node 写的简单爬虫(三)
异步爬取数据
先引入
var async = require('async');
然后同样上代码
var topicUrls = [];//存所有地址
http.get(url,function(res){
var html='';
res.on('data',function(data){
html +=data
})
res.on('end', function() {
var $=cheerio.load(html);
$("#subShowContent1_news2 h2 a").each((iten,i)=>{
var href=$(i).attr('href');
topicUrls.push(href); })
console.log(topicUrls);
// 控制最大并发数为5,异步执行函数
async.mapLimit(topicUrls,5,function(myurl, callback){
//console.log(myurl);
fetchUrl(myurl, callback);
},function (err, result) {
console.log(result);
});
});
}).on('error', function() {
console.log("获取数据出错!")
});
function fetchUrl(myurl,callback) {
var fetchStart = new Date().getTime();
http.get(myurl,function(res){
var html='';
res.on('data',function(data){
html +=data
}) res.on('end', function() {
var $=cheerio.load(html); $("#article").each((iten,i)=>{
console.log($(i).text());
})
console.log("数据加载完毕");
});
}).on('error', function() {
console.log("获取数据出错!")
}); }
结果显示如下
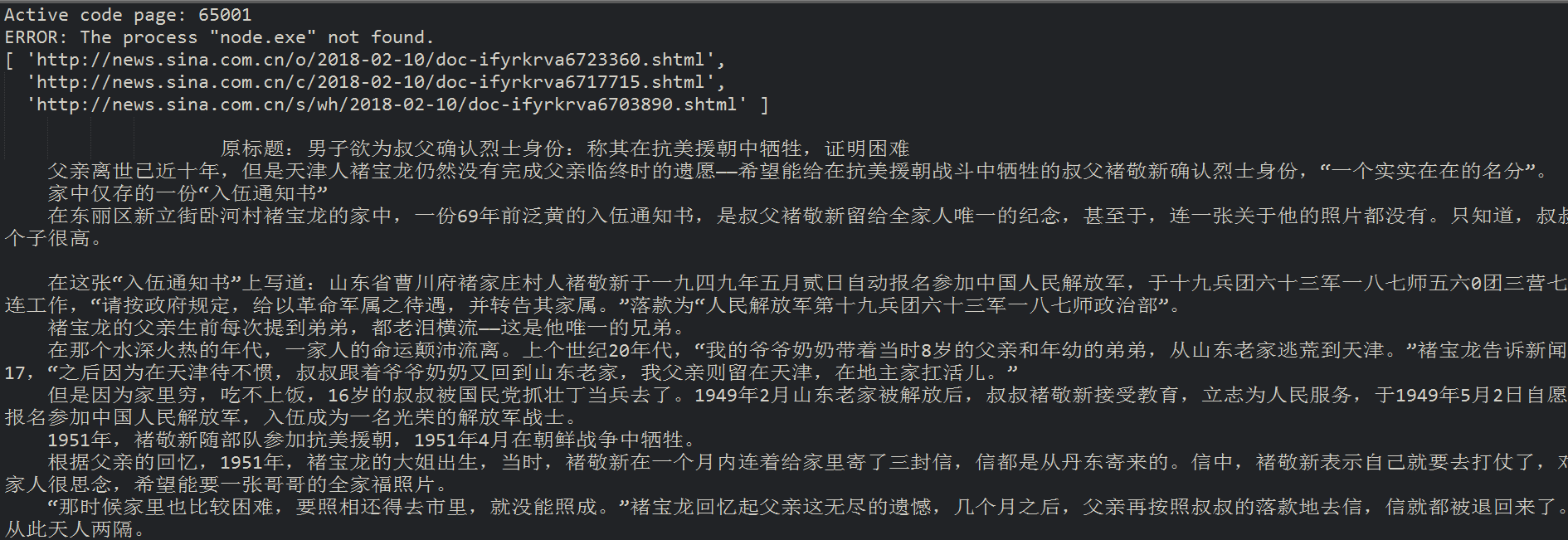
node 写的简单爬虫(三)的更多相关文章
- node 写的简单爬虫(一)
安装cheerio npm install cheerio --save 引入http和cheeri var http=require("http"); var cheerio=r ...
