免费带你体验阿里巴巴旗舰大数据计算产品MaxCompute
什么是MaxCompute?
众所周知,MaxCompute是阿里云推出的承载EB级的数据存储能力,百PB级的单日计算能力,公共云覆盖国内外十几个国家和地区,专有云包含城市大脑在内部署超过100+套的阿里巴巴的统一计算平台。官方地址:https://www.aliyun.com/product/odps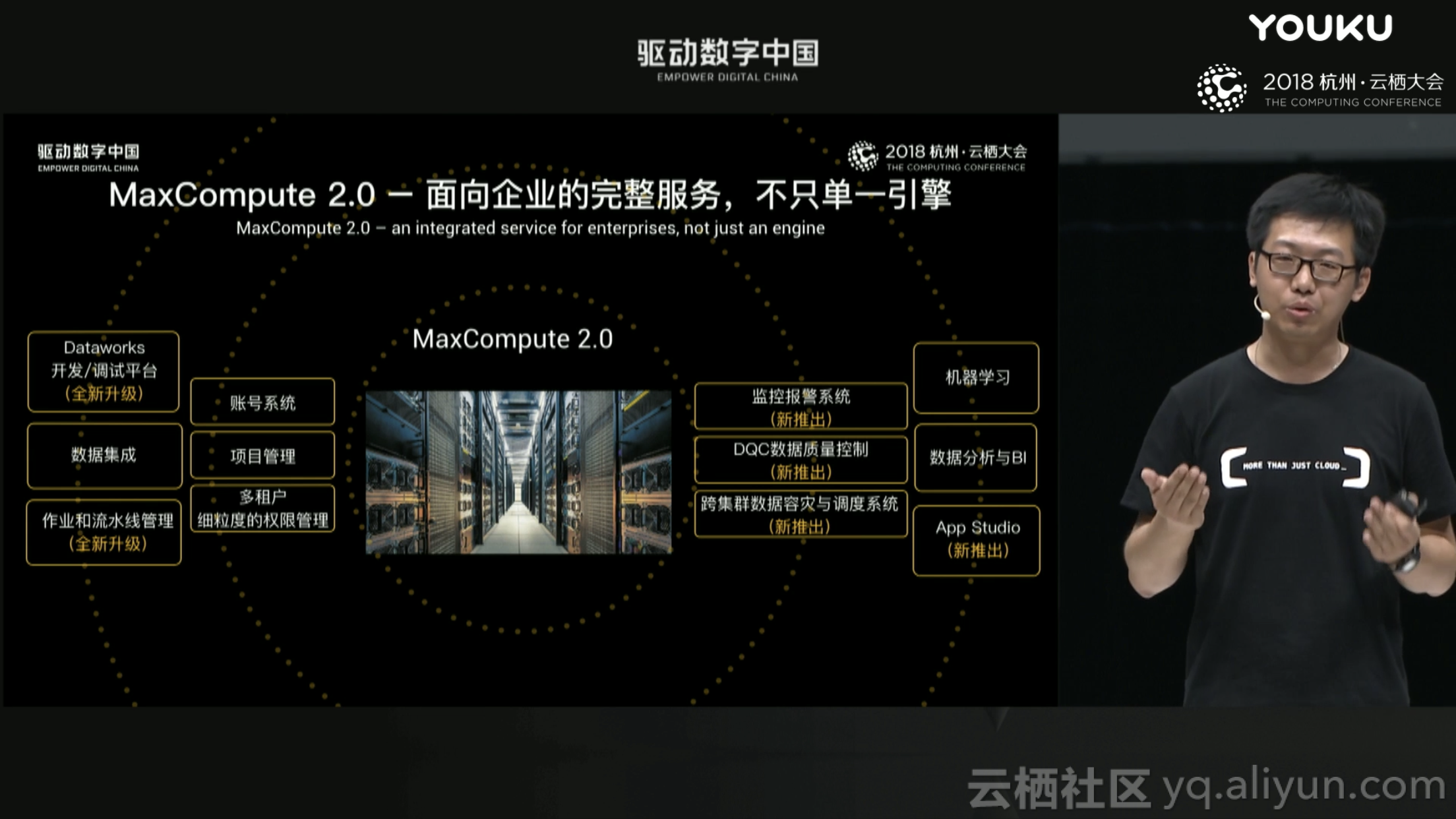

MaxCompute是真正为大数据而生的企业级云计算产品,其核心是一项基础服务(PaaS),用于对海量数据进行高性能的分析处理,数据规模越大,计算性能越卓越,在大规模批量计算下性能远超Hadoop Hive,甚至超越了Spark、Impala;
单纯从技术上来看,MaxCompute提供了一个在云端的SQL、MapReduce、Graph服务,提供对海量数据的批量计算能力;
另外,MaxCompute是基于Serverless架构实现的服务,从成本最优化、运维便利性、业务敏捷度三个方面,帮助企业升维核心竞争力;
很多开发者都想试用一下MaxCompute,但又担心这么一款旗舰产品价格不菲,今天小编带大家做一次免费试用;
准备工作
1、提前一周申请10元代金券,代金券申请地址:https://i.aliyun.com/inviteapply?agent_id=183
2、有开发者会问到,10元代金券能干什么?买台最低配置的虚机测试还得上几百元,更别提大数据产品了。首先带大家了解一下MaxCompute计费规则:MaxCompute每月每1GB数据的存储费用是2分钱,每月每处理1GB数据SQL收费0.3元;配套的离线/实时数据同步工具如Datax、Datahub免费,提供大数据开发调度、数据质量、血缘管理的Dataworks也免费。
3、假如你有3G数据,我们看看是如何花费10元;
3.1、3G存储,5张表,每张表平均600M,MaxCompute整体压缩后约1G数据,每天存储开销2分钱;
3.2、从本地上传到MaxCompute,不收费用;
3.3、设置一个Pipeline,每天跑5个SQL
一类SQL是简单查询-单表查询,每次SQL查询开销0.2元
一类SQL是复杂查询-Join 2张表,每次SQL查询开销1.2元;
