【笔记】机器学习 - 李宏毅 - 5 - Classification
Classification: Probabilistic Generative Model 分类:概率生成模型
如果说对于分类问题用回归的方法硬解,也就是说,将其连续化。比如 \(Class 1\) 对应的目标输出为 1, \(Class 2\) 对应 -1。
则在测试集上,结果更接近1的归为\(Class 1\),反之归为\(Class 2\)。
这样做存在的问题:如果有Error数据的干扰,会影响分类的结果。
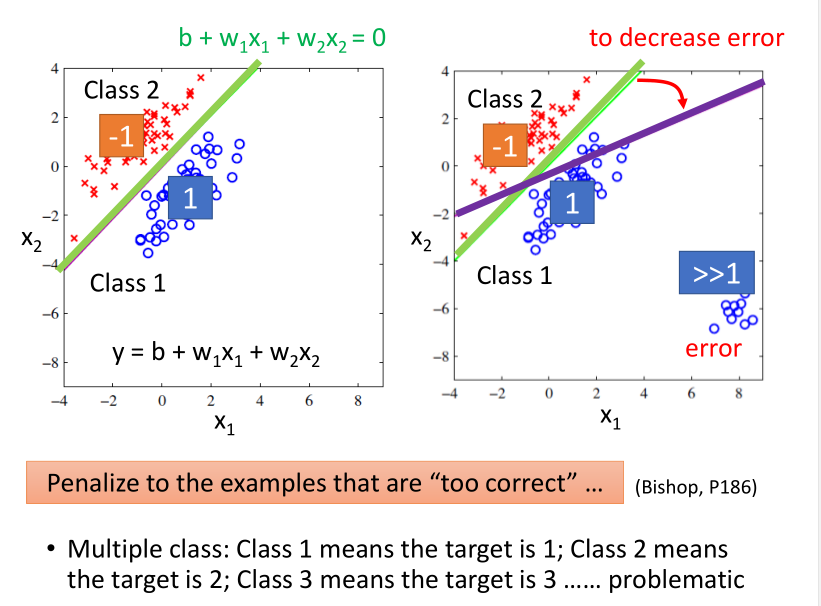
还有就是,如果是多分类问题,则在各类之间增加了线性关系,比如认为 \(Class 3\) 比 $ Class 4$ 离 \(Class 1\) 更近,这是不对的。
另一种方法是,用\(if\)函数,不过这样的话,虽然分类更合理,但损失函数无法微分计算。

