxvf jdk-8u172-linux-x64.tar.gz -C /opt/ (解压安装包,先cd进software)
④mv jdk1.8.0_172/ jdk (重命名为jdk)
⑤配置环境变量
vim /etc/profile添加
export JAVA_HOME=/opt/jdk
export PATH=$PATH:$JAVA_HOME/bin
⑥使环境变量立刻生效
source /etc/profile
⑦远程发送uplooking01上已安装好的jdk和环境变量的配置
scp -r /opt/jdk root@uplooking02:/opt
scp -r /opt/jdk root@uplooking03:/opt
scp /etc/profile root@uplooking02:/etc/
scp /etc/profile root@uplooking03:/etc/
•安装mysql用于存储元信息:
在uplooking03操作:
首先查看是否安装了mysql,如果安装了先卸载:
rpm -qa|grep mysql
rpm -e mysql-libs-5.1.71-1.el6.x86_64 --nodeps
yum -y install mysql-server
service mysqld start
登录到mysql: mysql -uroot –p
修改mysql的密码: set password=password("root")
修改权限:
use mysql
delete from
delete from user where password = '‘;
update user set host='%' ;
flush privileges;
设置/proc/sys/vm/swappiness为0:(三台虚拟机都做)
vim /etc/sysctl.conf 添加并保存 vm.swappiness=0
重启或激活:sysctl –p
•关闭THP(所有机器都做):
透明大页的开启,同样会消耗掉大量的内容,(包括HDP和CDH)建议将其关闭,添加进/etc/rc.local
echo never>/sys/kernel/mm/redhat_transparent_hugepage/defrag
echo never >/sys/kernel/mm/redhat_transparent_hugepage/enabled
echo never>/sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
好啦!这样一个简单的集群就搭好啦~~
Hadoop集群初步搭建:的更多相关文章
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- hadoop集群的搭建与配置(2)
对解压过后的文件进行从命名 把"/usr/hadoop"读权限分配给hadoop用户(非常重要) 配置完之后我们要创建一个tmp文件供以后的使用 然后对我们的hadoop进行配置文 ...
- hadoop集群的搭建
hadoop集群的搭建 1.ubuntu 14.04更换成阿里云源 刚刚开始我选择了nat模式,所有可以连通网络,但是不能ping通,我就是想安装一下mysql,因为安装手动安装mysql太麻烦了,然 ...
- 关于hadoop集群管理系统搭建的规划说明
Hadoop集群管理系统搭建是每个入门级新手都非常头疼的事情,因为你可能花费了很久的时间在搭建运行环境,最终却不知道什么原因无法创建成功.但对新手来说,运行环境搭建不成功的概率还蛮高的. 在之前的分享 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- hadoop集群的搭建(分布式安装)
集群 计算机集群是一种计算机系统,他通过一组松散集成的计算机软件和硬件连接起来高度紧密地协同完成计算工作. 集群系统中的单个计算机通常称为节点,通常通过局域网连接. 集群技术的特点: 1.通过多台计算 ...
- Hadoop集群上搭建Ranger
There are two types of people in the world. I hate both of them. Hadoop集群上搭建Ranger 在搭建Ranger工程之前,需要完 ...
随机推荐
- 【CMake】CMake GUI构建VS等项目
一.CMake官网(https://cmake.org/)上的介绍: CMake is an open-source, cross-platform family of tools designed ...
- 大话IDL之(基本操作流程)
这里将对ENVI-IDL二次开发程序的一个通用流程做一个总结. 1.首先是文件打开和数据读取: 文件打开work_dir = dialog_pickfile(title='选择路径',/directo ...
- 大文件切割(split)
split提供两种方式对文件进行切割: 根据行数切割,通过-l参数指定需要切割的行数 根据大小切割,通过-b参数指定需要切割的大小 1.1 根据行数切割 如下以一个3.4G大小的日志文件做切割演示,每 ...
- SAXParseException Content is not allowed in Prolog (前言中不允许有内容)
解析 XML 文件的时候,如 Mybatis 的 Mapper 文件,有时会出现 org.xml.sax.SAXParseException 前言中不允许有内容 的异常,英文就是 Content is ...
- php-fpm.conf.default配置文件
;;;;;;;;;;;;;;;;;;;;; ; FPM Configuration ; ;;;;;;;;;;;;;;;;;;;;; ; All relative paths in this confi ...
- 【C#】写文件时如何去掉编码前缀
我们都知道,文件有不同的编码,例如我们常用的中文编码有:UTF8.GK2312 等. Windows 操作系统中,新建的文件会在起始部分加入几个字符的前缀,来识别编码. 例如,新建文本文件,写入单词 ...
- Kubernetes CI/CD(2)
本章节通过在Jenkins创建一个kubernetes云环境,动态的在kubernetes集群中创建pod完成pipeline的构建流程,关于直接在宿主机上搭建Jenkins集群的可参照Kuberne ...
- MySql优化之mycat
1. 解压mycat,不要放在有中文目录的地方 下载地址:http://dl.mycat.io/1.6-RELEASE/2 .修改mycat解压目录下的conf文件夹中server.xml文件,配置 ...
- 3Python脚本在linux环境下头文件解释
#!/usr/bin/python到底是什么意思 有这句的,加上执行权限后,可以直接用 ./ 执行,不然会出错,因为找不到 python 解释器. #!/usr/bin/python 是告诉操作系统执 ...
- 使用CSV Data Set Config配置原件,参数化数据
对接口数据的参数化方式大概有三种方式,1:jmeter内置函数:2:借助CSV Data Set Config配置原件:3:jdbc连接数据库,使用数据表字段 此处主要讲第二种:借助CSV Data ...