春蔚专访--MaxCompute 与 Calcite 的技术和故事
摘要:2019大数据技术公开课第一季《技术人生专访》,来自阿里云计算平台事业部高级开发工程师雷春蔚向大家讲述了MaxCompute 与 Calcite 的技术和故事。 具体内容包括: 1) 什么是查询优化器;2)MaxCompute查询优化器的具体实践;3)MaxCompute后续计划;4)从校招到阿里巴巴工程师到Calcite committer,他经历了怎样的个人成长。
以下内容根据演讲视频以及PPT整理而成。
一、查询优化器简介
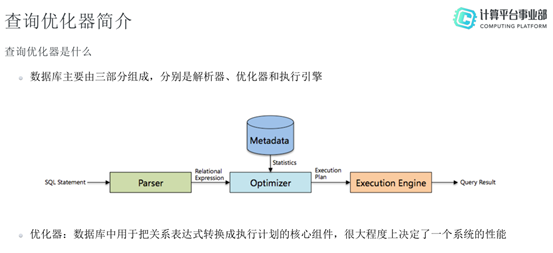
大家都知道,数据库一般由三部分组成,分别是解析器、优化器和执行引擎。一个SQL进入数据库后首先需要通过解析器进行解析,生成相应的关系表达式,然后再经过优化器优化生成物理执行计划,最后由执行引擎执行。优化器是数据库的重要组成部分,它是数据库中用于把关系表达式转换成执行计划的核心组件,在很大程度上决定了一个系统的性能。假如把数据库比作人类的“身体”,优化器就是人类的“大脑”,这个大脑决定了人体系统能走多远、走多快。
查询优化器主要分为两种:
- 基于规则的优化器(Rule Based Optimizer,简称RBO):根据优化规则将一个关系表达式转换成另外一个关系表达式,同时原有表达式被放弃,经过一系列转换生成最终执行计划。事实上,RBO是一种比较落后的优化器,它只认规则,对数据不敏感;容易陷入局部优但是全局差的场景;同时受规则顺序影响而产生不同执行计划
- 基于代价的优化器(Cost Based Optimizer,简称CBO):根据优化规则对关系表达式进行转换,同时原有表达式也会保留,经过一系列转换后会生成多个执行计划,之后计算每个执行计划的Cost,从中挑选Cost最小的执行计划作为最终执行计划。CBO的优点是灵活智能,它能根据数据的特点生成相应的执行计划。因此,目前各大数据库和计算引擎都倾向于使用CBO,例如从Oracle 10g开始,Oracle已经彻底放弃RBO,转而使用CBO,而Hive在0.14版本中也引入了CBO。MaxCompute 也经历了从RBO到CBO的过程,这也是MaxCompute 1.0到2.0过程中一个重大的改变。
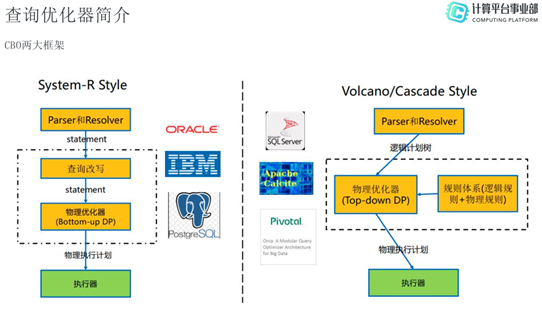
CBO主要有两种不同风格的框架,一种是System-R风格,另一种是Volcano/Cascade风格。
- System-R:sql statement经过Parser和Resolver后,首先进行查询改写,再通过优化器通过动态规划算法生成最后的物理执行计划,最后交由执行器执行。这种风格的CBO最早由IBM的数据库使用,之后被Oracle和PostgreSQL使用。
- Volcano/Cascade:Volcano/Cascade与System-R 的不同点在于,前者的物理优化器是Top-down,而后者是Bottom-up。Volcano/Cascade基于一定的规则体系(逻辑规则+物理规则)来生成比较好的物理执行计划。这种风格目前被SQL Server、Apache Calcite和Pivotal所使用。
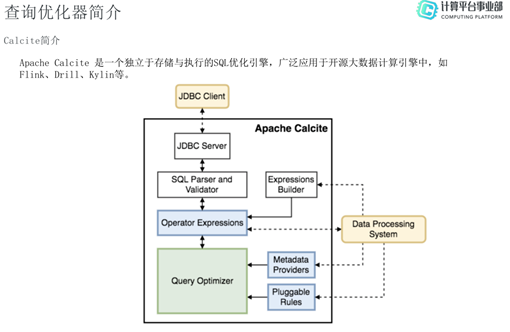