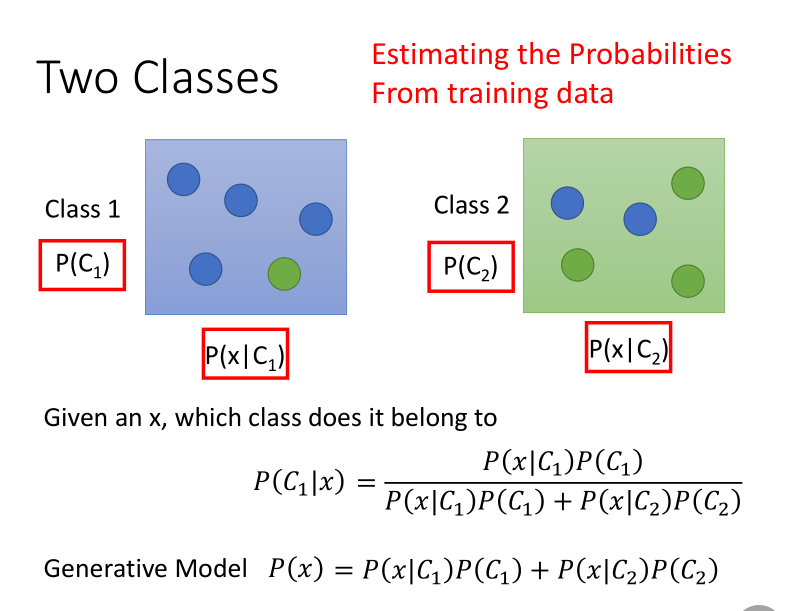
比较好的模型是概率生成模型,通过概率方式计算,(贝叶斯公式)。
其中\(P(C_1)\)和\(P(C_2)\)是先验概率。
高斯分布,最大似然估计
这里选用高斯分布(其他合理的分布也可以,比如对于二元分类来说,可以假设是符合 Bernoulli distribution(伯努利分布))。
从概率上讲,任何高斯分布都可以产生样本数据,但我们需要的是最大可能性的那种分布,求出它的期望 \(\mu\) 和协方差矩阵 \(\sum\)。
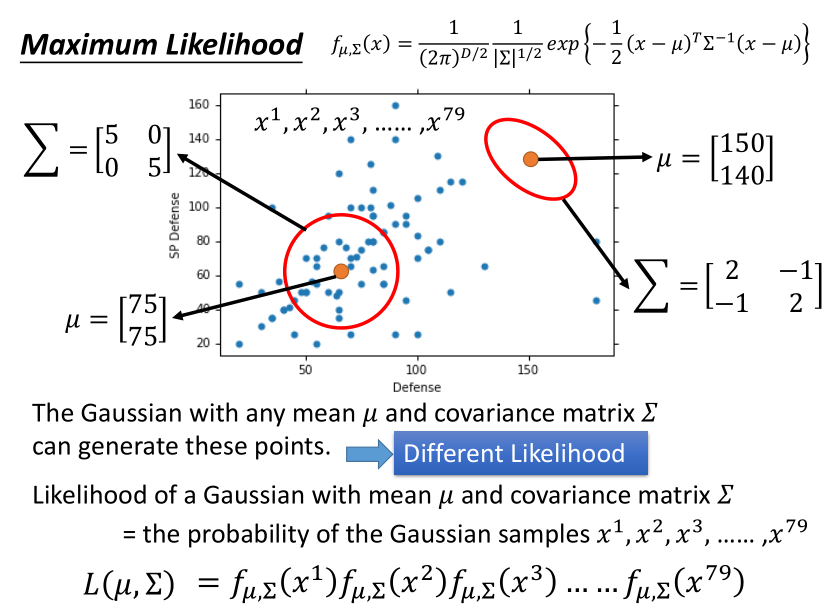
求解方法就是对 \(\mu\)和\(\sum\)分别关于\(L(\mu, \sum)\)求偏微分。

最后得到的结果不是很好,只有47%正确率,即使考虑更多的参数(Overfitting),提升到7维,也只有54%。
如果说,给两个高斯分布相同的协方差矩阵(求加权平均值)的话,效果会好很多,达到了73%。因为分界线是直线,所以也把这种分类叫做线性模型。

分类问题的机器学习三步骤:

此外,假设每一个维度用概率分布模型产生出来的几率是相互独立的,所以可以将 \(P(x|C_1)\)拆解,可以认为每个 \(P(x_k|C_1)\)产生的概率都符合一维的高斯分布。
也就是此时P(x|C1)的高斯分布的协方差是对角型的(不是对角线的地方值都是0),这样就可以减少参数的量。但是结果显示这种做法不好。
这种假设所有的feature都是相互独立产生的分类叫做 Naive Bayes Classifier(朴素贝叶斯分类器)。