我们完成上述任务总共需要3.2元,计算方法就是:2次复杂SQL*1.2元+3次简单SQL*0.2+存储0.02分钱;同样任务我们可以通过Dataworks配置周期调度,跑三天,花销9.4元;
4、所以,我们可以通过领用10元代金券,免费完成很多数据任务。
操作流程
开通MaxCompute后付费服务->通过Dataworks创建Project->通过tunnel上传你的数据集->通过SQL运行你的Hello World。
1、开通MaxCompute后付费服务
https://help.aliyun.com/document_detail/58226.html
2、通过Dataworks创建Project
https://help.aliyun.com/document_detail/27815.html
3、通过tunnel上传你的数据集
3.1、安装并配置客户端
https://help.aliyun.com/document_detail/27804.html
3.2、创建表
https://help.aliyun.com/document_detail/27808.html
3.3、导入数据或使用公开数据集
导入数据 https://help.aliyun.com/document_detail/27809.html
使用数据集 https://yq.aliyun.com/articles/89763 注意:有些数据集上T,先通过desc 表名获取数据大小,切勿全表扫描;
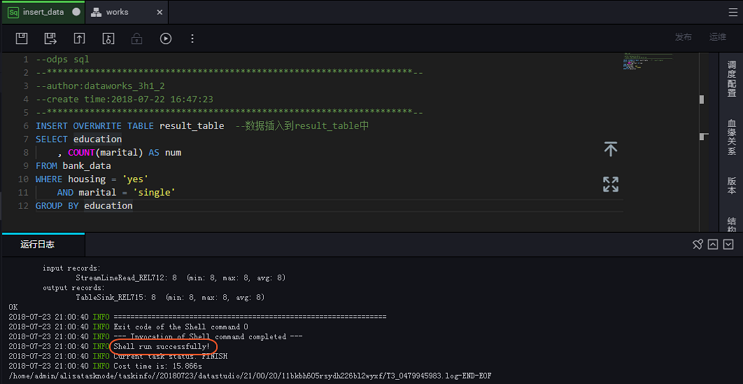
4、通过SQL运行你的Hello World
https://help.aliyun.com/document_detail/27810.html
小结
通过免费试用,开发者可以感受到将所有精力都放在业务上,节省了自建平台在学习成本、开发成本、管理成本、投入机房资源和运维成本的总成本,应用开发效率有很大提高。
免费带你体验阿里巴巴旗舰大数据计算产品MaxCompute的更多相关文章
- 王坚十年前的坚持,才有了今天世界顶级大数据计算平台MaxCompute
如果说十年前,王坚创立阿里云让云计算在国内得到了普及,那么王坚带领团队自主研发的大数据计算平台MaxCompute则推动大数据技术向前跨越了一大步. 数据是企业的核心资产,但十年前阿里巴巴的算力已经无 ...