Apache Calcite 是一个独立于存储与执行的SQL优化引擎,目前广泛应用于开源大数据计算引擎中,如 Flink、Drill、Kylin等。Calcite的目标是“一种方案适用于所有需求场景”,旨在为不同的计算平台和数据源提供统一的查询引擎。如上图所示,Calcite的架构不包括存储和执行。整体流程是一个SQL statement通过JDBC Client进入JDBC Server后,经过SQL Parser 和Validator后生成关系代数表达式(Operator Expressions)。除此之外,用户还可以使用Expressions Builder生成SQL的关系代数表达式,这适用于有自己特定语法的系统。生成的关系代数表达式会进入查询优化器核心引擎(Query Optimizer),负责执行动态规划算法和Cost计算。Calcite还提供一些可插拔的功能,如Metadata Providers(为优化引擎提供Metadata)和Pluggable Rules(支持用户自定义优化规则)。

Calcite 主要提供了两种优化器的实现:
- HepPlanner:它指的是前面提到的RBO的实现,它是一个启发式的优化器,按照规则进行匹配,直到达到次数限制(预先设置的match次数限制)或者遍历一遍后不再出现 rule match的情况才算完成;
- VolcanoPlanner:它指的是前面提到的 CBO 的实现,它会一直迭代 rules,直到找到 cost 最小的计划。
二、MaxCompute查询优化器实践
MaxCompute SQL优化器的总体框架如下图所示,主要包括五部分: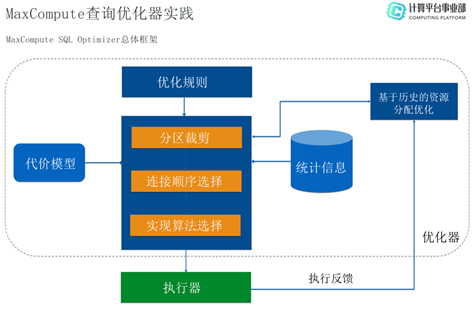
- 代价模型(Cost Model):用于计算Cost来选择最优的执行计划。一个好的代价模型可能会影响整个系统的性能。代价模型是一个五元组,包括CPU、IO、Row Count、Memory、Network。每个operator只关注于自身的Cost,整个执行计划的Cost由引擎累积得到。代价模型力求能够反映客观的物理实现,如具体的IO、Network值,但不需要得到和真实一模一样的数据,只需要能够保证选出较优的执行计划即可。
- 优化规则:不同的系统有不同的优化规则,如分区裁剪规则等。
- 统计信息:该部分对于优化器来讲非常重要,缺乏或不好的统计信息可能会导致生成的执行计划效果比较差。
- 查询优化引擎:使用的是Calcite,实现了分区裁剪、连接顺序的旋转以及实现算法(如动态规划算法)的选择。
- 基于历史的资源分配优化: 执行器执行完任务后,会将执行结果反馈给该模块,由该模块进行资源分配优化。
MaxCompute SQL优化器基于上述优化引擎实现了Shuffle Removal的功能。Shuffle指的是数据从上游任务(Task)到下游任务(Task)被处理的过程,包括分片、排序等。如果上游任务的数据已经包含了相应的物理属性,则没必要进行shuffle处理。

