对result文件进行数据清洗以及进行可视化
项目源码地址:https://github.com/gayu121/result(项目里操作的数据都是清洗过后的数据)
测试要求:
1、 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
(2)第二阶段:根据提取出来的信息做精细化操作
(3)hive数据库表结构:
create table data( ip string, time string , day string, traffic bigint,
type string, id string )
2、数据处理:
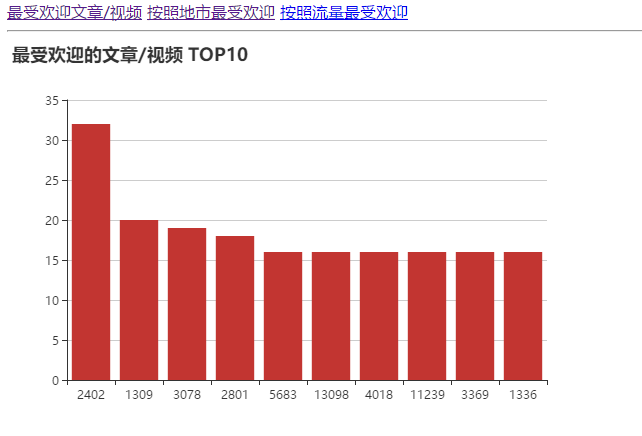
·统计最受欢迎的视频/文章的Top10访问次数 (video/article)
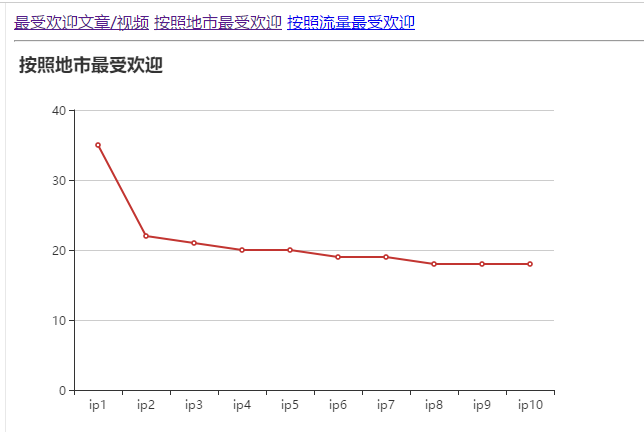
·按照地市统计最受欢迎的Top10课程 (ip)
·按照流量统计最受欢迎的Top10课程 (traffic)
3、数据可视化:将统计结果倒入MySql数据库中,通过图形化展示的方式展现出来。
由于所给的文件是一个TXT文档,数据项之间用逗号隔开,格式如图:
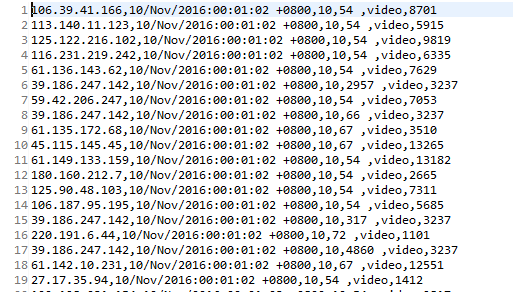
所以需要对数据首先进行清洗,变为用Tab建作为分隔的数据项,在此我弄了很久找不到合适的方法,在同学的指点下使用排序的算法,以id为数据项进行了排序,将数据清洗为要求格式,第二阶段的细化过程也就同理了,在这里附上细化使用的代码
package test3; import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Order2 {
public static class Map extends Mapper<Object , Text , IntWritable,Text >{
private static Text goods=new Text();
private static IntWritable num=new IntWritable();
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
String line=value.toString();
String arr[]=line.split("[\t/:]" ); //主要就是根据这几个特殊字符进行分割,然后按照下面的格式输出到指定文件
num.set(Integer.parseInt(arr[]));
goods.set(arr[] + "\t" + arr[] +"-11-10" +" " + arr[] +":" + arr[]+":" +arr[] +"\t"+ arr[] + "\t" + arr[] + "\t"+arr[] );
context.write(num,goods);
}
}
public static class Reduce extends Reducer< IntWritable, Text, IntWritable, Text>{
private static IntWritable result= new IntWritable();
public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
for(Text val:values){
context.write(key,val);
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf=new Configuration();
Job job =new Job(conf,"OneSort");
job.setJarByClass(Order.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path in=new Path("hdfs://192.168.43.102:9000/test/res1/part-r-00000");
Path out=new Path("hdfs://192.168.43.102:9000/test/res2");
FileInputFormat.addInputPath(job,in);
FileOutputFormat.setOutputPath(job,out);
System.exit(job.waitForCompletion(true) ? : ); }
}
然后第二问就是利用一个MapReduce的统计的方法,针对不同的条件进行计数,然后利用排序算法进行排序,这一块儿的代码在项目里都有,感性趣的话可以到github里下载。
然后在可视化是遇到了一些问题,就是对于那个城市的IP(估计是由于字符太长,无法在echarts中显示)可以打印输出就是不能生成表格,所以那些数据项我就用IP1.....代替了。还有一个问题就是在根据字符串循环时老是说我数组越界,然后我就自己写了一个循环,只有10个数据元,就解决了。
以下是可视化的截图(我用了echarts中的三种显示形式):
柱状图:
折线图:
饼状图:

对result文件进行数据清洗以及进行可视化的更多相关文章
- 吴裕雄--天生自然python数据清洗与数据可视化:MYSQL、MongoDB数据库连接与查询、爬取天猫连衣裙数据保存到MongoDB
本博文使用的数据库是MySQL和MongoDB数据库.安装MySQL可以参照我的这篇博文:https://www.cnblogs.com/tszr/p/12112777.html 其中操作Mysql使 ...