后验概率


经过一系列数学推导后,最后在形式上转换为了 \(w · x + b\),然后再套一个\(sigmoid\)函数就得到了最后的结果。
所以,在训练时可以直接去求w和b,这在形式上和回归模型又统一了。
【笔记】机器学习 - 李宏毅 - 5 - Classification的更多相关文章
- 深度学习课程笔记(二)Classification: Probility Generative Model
深度学习课程笔记(二)Classification: Probility Generative Model 2017.10.05 相关材料来自:http://speech.ee.ntu.edu.tw ...
- 机器学习笔记P1(李宏毅2019)
该博客将介绍机器学习课程by李宏毅的前两个章节:概述和回归. 视屏链接1-Introduction 视屏链接2-Regression 该课程将要介绍的内容如下所示: 从最左上角开始看: Regress ...
- 【笔记】机器学习 - 李宏毅 - 10 - Tips for Training DNN
神经网络的表现 在Training Set上表现不好 ----> 可能陷入局部最优 在Testing Set上表现不好 -----> Overfitting 过拟合 虽然在机器学习中,很容 ...
- 【笔记】机器学习 - 李宏毅 - 1 - Introduction & next step
Machine Learning == Looking for a Function AI过程的解释:用户输入信息,计算机经过处理,输出反馈信息(输入输出信息的形式可以是文字.语音.图像等). 因为从 ...
- 【笔记】机器学习 - 李宏毅 - 13 - Why Deep
当参数一样多的时候,神经网络变得更高比变宽更有效果.为什么会这样呢? 其实和软件行业的模块化思想是一致的. 比如,如果直接对这四种分类进行训练,长发的男孩数据较少,那么这一类训练得到的classifi ...
- 【笔记】机器学习 - 李宏毅 - 12 - CNN
Convolutional Neural Network CNN 卷积神经网络 1. 为什么要用CNN? CNN一般都是用来做图像识别的,当然其他的神经网络也可以做,也就是输入一张图的像素数组(pix ...
- 【笔记】机器学习 - 李宏毅 - 11 - Keras Demo2 & Fizz Buzz
1. Keras Demo2 前节的Keras Demo代码: import numpy as np from keras.models import Sequential from keras.la ...
- 【笔记】机器学习 - 李宏毅 - 9 - Keras Demo
3.1 configuration 3.2 寻找最优网络参数 代码示例: # 1.Step 1 model = Sequential() model.add(Dense(input_dim=28*28 ...
- 【笔记】机器学习 - 李宏毅 - 8 - Backpropagation
反向传播 反向传播主要用到是链式法则. 概念: 损失函数Loss Function是定义在单个训练样本上的,也就是一个样本的误差. 代价函数Cost Function是定义在整个训练集上的,也就是所有 ...
随机推荐
- web开发发展历程
cs架构:(软件主要运行在桌面上,数据库软件运行在服务器端) 缺点:如果web应用修改或升级,需要每个客户端逐个升级桌面App,因此Browser/server模式开始流行. bs架构:应用程序的逻辑 ...
- 批处理(BAT) Ping监控, 结果记录入日志文件
::执行效果 @echo off ::等待用户输入需要监控IP set /p ip=Input the IP required to monitor: echo executing...... :st ...
- Go语言实现:【剑指offer】矩阵中的路径
该题目来源于牛客网<剑指offer>专题. 请设计一个函数,用来判断在一个矩阵中是否存在一条包含某字符串所有字符的路径.路径可以从矩阵中的任意一个格子开始,每一步可以在矩阵中向左,向右,向 ...
- centos下升级php到5.6
今天正好用空把php环境升级到5.6版本,首先我之前的环境是源码包编译的lnmp环境 首先到php官方网站上下载一个php5.6的tar包,放到机器上面后,开始安装,安装前先将nginx,mysql, ...
- 使用Java实现三个线程交替打印0-74
使用Java实现三个线程交替打印0-74 题目分析 三个线程交替打印,即3个线程是按顺序执行的.一个线程执行完之后,唤醒下一个线程,然后阻塞,等待被该线程的上一个线程唤醒.执行的顺序是一个环装的队列 ...
- docker-compose 常用命令整理:
docker-compose -f my.yaml version 查看docker-compose版本信息 docker-compose -f lnmp.yaml images 列出镜像 docke ...
- [Redis-CentOS7]Redis发布订阅操作(七)
发布订阅 发布:打电话 订阅:接电话 订阅频道 127.0.0.1:6379> SUBSCRIBE msg Reading messages... (press Ctrl-C to quit) ...
- 动态规划------背包问题(c语言)
/*背包问题: 背包所能容纳重量为10:共五件商品,商品重量用数组m存储m[5]={2,2,6,5,4}, 每件商品的价值用数组n存储,n[5]={6,3,5,4,6};求背包所能装物品的最大价值. ...
- .gitignore配置规则
1.gitignore文件 在git中如果想忽略掉某个文件,不让这个文件提交到版本库中,可以使用修改 .gitignore 文件的方法.这个文件每一行保存了一个匹配的规则例如: # 此为注释 – 将被 ...
- h5笔记1
1.HTML中不支持 空格.回车.制表符,它们都会被解析成一个空白字符 2.适用于大多数 HTML 元素的属性: class 为html元素定义一个或多个类名(classname)(类名从样式文件引入 ...