举个例子,假如需要统计在2018年后创建的部门其中30岁以上员工的平均年龄,使用MaxcCompute可以得到如上图所示的物理执行计划。首先从员工表emp中过滤出30岁以上的员工,然后从部门表dept中过滤出2018年之后创建的部门,再进行join操作。考虑到数据量可能会比较大,选用Merge join进行操作。由于需要保证数据分发到同一台机器上,因此从上游Filter到Merge join需要Shuffle的处理过程(图中的EX)。此外,join之后的数据需要进行aggregate聚合操作(图中的Agg)来计算平均年龄,也需要进行Shuffle。事实上,因为之前使用的是Merge join,该过程已经做了数据的分布和排序工作,所以从join到aggregate的过程中Shuffle就不再需要重复去做。面对这类重复的Shuffle过程,可以通过Shuffle Removal功能去掉。
Shuffle Removal功能的实现依靠的是Enforcer Rule, 具体流程如下图所示。操作符如join,aggregate等要求Input数据必须具备物理数据属性Trait(通过排序、分片等操作获得),Enforcer Rule可以保证Input数据所需要的物理属性(Required Trait):1) 若Input数据不具备Required Trait,则需要增加Shuffle过程;2)若Input数据本身已经满足Required Trait,则无需添加;3)Input可以进行特性传递,即将Required Trait下推到自己的Input中。Shuffle Removal功能上线后已经为阿里云带来了大约10%的资源节省。

三、Maxcompute SQL新功能介绍
MaxCompute在阿里巴巴承接了99%的计算和存储,同时也关注提高外部用户的用户体验和计算效率。接下来要介绍的是MaxCompute 2.0的新功能,主要包括编译器、开发利器Studio、帮助提升开发效率的过程化支持功能(如脚本模式、参数化视图)以及自定义功能(如UDT、外表)。在这里需要提到的是,由于公共云尚未正式发布,如需使用,可搜索钉钉群号11782920,联系群主晋恒进行使用。
编译器
MaxCompute 2.0中编译器目前有三个主要的新功能:1)所有的编译错误包含行列号信息,从而帮助用户清晰地了解错误的位置;2)同义词编译中的多个错误会通过错误报告的形式一次性报出来,方便用户进行修改;3)支持warning,提示用户潜在的问题,如Double = STRING精度受损,该功能需要通过set odps.compiler.warning.disable=false预先打开。以上三个功能在开发中非常实用,将极大提高用户的开发效率。

Studio
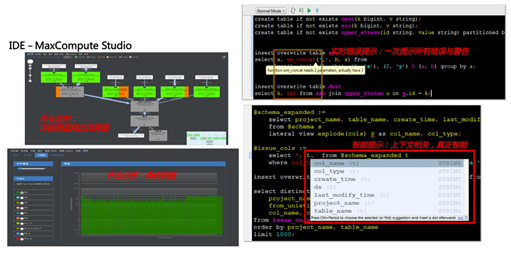
第二个需要强烈推荐的是Maxcompute 2.0的Studio。作为一款IDE,用户可以通过它来编写脚本,其好处主要包括以下几点(如下图所示):
1)作业监控:提供详细而直观的作业流程图,用户可以方便地查看任务流程以及整体的执行计划(左上角子图);
2)作业分析:提供与作业分析相关的数据信息(左下角子图),如每一个任务中Operator的执行时间,通过这些信息,用户可以很直观地看到那部分计划执行得不好,哪部分的资源占用比较高、执行时间比较长,从而进行定向调优,有的放矢地提升执行计划的效率;
3)实时提示SQL中的错误,并且可以一次性提示所有错误和警告,提示用户写的SQL哪里有问题(右上角子图);
4)智能提示:根据用户输入的部分字母以及上下文判断并提示用户可能要输入的命令,帮助用户方便地自动补齐代码(右下角子图)。
脚本模式