- 揭秘阿里云EB级大数据计算引擎MaxCompute
日前,全球权威咨询与服务机构Forrester发布了<The Forrester WaveTM: Cloud Data Warehouse, Q4 2018>报告.这是Forrester ...
- 什么是大数据计算服务MaxCompute
大数据计算服务(MaxCompute,原名ODPS)是一种快速.完全托管的EB级数据仓库解决方案. 当今社会数据收集手段不断丰富,行业数据大量积累,数据规模已增长到了传统软件行业无法承载的海量数据(百 ...
- 阿里巴巴飞天大数据架构体系与Hadoop生态系统
很多人问阿里的飞天大数据平台.云梯2.MaxCompute.实时计算到底是什么,和自建Hadoop平台有什么区别. 先说Hadoop 什么是Hadoop? Hadoop是一个开源.高可靠.可扩展的分布 ...
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- 大数据计算的基石——MapReduce
MapReduce Google File System提供了大数据存储的方案,这也为后来HDFS提供了理论依据,但是在大数据存储之上的大数据计算则不得不提到MapReduce. 虽然现在通过框架的不 ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
- 大数据计算:如何仅用1.5KB内存为十亿对象计数
大数据计算:如何仅用1.5KB内存为十亿对象计数 Big Data Counting: How To Count A Billion Distinct Objects Using Only 1.5K ...
随机推荐
- js drag drop 收藏夹拖拽移除的简单例子
代码 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title& ...
- 3306端口被占用导致MySQL无法启动
报错:mysql服务无法启动1067 发现WINDOWS下面没有MYSQL的服务在MYSQL的安装目录bin下面安装MYSQL服务:C:\Program Files\MySQL\MySQL Serve ...
- Pregel Worker
- Linux 父进程发送信号杀死子进程
#include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <signal. ...
- 15_TLB中的G属性
> TLB 是为了增加访问内存的效率 即 如果 是 29 9 12 分页 请求数据 可能需要访问 4次内存:为了解决这个问题:出现了 TLB (虚拟地址到物理地址的转换关系),如果目标地址在TL ...
- 微信公众号开发上传图文素材带有卡片小程序报错:errcode=45166,errmsg = invalid content hint
微信公众号开发自从支持允许在群发图文中插入小程序,方便了小程序的运营及推广.最近在三方服务开发中,要支持图文素材插入小程序遇到了一个很是棘手的问题.官方给出的插入小程序的示例支持文字.图片.卡片.如下 ...
- 笔记53 Mybatis快速入门(四)
动态SQL 1.if 假设需要对Product执行两条sql语句,一个是查询所有,一个是根据名称模糊查询.那么按照现在的方式,必须提供两条sql语句:listProduct和listProductBy ...
- Promise 解决同步请求问题
在写小程序和vue项目中,由于 api 不提供 同步请求,因此,可以通过 Promise 来实现 同步请求操作 在这里 对于 Promise 不太了解的小伙伴 可以查找 Promise 的api 文 ...
- Thymeleaf语法总结
Thymeleaf是Spring boot推荐使用的模板引擎. 一.th属性 html有的属性,Thymeleaf基本都有,而常用的属性大概有七八个.其中th属性执行的优先级从1~8,数字越低优先级越 ...
- springcloud -zuul(1-zuul的简单使用)
1.maven引入包 <dependency> <groupId>org.springframework.cloud</groupId> <artifactI ...