- 310实验室OTL问题----将写好的C++文件转换成Python文件,并将数据可视化
如图:文件夹 第一处:optimizer文件夹下的:optimizer.h文件中添加你所写代码的头文件 #include <OTL/Optimizer/Reference-NSGA-II/Re ...
- 在VMD上可视化hdf5格式的分子轨迹文件
技术背景 在处理分子动力学模拟的数据时,不可避免的会遇到众多的大轨迹文件.因此以什么样的格式来存储这些庞大的轨迹数据,也是一个在分子动力学模拟软件设计初期就应该妥善考虑的问题.现有的比较常见的方式,大 ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- Hive的存储和MapReduce处理——数据清洗
日期:2019.11.13 博客期:115 星期三 Result文件数据说明: Ip:106.39.41.166,(城市) Date:10/Nov/2016:00:01:02 +0800,(日期) D ...
- 关系网络数据可视化:3. 案例:公司职员关系图表 & 导演演员关系网络可视化
1. 公司职员关系图表 节点和边界数据 节点是指每个节点本身的数据,代表公司职工的名称:属性(Country).分类(Category)和地区(Region,给每个节点定义的属性数据).文件必须是.c ...
- 使用mapreduce清洗简单日志文件并导入hive数据库
Result文件数据说明: Ip:106.39.41.166,(城市) Date:10/Nov/2016:00:01:02 +0800,(日期) Day:10,(天数) Traffic: 54 ,(流 ...
- c++可视化性能测试
阅读前注意 本文所有代码贴出来的目的是帮助大家理解,并非是要引导大家跟写,许多环境问题文件问题没有详细说明,代码也并不全面,达不到跟做的效果.建议直接阅读全文即可,我在最后会给出详细代码地址,对源代码 ...
- 将.dat文件导入数据库
*最近在搞文本分类,就是把一批文章分成[军事].[娱乐].[政治]等等. 但是这个先需要一些样本进行训练,感觉文本分类和"按图索骥"差不多,训练的文章样本就是"图&quo ...
随机推荐
- Analysis of Two-Channel Generalized Sidelobe Canceller (GSC) With Post-Filtering
作者:凌逆战 地址:https://www.cnblogs.com/LXP-Never/p/12071748.html 题目:带后置滤波的双通道广义旁瓣相消器(GSC)的分析 作者:Israel Co ...
- Python学习3月5号【python编程 从入门到实践】---》笔记(3)4
1.字典 #####修改字典里面的KEYS数值和VALUES数值要用中括号# alien_0={'color':'green','point':5}# alien_0['color']='red'# ...
- django 数据库连接出现的问题
mysqlclient 1.3.3 or newer is required; you have 0.7.11: 解决方法: 将报错文件中的如下代码注释: if version < (1, 3, ...
- Java和JavaScript之间的区别
1.简介 通过优锐课核心java学习笔记中,我们可以看到,Java和JavaScript之间的区别.我们将在本文中比较Java语言和JavaScript语言.JavaScript由Netscape开发 ...
- 基于GMC/umat的复合材料宏细观渐近损伤分析(一)
近期在开展基于GMC/umat的复合材料宏细观渐近损伤分析,一些技术细节分享如下: 1.理论基础 针对连续纤维增强复合材料,可以通过离散化获得如下的模型: (a)(b)(c) 图1 连续纤维增强复合材 ...
- [Err] 1055 - Expression #1 of ORDER BY clause is not in GROUP BY clause报错问题的解决
run SQL: select version(),@@sql_mode;SET sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY','' ...
- Scala实践8
1.1继承类 使用extends关键字,在定义中给出子类需要而超类没有的字段和方法,或者重写超类的方法. class Person { var name = "zhangsan" ...
- springboot2 整合mongodb
在springboot2中使用MongoDB 1.引入依赖 <dependency> <groupId>org.springframework.boot</groupId ...
- day6 相对定位:position:relative
相对定位:position:relative 特点:a.相对于自己原来位置的定位,以自己的左上角为基准. b.相对定位原来的位置仍然算位置,不会出现浮动现象. 以下为初始位置:(可以看出设置margi ...
- 如何配置好Selenium2Library的环境
1.首先是下载如下文件 1,ActivePython-其自带了pip工具,很方便,记得选择activepython是2.7x版本的python: 2.依次安装wxpython,Robotframewo ...