问题场景:当面临处理逻辑很复杂的项目时,需要提取多个表后对这些表进行join操作,然后再对结果进行join操作。此外还需要从不同的运行阶段输出多个表,即使使用CTE(Common Table Exclusion)也无法表达,这种情况下只能将这些步骤拆分为多个作业顺序提交。这种解决方案的复杂度和维护成本都比较高,同时给性能带来很大影响。
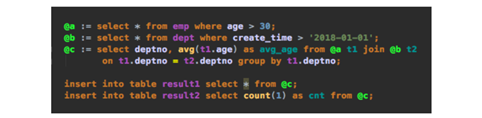
脚本模式解决方案:针对这种需求,MaxCompute 2.0提供了脚本模式的功能。还是以前面提到的例子(统计在2018年后创建的部门中30岁以上员工的平均年龄)来介绍脚本模式的使用,通过MaxCompute的脚本模式,所有命令可以写在一个SQL文件中,用户首先可以定义一个变量a,从员工表emp中筛选年龄大于30岁的员工列表;然后定义一个变量b,从部门表dept中筛选创建时间在2018-01-01之后的部门列表;其次定义一个变量c,统计这些部门中30岁以上员工的平均年龄。所得到的结果可以通过脚本模式很方便地进行后续处理,比如直接通过多个脚本命令将所需的结果插入到不同的表中(具体命令如下图所示)。在面对非常复杂的查询时,使用这种方式使得查询操作和后续的操作更加易于维护、更加清晰。
脚本模式主要有以下三方面的优点:
- 复杂性低:以脚本为单位提交查询,适合提交复杂的查询;
- 易用性高:符合开发者的思考过程,适合编写复杂逻辑;
- 性能高:充分发挥优化器能力(基于代价,脚本复杂越有优势)。
参数化视图
问题场景:假设用户做了一个视图给其他团队用,功能是读取一个数据表,运行新写的模式识别算法提供广告推荐建议。其他团队发现该用户的算法很好也想用,但是底层访问的数据表不一样,一些模式识别的参数也不一样,只好给他们再做一个新的视图。后来发现原来的视图有bug,只有一个个的修改,给维护带来了很大的复杂性。
参数化视图解决方案:针对这种情况,MaxCompute 2.0提供了参数化视图的方式来解决。其语法类似于创建普通的视图view,不同点是参数化视图的创建需要用到两个参数,一个是表参数@a(本身包含两个参数k,v)和String参数@b。参数化视图的创建命令如下图所示,其中创建过程结合了脚本模式。可以发现,通过这种方式创建的视图可以很方便地给任何用户来使用,因为其模式相同,只有参数类型不同而已。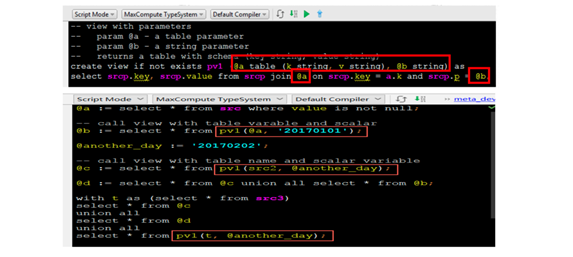
自定义功能(UDT)
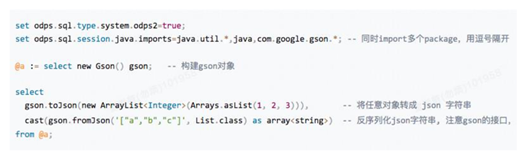
问题场景:Hive和MaxCompute中都可以写UDF来满足某些没有内建函数的需求。比如需要实现一个JSON字符串解析的功能,这个功能用其他语言实现非常简单,比如用Java可能只需要一次调用JSON函数就好了,但是MaxCompute的内置函数没有实现这一功能,为此写一个UDF复杂性太高。
UDT解决方案:针对上述问题场景,MaxCompute2.0提供了UDT(User Defined Type)功能,允许用户在SQL中直接引用第三方语言的类或者对象,获取其数据内容或者调用其方法 。对于上述问题,只需要如下SQL就能解决。这种方式避免了频繁创建UDF,可以像使用Java调用一样方便。
外表
问题场景:MaxCompute用户的数据存储在其他存储系统上,如HDFS,并且格式是CSV格式,有办法使用SQL来操作吗?
