简单的爬虫例子——爬取豆瓣Top250的电影的排名、名字、评分、评论数
爬取思路:
url从网页上把代码搞下来
bytes decode ---> utf-8 网页内容就是我的待匹配的字符串
ret = re.findall(正则,待匹配的字符串), ret 是所有匹配到的内容组成的列表
import re
import json
from urllib.request import urlopen # (1)re.compile——爬取到文件中 def getPage(url):
response = urlopen(url)
return response.read().decode('utf-8') def parsePage(s):
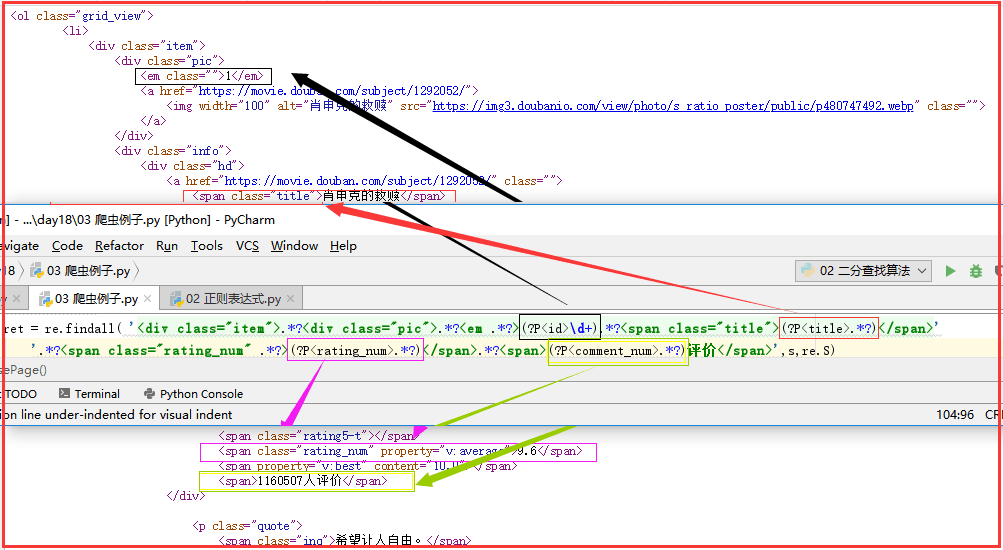
com = re.compile(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S
)
ret = com.finditer(s)
for i in ret:
yield {
"id":i.group("id"),
"title":i.group("title"),
"rating_num":i.group("rating_num"),
"comment_num":i.group("comment_num"),
} def main(num):
url = 'https://movie.douban.com/top250?start=%s&filter=' % num
response_html = getPage(url)
ret = parsePage(response_html)
print(ret)
f = open("movie_info","a",encoding="utf-8") for obj in ret:
print(obj)
data = str(obj)
f.write(data + "\n")
f.close() count = 0
for i in range(10): # 10页
main(count)
count += 25
import re
import json
from urllib.request import urlopen
# (2)re.findall——打印输出 import re
import json
from urllib.request import urlopen def getPage(url):
response = urlopen(url)
return response.read().decode('utf-8') def parsePage(s):
ret = re.findall( '<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',s,re.S)
return ret def main(num):
url = 'https://movie.douban.com/top250?start=%s&filter=' % num
response_html = getPage(url)
ret = parsePage(response_html)
print(ret) count = 0
for i in range(10): #10页
main(count)
count += 25
正则表达式详解:
简单的爬虫例子——爬取豆瓣Top250的电影的排名、名字、评分、评论数的更多相关文章
- 爬虫之爬取豆瓣top250电影排行榜及爬取斗图啦表情包解读及爬虫知识点补充
今日内容概要 如何将爬取的数据直接导入Excel表格 #如何通过Python代码操作Excel表格 #前戏 import requests import time from openpyxl impo ...
- python爬取豆瓣top250的电影数据并存入excle
爬取网址: https://movie.douban.com/top250 一:爬取思路(新手可以看一下) : 1:定义两个函数,一个get_page函数爬取数据,一个save函数保存数据,mian中 ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- 第一个nodejs爬虫:爬取豆瓣电影图片
第一个nodejs爬虫:爬取豆瓣电影图片存入本地: 首先在命令行下 npm install request cheerio express -save; 代码: var http = require( ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python-爬虫实战 简单爬取豆瓣top250电影保存到本地
爬虫原理 发送数据 获取数据 解析数据 保存数据 requests请求库 res = requests.get(url="目标网站地址") 获取二进制流方法:res.content ...
随机推荐
- Mac安装fish shell
1.brew update 2.brew install fish 3.sudo vi /etc/shells 增加内容:/usr/local/bin/fish ##增加fish到shell环境变 ...
- JavaScript学习总结(九)——Javascript面向(基于)对象编程
一.澄清概念 1.JS中"基于对象=面向对象" 2.JS中没有类(Class),但是它取了一个新的名字叫“原型对象”,因此"类=原型对象" 二.类(原型对象)和 ...
- win10 移动热点自动关闭
解决win10移动热点自动关闭
- 16 extern用法、常量字符串的应用
extern声明多文件共享变量的方法总结一下: 1).在一个源文件中定义,在其他需要使用的源文件中用extern声明.(仅一处定义,多处extern) 2).在一个源文件中定义,在其对应的头文件中ex ...
- 如何最大限度提高.NET的性能
优化 .NET的性能 1)避免使用ArrayList. 因为任何对象添加到ArrayList都要封箱为System.Object类型,从ArrayList取出数据时,要拆箱回实际的类型.建议使 ...
- DELPHI 5种运行程序的方法具体应用实例(带参数)
http://www.02t.cn/article/code/102.html https://msdn.microsoft.com/en-us/library/windows/desktop/ms6 ...
- Saiku_学习_01_saiku安装与运行
一.下载saiku 1.下载地址 官网:https://community.meteorite.bi/ 2.解压后文件结构 3.ROOT和saiku 在tomcat/webapp 下有两个web应用, ...
- bootstrap的学习总结
1.bootstrap是一个css框架,它提供了很多类,这些类中实现了内外边距,颜色,大小等样式的封装,它还提供了很多常用插件可以直接使用 2.12栅格本质上是将标签的外边距和内边距通过“格子”的思想 ...
- 基于GUI的简单聊天室02
服务器端 与上一篇相比,加进了线程内部类,解决多个客户端连接时,服务器无法全部响应的问题. 利用List集合来装载客户端的对象. 还需要注意全局变量的应用. /** * 相比01,加进了线程内部类,解 ...
- include指令和include动作有什么区别?
include指令 称为文件加载指令,可以将其他的文件插入jsp网页,被插入的文件必须保证插入后形成的新文件符合jsp页面的语法规则. include指令语法格式:<%@incl ...