- 用node.js写一个简单爬虫,并将数据导出为 excel 文件
引子 最近折腾node,最开始像无头苍蝇一样到处找资料,然而多数没什么卵用,都在瞎比比.在一阵瞎搞后,我来分享一下初步学习node的三个过程: 1 撸一遍NODE入门,对其有个基本的了解: 2 撸一遍 ...
- C#写一个简单爬虫
最近研究C#的爬虫写法,搞了半天,才在网上很多的写法中整理出了一个简单的demo(本人菜鸟,大神勿喷).一是为了自己记录一下以免日后用到,二是为了供需要朋友参考. 废话不多说,上代码 using Ht ...
- 用node写个简单的静态服务器
直接上代码吧,我把它命名为 app.js, 只要在该文件所在目录下,控制台运行 node app.js 即可启动一个本地服务器了. /** * 服务器 * Author jervy * Date */ ...
- 使用node写一个简单的页面操作
let http = require('http'); let urlStr = require('url'); let fs = require('fs'); let path = require( ...
- 第一次用python 写的简单爬虫 记录在自己的博客
#python.py from bs4 import BeautifulSoup import urllib.request from MySqlite import MySqlite global ...
- 用node.js从零开始去写一个简单的爬虫
如果你不会Python语言,正好又是一个node.js小白,看完这篇文章之后,一定会觉得受益匪浅,感受到自己又新get到了一门技能,如何用node.js从零开始去写一个简单的爬虫,十分钟时间就能搞定, ...
- 手把手教你学node.js之使用 superagent 与 cheerio 完成简单爬虫
使用 superagent 与 cheerio 完成简单爬虫 目标 建立一个 lesson 3 项目,在其中编写代码. 当在浏览器中访问 http://localhost:3000/ 时,输出 CNo ...
- node的简单爬虫
最近在学node,这里简单记录一下. 首先是在linux的环境下,关于node的安装教程: https://github.com/alsotang/node-lessons/tree/master ...
随机推荐
- 深入浅出 Java Concurrency (5): 原子操作 part 4[转]
在JDK 5之前Java语言是靠synchronized关键字保证同步的,这会导致有锁(后面的章节还会谈到锁). 锁机制存在以下问题: (1)在多线程竞争下,加锁.释放锁会导致比较多的上下文切换和调度 ...
- java文件配置MySQL
MybatisConfig.java文件 import com.alibaba.druid.pool.DruidDataSource; import com.xman.common.mybatis.S ...
- Python3实用编程技巧进阶
Python3实用编程技巧进阶 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大家看的时候可以 ...
- 【Streaming】Storm内部通信机制分析
一.任务执行及通信的单元 Storm中关于任务执行及通信的三个概念:Worker(进程).Executor(线程)和Task(Spout.Bolt) 1. 一个worker进程执行的是一个Topol ...
- tensorflow根据pb多bitch size去推导物体
with self.detection_graph.as_default(): with tf.Session(graph=self.detection_graph) as sess: # Expan ...
- (codeforces 853A)Planning 贪心
Helen works in Metropolis airport. She is responsible for creating a departure schedule. There are n ...
- Leetcode506.Relative Ranks相对名次
给出 N 名运动员的成绩,找出他们的相对名次并授予前三名对应的奖牌.前三名运动员将会被分别授予 "金牌","银牌" 和" 铜牌"(" ...
- zabbix告警模板
邮件 webhook模板 ZABBIX告警通知 告警状态:[{TRIGGER.STATUS}] 告警主机:[{HOST.NAME}] 主机地址:[{HOST.IP}] 告警时间:[{EVENT.DAT ...
- 20190921-雅礼Day1
#error 此人太蒻无法编译 #include<iostream> main(){} Before 哦…… -O2 T1 序列问题:分块(莫队),树状数组,线段树,分治 离线 or 在线 ...
- 20190813-Sunburst
Sunburst-7obu&Itro 雨过天晴. 考试过程 刚开始挺郁闷的,上一个T2还在改(50/50/51)XD 先通看三题. T1好像是树?? T2可以把环拆成链. T3好像是BFS?? ...