外表解决方案:MaxCompute中的外表功能支持用户使用SQL来访问其他数据源和其他数据格式的数据。下图举了一个例子,处理存储在 OSS上的CSV文件。首先需要定义一个外表,定义命令中需要指定csv读取的schema,MaxCompute内置csv文件的handler以及要处理的css的位置;外表定义好之后就可以直接对数据进行读取,抽取的数据可以直接参与SQL运算(和普通的SQL无异),无缝连接。

外表功能支持多种数据源和数据格式,同时支持用户自定义的数据格式(如下图所示)。

四、MaxCompute后续计划
在介绍MaxCompute后续计划之前,首先总结一下其相对于Hive的优势:
- TPCH上有1倍以上的性能提升
- SQL标准支持更好:Hive在跑TPC-DS这个benchmark的时候,有很多SQL是不支持的,而MaxCompute可以做到100%支持;
- 更好的编译器:支持一次性报告错误,高效的错误恢复,支持warning;
- Runtime硬基础好:基于CPP实现的runtime,可以达到更高效率
- 更好的IDE支持:MaxCompute Studio
- 对小作业支持更好:通过Service Mode支持,对于小作业可以做到秒级甚至毫秒级的查询;
- 支持更多好用的语法:包括VALUES表达式、SCALAR SUBQUERIES、INTERSECT / MINUS、PYTHON UDF、UDT / UDJ、脚本模式和参数化视图。
在后续版本中,MaxCompute将主要增加两部分的新功能:
- 内存计算:支持数据缓存在内存中,一次加载数据多次使用,极大减少运行时间;
- 更强大的脚本语言功能:比如支持在SQL中使用条件语句IF/ELSE,以及循环语句 LOOP。

五、个人成长经历及经验
从校招15年进入到阿里巴巴MaxCompute团队,见证了MaxCompute从1.0到2.0的发展,个人经验上来讲,从学校来到阿里巴巴相当于从一个校园来到另一个“校园”。团队本身基于开源社区项目Apache Calcite项目,同时也是其深度用户。使用过程中,团队将一些好的想法贡献给社区,社区也积极接纳,因而成为committer是水到渠成的事情。
最早接触开源社区是在两年前,说到个人经验,总结起来主要有两点:
1)成长是循序渐进的,一开始可能承担的是很小的需求实现,通过积极地和社区交流学习,循序渐进,承担的需求会越来越大,贡献也会逐渐增多;
2)从开源社区可以学到很多东西,开源社区比较注重代码质量和社区成员之间的沟通交流,通过及时的沟通交流会提前避免很多不必要的冲突和返工。
本文作者:晋恒
本文为云栖社区原创内容,未经允许不得转载。
春蔚专访--MaxCompute 与 Calcite 的技术和故事的更多相关文章
- 海胜专访--MaxCompute 与大数据查询引擎的技术和故事
摘要:在2019大数据技术公开课第一季<技术人生专访>中,阿里巴巴云计算平台高级技术专家苑海胜为大家分享了<MaxCompute 与大数据查询引擎的技术和故事>,主要介绍了Ma ...
- 阿里云MaxCompute 2019-7月刊
您好,MaxCompute 2019.7月刊为您带来7月产品.技术最新动态,欢迎阅读. 导读 [发布]7月产品重要发布 [资讯]7月重要资讯 [文档]7月重要文档更新推荐 [干货]7月精选技术文章推荐 ...
- 从 Apache ORC 到 Apache Calcite | 2019大数据技术公开课第一季《技术人生专访》
摘要: 什么是Apache ORC开源项目?主流的开源列存格式ORC和Parquet有何区别?MaxCompute为什么选择ORC? 如何一步步成为committer和加入PMC的?在阿里和Uber总 ...
- 阿里云大数据计算服务 - MaxCompute (原名 ODPS)
MaxCompute 是阿里EB级计算平台,经过十年磨砺,它成为阿里巴巴集团数据中台的计算核心和阿里云大数据的基础服务.去年MaxCompute 做了哪些工作,这些工作背后的原因是什么?大数据市场进入 ...
- Java Web编程技术学习要点及方向
学习编程技术要点及方向亮点: 传统学习编程技术落后,应跟著潮流,要对业务聚焦处理.要Jar, 不要War:以小为主,以简为宝,集堆而成.去繁取简 Spring Boot,明日之春(future of ...
- 推荐几个顶级的IT技术公众号,坐稳了!
提升自我的路很多,学习是其中最为捷径的一条.丰富的知识提升的不仅仅是你的阅历,更能彰显你的气质,正如古人云:"文质彬彬是君子." 今天为大家整理了10个公众号,分别为多领域,多角度 ...
- 阿里靠什么支撑 EB 级计算力?
作者 关涛 阿里云智能事业群 研究员 导读:MaxCompute 是阿里EB级计算平台,经过十年磨砺,它成为阿里巴巴集团数据中台的计算核心和阿里云大数据的基础服务.去年MaxCompute 做了哪些工 ...
- Android和Linux应用综合对比分析
原文地址:http://www.cnblogs.com/beer/p/3325242.html 免责声明: 当时写完这篇调查报告,给同事看了后,他觉得蛮喜欢,然后想把这篇文章修改一下,然后往期刊上发表 ...
- PBRT笔记(6)——采样和重构
前言 本文仅作为个人笔记分享,又因为本章涉及多个专业领域而本人皆未接触过,所以难免出错,请各位读者注意. 对于数字图像需要区分image pixels(特定采样处的函数值)和display pixel ...
随机推荐
- [转]C#设计模式(8)-Builder Pattern
一. 建造者(Builder)模式 建造者模式可以将一个产品的内部表象与产品的生成过程分割开来,从而可以使一个建造过程生成具有不同的内部表象的产品对象. 对象性质的建造 有些情况下,一个对象会有一些重 ...
- Django项目:CRM(客户关系管理系统)--63--53PerfectCRM实现CRM客户报名流程缴费
#urls.py """PerfectCRM URL Configuration The `urlpatterns` list routes URLs to views. ...
- 如何设置td中溢出内容的隐藏显示
<style type="text/css"> table { table-layout:fixed; } td { overflow:hidden; word-bre ...
- 19-10-25-G-悲伤
此题未通过 [ 老帅哥 ] 认证. ZJ一下: T1,明显是二分答案+$dij/SPFA$ T2,没看懂题. T3,打了一个$\Theta(N^2)$暴力. 事实上…… T1,T2死了. T1中 每次 ...
- 19.10.14-Q
小$P$的咕事 总结: 还行,就是$T1$写的慢了,$T2,T3$暴力有点锅 T1 小模拟. 打就是了. 可以小小的手玩一下. (考试的时候某同志人肉对拍了$20min$)=.= 418 ms 360 ...
- etcd 研究研究
先记录参考信息:etcd 场景https://blog.csdn.net/bbwangj/article/details/82584988 etcd 集群部署https://www.jianshu.c ...
- PAT甲级——A1052 Linked List Sorting
A linked list consists of a series of structures, which are not necessarily adjacent in memory. We a ...
- boxFilter in opencv
, -),bool normalize=true,int borderType=BORDER_DEFAULT) Smoothes image using box filter Parameters: ...
- HBase的一些关于CRUD方法
配置内容 static{configuration = HBaseConfiguration.create(); //创建配置文件(也就是load工程包目录下的配置文件hbase-site.xml) ...
- MySQL抑制binlog日志中的BINLOG部分的方法
1.mysqlbinlog之base64-output参数 --base64-output=value This option determines when events should be dis ...